大数据和区块链之间的比较分析
大数据和区块链两者之间有个共同的关键词:分布式,代表了一种从技术权威垄断到去中心化的转变。

分布式存储:HDFS vs. 区块
大数据,需要应对海量化和快增长的存储,这要求底层硬件架构和文件系统在性价比上要大大高于传统技术,能够弹性扩张存储容量。谷歌的GFS和Hadoop的HDFS奠定了大数据存储技术的基础。另外,大数据对存储技术提出的另一个挑战是多种数据格式的适应能力,因此现在大数据底层的存储层不只是HDFS,还有HBase和Kudu等存储架构。
区块链,是比特币的底层技术架构,它在本质上是一种去中心化的分布式账本。区块链技术作为一种持续增长的、按序整理成区块的链式数据结构,通过网络中多个节点共同参与数据的计算和记录,并且互相验证其信息的有效性。从这一点来说,区块链技术也是一种特定的数据库技术。由于去中心化数据库在安全、便捷方面的特性,很多业内人士看好其发展,认为它是对现有互联网技术的升级与补充。
分布式计算:MapReduce vs. 共识机制
大数据的分析挖掘是数据密集型计算,需要巨大的分布式计算能力。节点管理、任务调度、容错和高可靠性是关键技术。Google和Hadoop的MapReduce是这种分布式计算技术的代表,通过添加服务器节点可线性扩展系统的总处理能力(Scale Out),在成本和可扩展性上都有巨大的优势。现在,除了批计算,大数据还包括了流计算、图计算、实时计算、交互查询等计算框架。
区块链的共识机制,就是所有分布式节之间怎么达成共识,通过算法来生成和更新数据,去认定一个记录的有效性,这既是认定的手段,也是防止篡改的手段。区块链主要包括四种不同的共识机制,适用于不同的应用场景,在效率和安全性之间取得平衡。以比特币为例,采用的是“工作量证明”(Proof Of Work,简称POW),只有在控制了全网超过51%的记账节点的情况下,才有可能伪造出一条不存在的记录。
IT技术发展的分分合合
和人类社会一样,IT技术发展的也呈现出“合久必分,分久必合”,即集中与分布的螺旋式上升。
计算机诞生初期,仅能实现一对一的使用,是集中化的。为了使得一台大型机能够同时为多个客户提供服务,IBM公司引入了虚拟化的设计思想,使得多个客户在同时使用同一台大型机时,就好像将其分割成了多个小型化的虚拟主机,是时分复用的集中式计算。
进入小型机和PC时代,回归了一对一的使用,不过设备已经分散到了千家万户。进入互联网时代,C/S模型的客户端和服务器是分布式计算,只不过服务器之间还是分散的。
进入云计算时代,计算能力又被统一管控起来,在客户端和服务器的分布式计算基础之上,服务器之间也开始了分布式协同工作。因为协同,所以也可以认为它们在整体上是一种集中式的计算服务。
进入大数据时代,云计算成为大数据基础设施,也使得大数据的核心思想和云计算一脉相承。MapReduce将任务分解进行分布式计算,然后将结果合并从而实现了信息的整合分析。
区块链则是纯粹意义上的分布式系统。
是什么力量造成了集中与分布的此消彼长?
让我们从历史中试着寻找答案。
商业需要集中,希望通过产品实现更好的控制和更高的利润。但随着产品集中度的不断上升,系统会越来越复杂,实现的难度越来越大,沟通、交流和管理的成本也越来越高,最终变得不经济。
社会需要分工,让专业的人做专业的事,涂尔干的《社会分工论》谈到,“分工使社会像有机体一样,每个成员都为社会整体服务,同时又不能脱离整体,分工就像社会的纽带,故谓之‘有机团结’。”
分布式技术的诞生,正是基于这种思想。产品功能被分解并分布到不同的节点上去完成,节点之间通过网络实现沟通。分布式系统中的一些节点或因为商业上的成功,重新成为“集中化”的节点,但随着时代的改变,它们终将会进入新一轮的分布式周期。如此往复。
集中和分布不是光谱的两端,任何伟大的产品,都是商业和技术的“有机团结”。
以上是区块链与大数据之间的一些相同点,接下来聊一聊两者之间的不同点。
两者属于不同的时代,区块链继大数据之后的又一次技术革命。
两个技术处于不同的生命周期
——Gartner Hype Cycle
技术成熟度曲线(The Hype Cycle)是咨询公司Gartner用来分析和预测各种新科技的成熟演变速度及所需时间著名工具。

“大数据”与“区块链”在Gartner历年的《技术成熟度曲线》中的出现情况
2011年,“大数据”第一次上榜,位于技术萌芽期的爬坡阶段,当时还统称为“‘Big Data’ and Extreme Information Processing and Management”(“大数据”和极端信息处理和管理)。2012年更进一步,并在2013年几乎达到了过热期顶峰。经历了2014年的下滑,从2015年开始,“大数据”突然从曲线中消失,可解读为Gartner对大数据的定位已从“新兴”转为“主流”。当前,大数据对于企业的意义已从能力要素上升为战略核心。
相对而言,“区块链”直到2016年才第一次出现在《技术成熟度曲线》中,并直接进入“过热期”。总的来看,“大数据”和“区块链”所处的生命周期阶段大不相同,两者约有5年左右的差距。
主要差异在哪?
大数据通常用来描述数据集足够大,足够复杂,以致很难用传统的方式来处理。而区块链能承载的信息数据是有限的,离“大数据”标准还差得很远。区块链与大数据有几个显著差异:
结构化vs非结构化:区块链是结构定义严谨的块,通过指针组成的链,典型的结构化数据,而大数据需要处理的更多的是非结构化数据;
独立vs整合:区块链系统为保证安全性,信息是相对独立的,而大数据着重的是信息的整合分析;
直接vs间接:区块链系统本身就是一个数据库,而大数据指的是对数据的深度分析和挖掘,是一种间接的数据;
数学vs数据:区块链试图用数学说话,区块链主张“代码即法律”,而大数据试图用数据说话;
匿名vs个性:区块链是匿名的(公开账本,匿名拥有者,相对于传统金融机构的公开账号,账本保密),而大数据有意的是个性化;
差异能否调和?
对一个分布式系统来说,存在CAP定理(CAP theorem)又被称作布鲁尔定理(Brewer's theorem),它指出一个分布式系统不可能同时满足以下三点:
一致性(Consistence):在分布式系统中的所有数据备份,在同一时刻是否同样的值。
可用性(Availability):在集群中一部分节点故障后,集群整体是否还能响应客户端的读写请求。
分区容忍性(Partition tolerance):集群中的某些节点在无法联系后,集群整体是否还能继续进行服务。
由于当前的网络硬件肯定会出现延迟丢包等问题,所以分区容忍性是我们必须需要实现的。换句话说,CAP定理表明我们必须在一致性(C)和可用性(A)之间进行权衡。
具体到区块链和大数据来说,大数据是以牺牲一致性(C)来换取可用性(A)和分区容忍性(P)的,而区块链却优先保证了一致性(C)。
可相互借鉴之处
通过CAP定理,我们知道区块链和大数据的诸多特性无法两全,需要针对具体场景,在多样化的取舍方案下设计出多样化的系统。
区块链+大数据:在区块链中使用大数据技术
区块链是一种不可篡改的、全历史的分布式数据库存储技术,巨大的区块链数据集合包含着每一笔交易的全部历史,随着区块链技术的应用迅速发展,数据规模会越来越大,不同业务场景区块链的数据融合会进一步扩大数据规模和丰富性。
区块链以其可信任性、安全性和不可篡改性,让更多数据被解放出来,推进数据的海量增长。区块链的可追溯性使得数据从采集、交易、流通,以及计算分析的每一步记录都可以留存在区块链上,使得数据的质量获得前所未有的强信任背书,也保证了数据分析结果的正确性和数据挖掘的效果。
区块链能够进一步规范数据的使用,精细化授权范围。脱敏后的数据交易流通,则有利于突破信息孤岛,建立数据横向流通机制,形成“社会化大数据”。基于区块链的价值转移网络,逐步推动形成基于全球化的数据交易场景。
区块链提供的是账本的完整性,数据统计分析的能力较弱。大数据则具备海量数据存储技术和灵活高效的分析技术,极大提升区块链数据的价值和使用空间。
大数据+区块链:在大数据中使用区块链技术
大数据的技术生态百花齐放,没有哪个软件能解决所有的问题,能解决问题也是在一个范围内,即使是Spark、Flink等。在强调透明性、安全性的场景下,区块链有其用武之地。在大数据的系统上使用区块链技术,可以使得数据不能被随意添加、修改和删除,当然其时间和数据量级是有限度的。
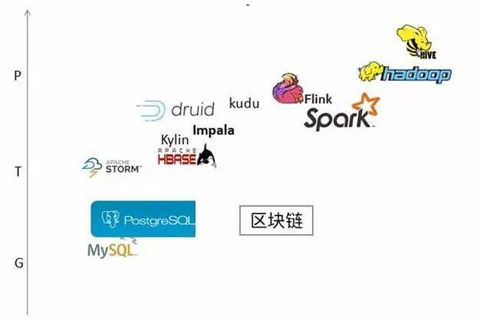
以时间、数据量为坐标轴,列出了目前大数据引擎大致擅长处理数据的范围,区块链可在其中成为一种很好的补充
比如,对于存档的历史数据,因为它们是不能被修改的,我们可以对大数据作Hash处理,并加上时间戳,存在区块链之上。在未来的某一时刻,当我们需要验证原始数据地真实性时,可以对对应的数据做同样的Hash处理,如果得出的答案是相同的,则说明数据是没有被篡改过的。或者,只对汇总数据和结果做处理,这样,只需要处理增量数据处理,那么应对的数据量级和吞吐量级可能是今天的区块链或改善过的系统可以处理的。
通过把大数据与区块链相结合,能让区块链中的数据更有价值,也能让大数据的预测分析落实为行动,它们都将是数字经济时代的基石。
本文作者:佚名
来源:51CTO