深度丨人工智能:拿什么向奇点迫近
转自:果壳
1957年,人工智能(artificial intelligence,AI)的先驱、通用问题求解机(Global Problem Solver)的发明者之一赫伯特·西蒙(Herbert A.Simon)曾说过:“我不是故意让你震惊,但概括来说,现在世界上就已经有了可以思考,可以学习和创造的机器,而且它们的能力还将与日俱增,一直到人类大脑所能够应用到的所有领域。”
西蒙当时曾预言,计算机会在十年之内成为国际象棋冠军。然而现实比西蒙的预测落后了三十年——直到1997年,IBM的电脑“深蓝(Deep Blue)”才战胜了象棋冠军加里·卡斯帕罗夫(Garry Kasparov)。

深蓝与人类象棋大师的对决,堪称人工智能发展史上具有里程碑意义的一幕。图片来源:forbes.com
卷土重来
在人工智能发展早期,学术界和工业界对其前景持有一种过分乐观的态度——这种乐观与其说是对技术的期望过高,倒不如说是当时人们对机器能力的估计实在是过低,以致于当计算机表现出一点点聪明,人们就为之惊叹,而这种惊叹又很容易演化成一种过分的自信。
这样的自信自然无法长久。度过了最初的兴奋后,无论是工业界还是学术界都遭遇了巨大的困难。以机器翻译为例,早期人们以为机器翻译只需要进行字典的对应转换,再加上人为制定的语法规则就能实现;而实际应用时却发现,这样的系统无法应对哪怕稍有复杂的多重语义,也无法针对上下文语境做出恰当的反应,很多理论上能够实现的算法也无法在有限的计算资源上展开。
1973年,英国政府委托数学家詹姆斯·莱特希尔爵士(Sir James Lighthil),对人工智能进行全面评估。结果显示,人工智能无法应对现实世界中存在的“组合爆炸”问题,因此只能实现一些简单的应用。以这份报告为基础,英国政府停止了对AI领域的研究支持。在这之后,人工智能研究陷入了长久的沉寂。
在近半个世纪之后,人工智能领域才又再一次回到人们视线,而这一次,我们拥有的资源与之前可谓不可同日而语——计算资源已经部署在云端,像水和电一样唾手可得;互联网所容纳的信息超过了前人所有的知识储备,现实和虚拟世界也不再泾渭分明。以深度学习为代表的算法发展,也使得机器有能力处理如此庞大的数据。
如果说这些只是理论,那么IBM的超级计算机“沃森(Watson)”在电视节目《危险边缘》(Jeopardy)中战胜人类,获得年度总冠军;Google X的虚拟大脑在没有预先输入的情况下,独立地从Youtube上的1000 万帧图片中学习到了“猫”的概念,就早已不是理论上的可能性,而是真实发生的现实。

虚拟大脑之父吴恩达,旁边电脑上显示的即为人工智能自我总结出的“猫”的样子。图片来源:nytimes.com
第四次工业革命的前夜
尼尔·杰卡布斯坦(Neil Jacobstein)在一次演讲中曾说过这么一句话:“当你站在太空中回望地球,你看不到争吵不停的200多个国家;而当你深入自然奥秘之中,你也看不到界限分明的学科划分。”这句话在一定程度上,可以代表杰卡布斯坦所在的奇点大学(Singularity University)的宗旨。与其说这所大学在教授最前沿的技术,倒不如它在传播最先进的理念。奇点大学专注的不是技术,而是现实世界的改变,这种改变无疑需要一种融合的视角才可能打破我们心智的成见,去实现真正的进步。
这一点对于杰卡布斯坦来说,并不是问题。作为奇点大学的人工智能与机器人项目负责人,他曾在斯坦福研究增强决策系统(augmented decision system),并担任过创新应用人工智能会议主席,同时有着环境科学与分子生物学背景。杰卡布斯坦对于整合也是游刃有余。

尼尔·杰卡布斯坦,奇点大学人工智能项目负责人,美国国防部及NASA顾问。图片来源:youtube.com
在杰卡布斯坦眼中,人工智能的发展同世界的改变一样,需要融合。杰卡布斯坦将AI划分为三个大的领域:机器学习,规则化的知识库,以及对于人类大脑的逆向工程。这三个方面也恰好对应着人工智能的三种主要做法。
机器学习
机器学习主要的目的是使机器拥有学习的能力。举例来说,当我们登录电子邮箱时,遇到一封广告邮件。我们手动将这封邮件标记为广告,并将其归为垃圾邮件。这个动作其实就是在对机器进行指导,在机器学习中,这一过程称之为标注,而机器可以从所有被标注为垃圾的邮件中,发现其共有的模式,并使用这种模式来对未知的邮件进行预测。此外,机器也可以在没有预先输入的情况下,自己进行学习,例如上文提到的Google X虚拟大脑。

机器学习示例。图片来源: yu.he
规则化的知识库
规则化的知识库则为机器提供了推理能力。当超级计算机沃森在《危险边缘》中面对这样一个问题:“When 60 Minutes premiered,this man was U.S . President(当《60分钟》初次上演时,这个人是当时的美国总统)”时,Waston需要使用句法分析之类的技术对句子进行句法分解,然后确定“permiered”的语义后面关联的是一个日期;同时要对“60分钟”进行语义消歧,确定它指代的是某个电视节目而非具体的时间。在进行句法分析后,沃森需要最后根据确定的日期,推断当时在位的美国总统。
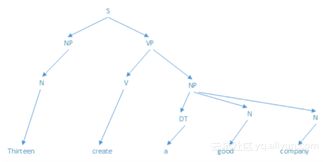
规则化知识库示例。图片来源: yu.he
人脑逆向工程
人脑逆向工程在人工智能领域也被称为联结主义,其主要内容是研究如何模拟人类大脑的神经网络运作——人工智能的发展受神经科学启发颇多,特别是在计算机视觉方面。深度学习算法在图像上对图像特征的表示,与一些生物学上的成果具有惊人的一致性。而如果我们要构建通用人工智能(Artificial GeneralIntelligence,也称强人工智能。即像人类一样,甚至超越人类的智能系统),那么模拟神经网络看起来是最有前景的一条路径。
对人工智能的质疑
然而也有一些有识之士,对人工智能提出了不同的声音。一个有趣的现象是,在这些声音中,无论是对人工智能的发展过度乐观因而认为人工智能终将灭绝人类,还是对人工智能的发展过度悲观认为人工智能根本无法发展出真正的意识,都是围绕着人类的自主意识在做文章。
提到这个问题,就不得不对强AI做更进一步地阐述。当前的人工智能发展,更多是针对某个问题,发展对应的算法和技术,例如图像领域的技术无法直接应用到语言领域;而在这方面,人脑能够表现出比当时的AI更强的适用性。
这就导致许多人对人工智能的前景并不看好,并称之为集邮式的工作方法:我们做出了推理模块,然后拼上学习模块,然后再拼上视觉模块——把每个子领域的功能做好,然后再组合出一个完整的智能系统出来。
强AI正是针对这样的现状。强AI的研究者认为,人类智能不是这样拼起来的,在我们没有理解人类智能的运作方式前,拼合式的做法只是做出了一堆零散的工具。因此他们致力于发展智能的统一框架。强AI可能是每个AI从业者心中的圣杯,无论是Google虚拟大脑之父吴恩达(Andrew Y. Ng)追求的大脑皮层单一算法,还是《人工智能的未来》(On Intelligence)一书的作者杰夫·霍金斯(Jeff Hawkins)所致力研究的脑皮质学习算法(Hierarchical TemporalMemory),无一不是在试图克服这种拼合式的智能,转而追求一个更基础的框架。
除了对做法的质疑之外,还存在着对于机器本性的质疑,哲学家约翰·塞尔(John Rogers Searle)大名鼎鼎的中文屋即是其中代表。塞尔这一思想实验的焦点在于,机器只是机械地执行人们交给他的命令,并没有产生智能。

塞尔假想,将一个美国人放在一个房间中,并给他极为庞大的中英对照辞典,里面有着极为详明的注释,以及丰富的语法规则,然后从房间外面的小窗口塞进中文,这个人去翻辞典,找到对应的汉字形状,将按照说明,将汉字摆在一起递出去。那么问题来了,可以说这个人理解中文么?图片来源:blogspot.com
而斯图尔特·罗素(Stuart Russel)在《人工智能:一种现代方法》(Artificial Intelligence AModern Approach)中举了一个例子来反驳塞尔:我们能够说CPU会开立方根么?众所周知,CPU所能够执行的基本操作,只有加1、减1、存储、移位等等。然而可以说,CPU不能开立方根么?
塞尔的思想实验的问题在于,他混淆了不同的层次(这也是在谈到意识问题时,大部分情况下人们所犯的错误)——我们并不会讨论这个人是否拥有智能,而是说这个房间作为一个“整体”,是拥有智能的。正如我们不会说人类大脑的布罗卡区拥有智能,而是说这个人拥有智能一样,即使布罗卡区在语言的产生中发挥着极重要的作用。
其实人工智能开创者之一的阿兰·图灵(Alan Turing)早在1950年的论文《计算机器与智能》中就给出了意见。而人尽皆知的“图灵测试”之所以提出,最大的原因就在于“智能”这个概念是模糊和易混淆的,我们需要使用行为来定义智能。没有外部可感的行为,空谈大脑中意识的意向性和灵魂,是没有价值的。
而另一方面,将人工智能想象成灭绝人类的邪恶机器人,终有一天要取代人类的想法也由来已久。但是与其考虑人工智会能像电影《黑客帝国》中描述的那样,将人类奴役并毁灭,我更愿意列举每年交通事故的死亡人数,来论证没有什么便利是没有代价的。在一项技术推广前,进行审慎的评估并做好风险控制,才是更应该做的事情。
映照人类自身的一面镜子
正如杰卡布斯坦在一次TED演讲所称,要应对即将到来的人工智能革命,我们需要在数学素养、生态素养,尤其是道德素养上进行不断地自我提升,从而确保当我们手持利器之时,不会对同胞兵刃相见。
人们对人工智能最多的讨论,其实更像是对我们自身的讨论——关于自身的情感,关于自身在宇宙中的地位,关于自己是渺小还是伟大的一种心情。毕竟,用心理学的观点来看,人工智能,这个除了人本身以外最像人的东西,实在是我们心理投射里一个再好不过的客体。
本文来源于"中国人工智能学会",原文发表时间""