Kafka配合Spark Streaming是大数据领域常见的黄金搭档之一,主要是用于数据实时入库或分析。
为了应对可能出现的引起Streaming程序崩溃的异常情况,我们一般都需要手动管理好Kafka的offset,而不是让它自动提交,即需要将enable.auto.commit设为false。只有管理好offset,才能使整个流式系统最大限度地接近exactly once语义。
管理offset的流程
下面这张图能够简要地说明管理offset的大致流程。
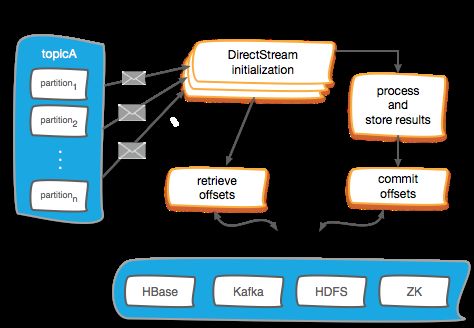
- 在Kafka DirectStream初始化时,取得当前所有partition的存量offset,以让DirectStream能够从正确的位置开始读取数据。
- 读取消息数据,处理并存储结果。
- 提交offset,并将其持久化在可靠的外部存储中。
图中的“process and store results”及“commit offsets”两项,都可以施加更强的限制,比如存储结果时保证幂等性,或者提交offset时采用原子操作。
图中提出了4种offset存储的选项,分别是HBase、Kafka自身、HDFS和ZooKeeper。综合考虑实现的难易度和效率,我们目前采用过的是Kafka自身与ZooKeeper两种方案。
Kafka自身
在Kafka 0.10+版本中,offset的默认存储由ZooKeeper移动到了一个自带的topic中,名为__consumer_offsets。Spark Streaming也专门提供了commitAsync() API用于提交offset。使用方法如下。
stream.foreachRDD { rdd =>
val offsetRanges = rdd.asInstanceOf[HasOffsetRanges].offsetRanges
// 确保结果都已经正确且幂等地输出了
stream.asInstanceOf[CanCommitOffsets].commitAsync(offsetRanges)
}
上面是Spark Streaming官方文档中给出的写法。但在实际上我们总会对DStream进行一些运算,这时我们可以借助DStream的transform()算子。
var offsetRanges: Array[OffsetRange] = Array.empty[OffsetRange]
stream.transform(rdd => {
// 利用transform取得OffsetRanges
offsetRanges = rdd.asInstanceOf[HasOffsetRanges].offsetRanges
rdd
}).mapPartitions(records => {
var result = new ListBuffer[...]()
// 处理流程
result.toList.iterator
}).foreachRDD(rdd => {
if (!rdd.isEmpty()) {
// 数据入库
session.createDataFrame...
}
// 提交offset
stream.asInstanceOf[CanCommitOffsets].commitAsync(offsetRanges)
})
特别需要注意,在转换过程中不能破坏RDD分区与Kafka分区之间的映射关系。亦即像map()/mapPartitions()这样的算子是安全的,而会引起shuffle或者repartition的算子,如reduceByKey()/join()/coalesce()等等都是不安全的。
另外需要注意的是,HasOffsetRanges是KafkaRDD的一个trait,而CanCommitOffsets是DirectKafkaInputDStream的一个trait。从spark-streaming-kafka包的源码中,可以看得一清二楚。
private[spark] class KafkaRDD[K, V](
sc: SparkContext,
val kafkaParams: ju.Map[String, Object],
val offsetRanges: Array[OffsetRange],
val preferredHosts: ju.Map[TopicPartition, String],
useConsumerCache: Boolean
) extends RDD[ConsumerRecord[K, V]](sc, Nil) with Logging with HasOffsetRanges
private[spark] class DirectKafkaInputDStream[K, V](
_ssc: StreamingContext,
locationStrategy: LocationStrategy,
consumerStrategy: ConsumerStrategy[K, V],
ppc: PerPartitionConfig
) extends InputDStream[ConsumerRecord[K, V]](_ssc) with Logging with CanCommitOffsets {
这就意味着不能对stream对象做transformation操作之后的结果进行强制转换(会直接报ClassCastException),因为RDD与DStream的类型都改变了。只有RDD或DStream的包含类型为ConsumerRecord才行。
ZooKeeper
虽然Kafka将offset从ZooKeeper中移走是考虑到可能的性能问题,但ZooKeeper内部是采用树形node结构存储的,这使得它天生适合存储像offset这样细碎的结构化数据。并且我们的分区数不是很多,batch间隔也相对长(20秒),因此并没有什么瓶颈。
Kafka中还保留了一个已经标记为过时的类ZKGroupTopicDirs,其中预先指定了Kafka相关数据的存储路径,借助它,我们可以方便地用ZooKeeper来管理offset。为了方便调用,将存取offset的逻辑封装成一个类如下。
class ZkKafkaOffsetManager(zkUrl: String) {
private val logger = LoggerFactory.getLogger(classOf[ZkKafkaOffsetManager])
private val zkClientAndConn = ZkUtils.createZkClientAndConnection(zkUrl, 30000, 30000);
private val zkUtils = new ZkUtils(zkClientAndConn._1, zkClientAndConn._2, false)
def readOffsets(topics: Seq[String], groupId: String): Map[TopicPartition, Long] = {
val offsets = mutable.HashMap.empty[TopicPartition, Long]
val partitionsForTopics = zkUtils.getPartitionsForTopics(topics)
// /consumers//offsets//
partitionsForTopics.foreach(partitions => {
val topic = partitions._1
val groupTopicDirs = new ZKGroupTopicDirs(groupId, topic)
partitions._2.foreach(partition => {
val path = groupTopicDirs.consumerOffsetDir + "/" + partition
try {
val data = zkUtils.readData(path)
if (data != null) {
offsets.put(new TopicPartition(topic, partition), data._1.toLong)
logger.info(
"Read offset - topic={}, partition={}, offset={}, path={}",
Seq[AnyRef](topic, partition.toString, data._1, path)
)
}
} catch {
case ex: Exception =>
offsets.put(new TopicPartition(topic, partition), 0L)
logger.info(
"Read offset - not exist: {}, topic={}, partition={}, path={}",
Seq[AnyRef](ex.getMessage, topic, partition.toString, path)
)
}
})
})
offsets.toMap
}
def saveOffsets(offsetRanges: Seq[OffsetRange], groupId: String): Unit = {
offsetRanges.foreach(range => {
val groupTopicDirs = new ZKGroupTopicDirs(groupId, range.topic)
val path = groupTopicDirs.consumerOffsetDir + "/" + range.partition
zkUtils.updatePersistentPath(path, range.untilOffset.toString)
logger.info(
"Save offset - topic={}, partition={}, offset={}, path={}",
Seq[AnyRef](range.topic, range.partition.toString, range.untilOffset.toString, path)
)
})
}
}
这样,offset就会被存储在ZK的/consumers/[groupId]/offsets/[topic]/[partition]路径下。当初始化DirectStream时,调用readOffsets()方法获得offset。当数据处理完成后,调用saveOffsets()方法来更新ZK中的值。
为什么不用checkpoint
Spark Streaming的checkpoint机制无疑是用起来最简单的,checkpoint数据存储在HDFS中,如果Streaming应用挂掉,可以快速恢复。
但是,如果Streaming程序的代码改变了,重新打包执行就会出现反序列化异常的问题。这是因为checkpoint首次持久化时会将整个jar包序列化,以便重启时恢复。重新打包之后,新旧代码逻辑不同,就会报错或者仍然执行旧版代码。
要解决这个问题,只能将HDFS上的checkpoint文件删掉,但这样也会同时删掉Kafka的offset信息,就毫无意义了。