Google Colab使用笔记之VGG模型在cifar10数据集下的深度学习训练(持续更新中)
参考文章:
https://blog.csdn.net/zzk1995/article/details/54292859
https://blog.csdn.net/wsLJQian/article/details/78411044
https://blog.csdn.net/u010899985/article/details/81836299
https://cloud.tencent.com/developer/article/1406390
colab
Google Colab是谷歌为人工智能开发者提供的免费云服务。使用Colab(需), 可以免费在 GPU 上开发深度学习应用程序。首先注册一个谷歌账号,点击链接https://drive.google.com/drive/进入谷歌云盘,上传数据和本地模块,colab使用时需挂载云盘。
数据准备
cifar10的数据集的下载地址:http://www.cs.toronto.edu/~kriz/cifar.html

TFRecord格式的文件存储形式会很合理的帮我们存储数据,其内部使用了二进制数据编码方案,只需要一次性加载一个二进制文件的方式即可,所以这里选择下载CIFAR-10 binary version (suitable for C programs)文件
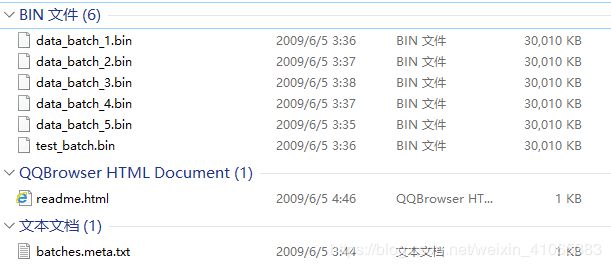
下载的文件如上:其中[‘data_batch_%d.bin’ %num for num in range(1, 6)]是训练集,一共有5个训练集;test_batch.bin为测试集
VGG模型
VGGNet在AlexNet的基础上探索了卷积神经网络的深度与性能之间的关系,通过反复堆叠3 * 3的小型卷积核和2 * 2的最大池化层,VGGNet构筑的16~19层卷积神经网络模型取得了很好的识别性能,同时VGGNet的拓展性很强,迁移到其他图片数据上泛化能力很好,而且VGGNet结构简洁,现在依然被用来提取图像特征。
(1)网络结构
- 全部使用3 * 3的卷积核和2 * 2的池化核,通过不断加深网络结构来提升性能;
- 使用多个小卷积核串联组成卷积层,和大卷积核对比,拥有相同的感受野,却有着更少的参数,更强的非线性变换,因此拥有更强的特征提取能力;
(2)数据增强
- Multi-Scale:将原始图像缩放到不同的尺寸S,在随机截取固定大小的图片
(3)可以先训练A网络,再复用A的权重初始化后面几个复杂模型,提高速度
VGG根据深度的不同有以下结构:
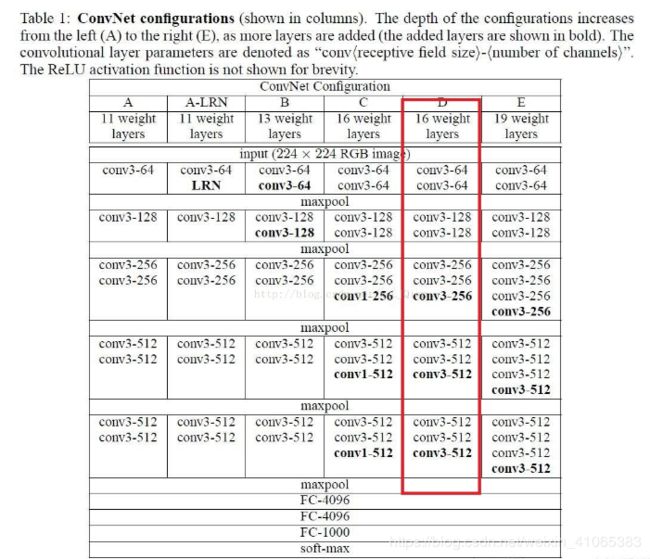
下面对CIFAR10的数据集进行训练,采用D结构(VGG16,13个卷积层+3个全连接层),定义于VGG.py中
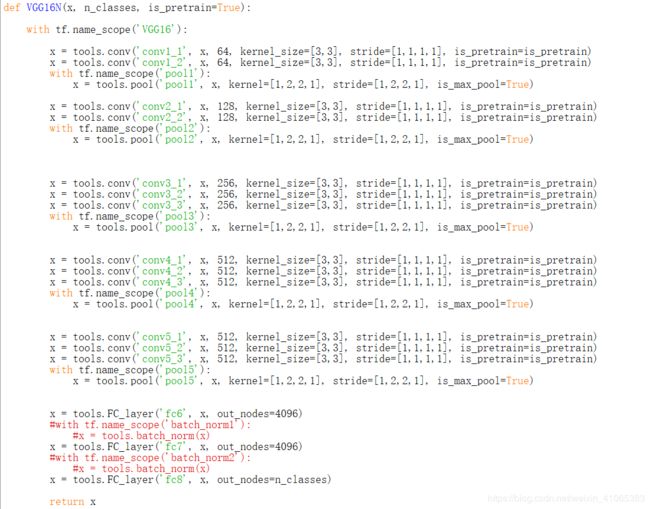
其中卷积部分的kernel_size=[3,3].池化部分的kernel_size=[2,2],完全符合上面提到的内容。三个FC全连接层,其中在第三个全连接层部分,输出的节点(nodes)=n_classes(类别数)
代码部分(辅助模块)
input_data.py
读取二进制数据,返回Tensor(images(batch_size,32,32,3), label_batch (batch_size,1) )
| 函数 | 简介 |
|---|---|
| tf.train.string_input_producer | 传入文件名组成的list,转化为一个tf内部的queue |
| tf.FixedLengthRecordReader() | 创建一个reader实例,可用于读取bin文件,record_bytes=label长度+image长度(打平后) |
| tf.FixedLengthRecordReader().read() | reader对象从文件名列表中读取数据 |
| tf.decode_raw() | 将字符串类型的二进制格式的Tensor转换为数值型Tensor |
| tf.slice() | 切分Tensor |
| tf.cast() | Tensor数据类型的转变 |
| tf.image.per_image_standardization() | 图片标准化函数 |
| tf.train.shuffle_batch() | 把一个一个小样本的tensor以乱序打包成一个高一维度的样本batch,输入是单个样本,输出就是4D的样本batch |
| tf.one_hot() | 将input转化为one-hot类型数据输出,用于多分类任务 |
| tf.reshape() | 将tensor变换为参数shape的形式(该函数可防止array1vector的情况) |
import tensorflow as tf
import numpy as np
import os
import warnings
warnings.filterwarnings("ignore")
#%% Reading data
# Reference:https://blog.csdn.net/zzk1995/article/details/54292859
def read_cifar10(data_dir, is_train, batch_size, shuffle):
"""Read CIFAR10
Args:
data_dir: the directory of CIFAR10
is_train: boolen
batch_size:
shuffle:
Returns:
label: 1D tensor, tf.int32
image: 4D tensor, [batch_size, height, width, 3], tf.float32
"""
img_width = 32
img_height = 32
img_depth = 3
label_bytes = 1
image_bytes = img_width*img_height*img_depth
with tf.name_scope('input'):
if is_train:
filenames = [os.path.join(data_dir, 'data_batch_%d.bin' %ii)
for ii in np.arange(1, 6)] #
else:
filenames = [os.path.join(data_dir, 'test_batch.bin')]
filename_queue = tf.train.string_input_producer(filenames) # files to tf.queue
reader = tf.FixedLengthRecordReader(label_bytes + image_bytes) # bin reader
key, value = reader.read(filename_queue) # tensor
record_bytes = tf.decode_raw(value, tf.uint8) # value(label,image) decode
label = tf.slice(record_bytes, [0], [label_bytes])
label = tf.cast(label, tf.int32) # label( 1 ,1)
image_raw = tf.slice(record_bytes, [label_bytes], [image_bytes])
image_raw = tf.reshape(image_raw, [img_depth, img_height, img_width])
image = tf.transpose(image_raw, (1,2,0)) # convert from D/H/W to H/W/D
image = tf.cast(image, tf.float32) # image(1,32,32,3 )
# # data argumentation (optional)
# image = tf.random_crop(image, [24, 24, 3])# randomly crop the image size to 24 x 24
# image = tf.image.random_flip_left_right(image)
# image = tf.image.random_brightness(image, max_delta=63)
# image = tf.image.random_contrast(image,lower=0.2,upper=1.8)
image = tf.image.per_image_standardization(image) #substract off the mean and divide by the variance
if shuffle:
images, label_batch = tf.train.shuffle_batch(
[image, label],
batch_size = batch_size,
num_threads= 64,
capacity = 20000,
min_after_dequeue = 3000) # images(batch_size,32,32,3) label_batch(batch_size,1)
else:
images, label_batch = tf.train.batch(
[image, label],
batch_size = batch_size,
num_threads = 64,
capacity= 2000)
## ONE-HOT
n_classes = 10
label_batch = tf.one_hot(label_batch, depth= n_classes) # label_batch(batch_size,10)
label_batch = tf.cast(label_batch, dtype=tf.int32)
label_batch = tf.reshape(label_batch, [batch_size, n_classes])
return images, label_batch # Tensor
if __name__=="__main__":
path='/content/gdrive/My Drive/CIFAR10_VGG/cifar-10-batches-bin'
train_images, train_label_batch=read_cifar10(path, 1, 10, 1)
print(train_images, train_label_batch)
tools.py
conv
构建卷积层,输入Tensor,返回卷积并激活后的Tensor
| 函数 | 功能 |
|---|---|
| Tensor.get_shape() | 获取Tensor的形状,返回元祖 |
| tf.get_variable(name, shape,initializer) | 创建或返回给定名称的变量,当tf.get_variable_scope().reuse == False,调用该函数会创建新的变量 ;True,调用该函数会重用已经创建的变量 |
| tf.variable_scope(scope_name) | 管理传给get_variable()的变量名称的作用域,作为变量名的前缀,支持嵌套 |
| tf.nn.conv2d() | 输入input_tensor和filters_variables ,窗口移动步长,进行卷积操作,返回卷积后的Tensor,padding=‘SAME’使用0填充边界,使卷积操作不改变Tensor的宽度和高度 |
| tf.nn.bias_add() | 加偏置项,支持广播 |
| tf.nn.relu() | 线性整流激活函数 |
pool
构建池化层,返回池化后的Tensor
| 函数 | 功能 |
|---|---|
| tf.nn.max_pool | 最大池化 |
| tf.nn.avg_pool | 平均池化 |
batch_norm
批量标准化,解决收敛速度慢和梯度爆炸
| 函数 | 功能 |
|---|---|
| tf.nn.moments( ) | 计算Tensor的均值和方差,axes=[0] |
| tf.nn.batch_normalization | 批量标准化 |
FC_layer
全连接层,需要把前面卷积操作后的输出Tensor打平
loss
评估label和predicts之间的差距(交叉熵)
| 函数 | 功能 |
|---|---|
| tf.name_scope() | 一般结合 tf.Variable() 来使用,方便参数命名管理 |
| tf.nn.softmax_cross_entropy_with_logits() | 计算labels和logits之间的交叉熵(cross entropy),返回一维Tensor,表示batch每个样本的交叉熵 |
| tf.nn.sparse_softmax_cross_entropy_with_logits() | tf自动将原来的类别索引转换成one_hot形式,然后与label表示的one_hot向量比较,计算交叉熵 |
| tf.reduce_mean | 计算张量tensor沿着指定的数轴(tensor的某一维度)上的平均值 |
| tf.summary.scalar | 用来显示标量信息 |
注意:
(1)tensorflow交叉熵计算函数输入中的logits都不是softmax或sigmoid的输出,而是softmax或sigmoid函数的输入,因为它在函数内部进行sigmoid或softmax操作
(2)如果labels的每一行是one-hot表示,也就是只有一个地方为1(或者说100%),其他地方为0(或者说0%),还可以使用tf.sparse_softmax_cross_entropy_with_logits()。之所以用100%和0%描述,就是让它看起来像一个概率分布。
(3)tf.nn.softmax_cross_entropy_with_logits()函数已经过时 (deprecated),它在TensorFlow未来的版本中将被去除。取而代之的是tf.nn.softmax_cross_entropy_with_logits_v2()。
(4)参数labels,logits必须有相同的形状 [batch_size, num_classes] 和相同的类型(float16, float32, float64)中的一种,否则交叉熵无法计算。
(5)tf.nn.softmax_cross_entropy_with_logits 函数内部的 logits 不能进行缩放,因为在这个工作会在该函数内部进行(注意函数名称中的 softmax ,它负责完成原始数据的归一化),如果 logits 进行了缩放,那么反而会影响计算正确性。
accuracy
返回模型准确率
| 函数 | 功能 |
|---|---|
| tf.equal() | 对两个相同形状的Tensor进行逐元素对比,返回元素为bool的Tensor |
| tf.argmax() | numpy.argmax() 方法的用法是一致,返回沿轴axis(设置为1)最大值的索引 |
num_correct_prediction
返回模型判断准确的个数
optimize
| 函数 | 功能 |
|---|---|
| tf.train.GradientDescentOptimizer() | 返回随机梯度下降SGD优化器 |
| tf.train.MomentumOptimizer() | momentum,更新的时候在一定程度上保留之前更新的方向,同时利用 当前batch的梯度 微调最终的更新方向 |
| tf.train.AdagradOptimizer() | AdaGrad,学习速率自适应,在训练迭代过程,其学习速率是逐渐衰减的,经常更新的参数其学习速率衰减更快 |
| tf.train.AdadeltaOptimizer() | Adadelta,对Adagrad的扩展,最初方案依然是对学习率进行自适应约束,但是进行了计算上的简化 |
| tf.train.RMSPropOptimizer() | RMSProp,Adagrad的一种发展,和Adadelta的变体,效果趋于二者之间 ,避免了学习速率过快衰减 |
| tf.train.AdamOptimizer() | Adam,带有动量项的RMSprop |
tips:
- 对于稀疏数据,优先选择学习速率自适应的算法如RMSprop和Adam算法,而且最好采用默认值,大部分情况下其效果是较好的
- SGD通常训练时间更长,容易陷入鞍点,但是在好的初始化和学习率调度方案的情况下,结果更可靠。
- 如果要求更快的收敛,并且较深较复杂的网络时,推荐使用学习率自适应的优化方法。例如对于RNN之类的网络结构,Adam速度快,效果好,而对于CNN之类的网络结构,SGD +momentum 的更新方法要更好(常见国际顶尖期刊常见优化方法).
- Adadelta,RMSprop,Adam是比较相近的算法,在相似的情况下表现差不多,在想使用带动量的RMSprop,或者Adam的地方,大多可以使用adam取得更好的效果。
- 特别注意学习速率的问题。学习速率设置得非常大,那么训练可能不会收敛,就直接发散了;如果设置的比较小,虽然可以收敛,但是训练时间可能无法接受。理想的学习速率是:刚开始设置较大,有很快的收敛速度,然后慢慢衰减,保证稳定到达最优
- 其实还有很多方面会影响梯度下降算法,如梯度的消失与爆炸
load,test_load,load_with_skip
迁移学习,加载本地VGG模型的.npy文件
| 函数 | 功能 |
|---|---|
| np.load() | 在使用训练好的模型时(迁移学习),其中有一种保存的模型文件格式叫.npy,参数设为encoding = "latin1"加载文件 |
| dict.items() | items() 方法以列表返回可遍历的(键, 值) 元组数组 |
| zip() | 将可迭代的对象作为参数,将对象中对应的元素打包成一个个元组,然后返回由这些元组组成的列表对象;如果各个迭代器的元素个数不一致,则返回列表长度与最短的对象相同,利用 * 号操作符,可以将元组解压为列表 |
注:模型文件(.npy)部分内容如下:由一个字典组成,字典中的每一个键对应一层网络模型参数。(包括权重w和偏置b)举例说明:
data_dict = {'conv1':[array([[13,52],[38,49]],dtype=float32),array([50,64],dtype=float32)],
'conv2':[array([[70,90],[32,46]],dtype=float32),array([90,100],dtype=float32)]}
key为层的名称,对应的value为一个列表,第一个元素为权重array,第二个元素为bias的array
weights对应data_dict[laye_name][0],weights对应data_dict[laye_name][1]
print_all_variables
打印所有变量,
| 函数 | 功能 |
|---|---|
| tf.global_variables() | 获取计算图中的变量,返回的值是变量的一个对象列表,对象的name属性为变量名称及其数值 |
weight
自定义变量
bias
自定义bias
import tensorflow as tf
import numpy as np
#%%
def conv(layer_name, x, out_channels, kernel_size=[3,3], stride=[1,1,1,1], is_pretrain=True): # Conv
'''Convolution op wrapper, use RELU activation after convolution
Args:
layer_name: e.g. conv1, pool1...
x: input tensor, [batch_size, height, width, channels]
out_channels: number of output channels (or comvolutional kernels)
kernel_size: the size of convolutional kernel, VGG paper used: [3,3]
stride: A list of ints. 1-D of length 4. VGG paper used: [1, 1, 1, 1]
is_pretrain: if load pretrained parameters, freeze all conv layers.
Depending on different situations, you can just set part of conv layers to be freezed.
the parameters of freezed layers will not change when training.
Returns:
4D tensor
'''
in_channels = x.get_shape()[-1]
with tf.variable_scope(layer_name):
w = tf.get_variable(name='weights',
trainable=is_pretrain,
shape=[kernel_size[0], kernel_size[1], in_channels, out_channels],
initializer=tf.contrib.layers.xavier_initializer()) # default is uniform distribution initialization
b = tf.get_variable(name='biases',
trainable=is_pretrain,
shape=[out_channels],
initializer=tf.constant_initializer(0.0))
x = tf.nn.conv2d(x, w, stride, padding='SAME', name='conv')
x = tf.nn.bias_add(x, b, name='bias_add')
x = tf.nn.relu(x, name='relu')
return x
#%%
def pool(layer_name, x, kernel=[1,2,2,1], stride=[1,2,2,1], is_max_pool=True): # Maxpool
'''Pooling op
Args:
x: input tensor
kernel: pooling kernel, VGG paper used [1,2,2,1], the size of kernel is 2X2
stride: stride size, VGG paper used [1,2,2,1]
padding:
is_max_pool: boolen
if True: use max pooling
else: use avg pooling
'''
if is_max_pool:
x = tf.nn.max_pool(x, kernel, strides=stride, padding='SAME', name=layer_name)
else:
x = tf.nn.avg_pool(x, kernel, strides=stride, padding='SAME', name=layer_name)
return x
#%%
def batch_norm(x):
'''Batch normlization(I didn't include the offset and scale)
'''
epsilon = 1e-3
batch_mean, batch_var = tf.nn.moments(x, [0])
x = tf.nn.batch_normalization(x,
mean=batch_mean,
variance=batch_var,
offset=None,
scale=None,
variance_epsilon=epsilon)
return x
#%%
def FC_layer(layer_name, x, out_nodes): # FC
'''Wrapper for fully connected layers with RELU activation as default
Args:
layer_name: e.g. 'FC1', 'FC2'
x: input feature map
out_nodes: number of neurons for current FC layer
'''
shape = x.get_shape()
if len(shape) == 4:
size = shape[1].value * shape[2].value * shape[3].value
else:
size = shape[-1].value
with tf.variable_scope(layer_name):
w = tf.get_variable('weights',
shape=[size, out_nodes],
initializer=tf.contrib.layers.xavier_initializer())
b = tf.get_variable('biases',
shape=[out_nodes],
initializer=tf.constant_initializer(0.0))
flat_x = tf.reshape(x, [-1, size]) # flatten into 1D
x = tf.nn.bias_add(tf.matmul(flat_x, w), b)
x = tf.nn.relu(x)
return x
#%%
def loss(logits, labels): # loss_function
'''Compute loss
Args:
logits: logits tensor, [batch_size, n_classes]
labels: one-hot labels
'''
with tf.name_scope('loss') as scope:
cross_entropy = tf.nn.softmax_cross_entropy_with_logits(logits=logits, labels=labels,name='cross-entropy')
loss = tf.reduce_mean(cross_entropy, name='loss')
tf.summary.scalar(scope+'/loss', loss)
return loss
#%%
def accuracy(logits, labels): # accuracy
"""Evaluate the quality of the logits at predicting the label.
Args:
logits: Logits tensor, float - [batch_size, NUM_CLASSES].
labels: Labels tensor,
"""
with tf.name_scope('accuracy') as scope:
correct = tf.equal(tf.arg_max(logits, 1), tf.arg_max(labels, 1))
correct = tf.cast(correct, tf.float32)
accuracy = tf.reduce_mean(correct)*100.0
tf.summary.scalar(scope+'/accuracy', accuracy)
return accuracy
#%%
def num_correct_prediction(logits, labels): # num of correct
"""Evaluate the quality of the logits at predicting the label.
Return:
the number of correct predictions
"""
correct = tf.equal(tf.arg_max(logits, 1), tf.arg_max(labels, 1))
correct = tf.cast(correct, tf.int32)
n_correct = tf.reduce_sum(correct)
return n_correct
#%%
def optimize(loss, learning_rate, global_step): # optimizer
'''optimization, use Gradient Descent as default
'''
with tf.name_scope('optimizer'):
optimizer = tf.train.GradientDescentOptimizer(learning_rate=learning_rate)
# optimizer = tf.train.AdamOptimizer(learning_rate=learning_rate)
train_op = optimizer.minimize(loss, global_step=global_step)
return train_op
#%%
def load(data_path, session): # 全部使用VGG16中的参数
data_dict = np.load(data_path, encoding='latin1').item()
keys = sorted(data_dict.keys())
for key in keys:
with tf.variable_scope(key, reuse=True):
for subkey, data in zip(('weights', 'biases'), data_dict[key]):
# weights对应data_dict[laye_name][0],weights对应data_dict[laye_name][1]
session.run(tf.get_variable(subkey).assign(data))
# 将.npy中的权重和偏置初始化自己网络中的参数
#%% 取出网络的各层的结构形式
def test_load(): # 查看VGG16参数
data_path = '/content/gdrive/My Drive/CIFAR10_VGG/vgg16.npy'
data_dict = np.load(data_path, encoding='latin1').item()
keys = sorted(data_dict.keys())
for key in keys:
weights = data_dict[key][0]
biases = data_dict[key][1]
print('\n')
print(key)
print('weights shape: ', weights.shape)
print('biases shape: ', biases.shape)
#%% 对skip_layer 层不引用VGG16的参数,自己训练
def load_with_skip(data_path, session, skip_layer):
data_dict = np.load(data_path, encoding='latin1').item()
for key in data_dict:
if key not in skip_layer:
with tf.variable_scope(key, reuse=True):
for subkey, data in zip(('weights', 'biases'), data_dict[key]):
session.run(tf.get_variable(subkey).assign(data))
#%%
def print_all_variables(train_only=True):
"""Print all trainable and non-trainable variables
without tl.layers.initialize_global_variables(sess)
Parameters
----------
train_only : boolean
If True, only print the trainable variables, otherwise, print all variables.
"""
# tvar = tf.trainable_variables() if train_only else tf.all_variables()
if train_only:
t_vars = tf.trainable_variables()
print(" [*] printing trainable variables")
else:
try: # TF1.0
t_vars = tf.global_variables()
except: # TF0.12
t_vars = tf.all_variables()
print(" [*] printing global variables")
for idx, v in enumerate(t_vars):
print(" var {:3}: {:15} {}".format(idx, str(v.get_shape()), v.name))
#%%
def weight(kernel_shape, is_uniform = True):
''' weight initializer
Args:
shape: the shape of weight
is_uniform: boolen type.
if True: use uniform distribution initializer
if False: use normal distribution initizalizer
Returns:
weight tensor
'''
w = tf.get_variable(name='weights',
shape=kernel_shape,
initializer=tf.contrib.layers.xavier_initializer())
return w
#%%
def bias(bias_shape):
'''bias initializer
'''
b = tf.get_variable(name='biases',
shape=bias_shape,
initializer=tf.constant_initializer(0.0))
return b
#%%
VGG.py
VGG网络结构,与上面说的D结构一样
import tensorflow as tf
import tools
#%% TO get better tensorboard figures!
def VGG16N(x, n_classes, is_pretrain=True):
with tf.name_scope('VGG16'):
x = tools.conv('conv1_1', x, 64, kernel_size=[3,3], stride=[1,1,1,1], is_pretrain=is_pretrain)
x = tools.conv('conv1_2', x, 64, kernel_size=[3,3], stride=[1,1,1,1], is_pretrain=is_pretrain)
with tf.name_scope('pool1'):
x = tools.pool('pool1', x, kernel=[1,2,2,1], stride=[1,2,2,1], is_max_pool=True)
x = tools.conv('conv2_1', x, 128, kernel_size=[3,3], stride=[1,1,1,1], is_pretrain=is_pretrain)
x = tools.conv('conv2_2', x, 128, kernel_size=[3,3], stride=[1,1,1,1], is_pretrain=is_pretrain)
with tf.name_scope('pool2'):
x = tools.pool('pool2', x, kernel=[1,2,2,1], stride=[1,2,2,1], is_max_pool=True)
x = tools.conv('conv3_1', x, 256, kernel_size=[3,3], stride=[1,1,1,1], is_pretrain=is_pretrain)
x = tools.conv('conv3_2', x, 256, kernel_size=[3,3], stride=[1,1,1,1], is_pretrain=is_pretrain)
x = tools.conv('conv3_3', x, 256, kernel_size=[3,3], stride=[1,1,1,1], is_pretrain=is_pretrain)
with tf.name_scope('pool3'):
x = tools.pool('pool3', x, kernel=[1,2,2,1], stride=[1,2,2,1], is_max_pool=True)
x = tools.conv('conv4_1', x, 512, kernel_size=[3,3], stride=[1,1,1,1], is_pretrain=is_pretrain)
x = tools.conv('conv4_2', x, 512, kernel_size=[3,3], stride=[1,1,1,1], is_pretrain=is_pretrain)
x = tools.conv('conv4_3', x, 512, kernel_size=[3,3], stride=[1,1,1,1], is_pretrain=is_pretrain)
with tf.name_scope('pool4'):
x = tools.pool('pool4', x, kernel=[1,2,2,1], stride=[1,2,2,1], is_max_pool=True)
x = tools.conv('conv5_1', x, 512, kernel_size=[3,3], stride=[1,1,1,1], is_pretrain=is_pretrain)
x = tools.conv('conv5_2', x, 512, kernel_size=[3,3], stride=[1,1,1,1], is_pretrain=is_pretrain)
x = tools.conv('conv5_3', x, 512, kernel_size=[3,3], stride=[1,1,1,1], is_pretrain=is_pretrain)
with tf.name_scope('pool5'):
x = tools.pool('pool5', x, kernel=[1,2,2,1], stride=[1,2,2,1], is_max_pool=True)
x = tools.FC_layer('fc6', x, out_nodes=4096)
#with tf.name_scope('batch_norm1'):
#x = tools.batch_norm(x)
x = tools.FC_layer('fc7', x, out_nodes=4096)
#with tf.name_scope('batch_norm2'):
#x = tools.batch_norm(x)
x = tools.FC_layer('fc8', x, out_nodes=n_classes)
return x
#%%
在colab上进行训练和验证
1.登录谷歌云盘,上传数据集文件夹,三个py模块,以及预训练的VGG16.npy文件
2.打开colaboratory,创建train_and_val.ipynb,使用前需挂载
from google.colab import drive
drive.mount("/content/gdrive")
!pip install numpy==1.16.2 # colab上的numpy1.16.3使用会报错
import os
os.kill(os.getpid(), 9) # 重启kernal
import numpy as np
print(np.__version__)
切换工作目录,用于导入本地模块input_data.py,tools. py 和VGG. py
import os
path = "/content/gdrive/My Drive/CIFAR10_VGG/"
os.chdir(path)
os.listdir(path)
训练前的参数设定
import os
import os.path
import numpy as np
import tensorflow as tf
import input_data
import VGG
import tools
tf.reset_default_graph() # 重置图
#%%
IMG_W = 32
IMG_H = 32
N_CLASSES = 10
BATCH_SIZE = 128
learning_rate = 0.0001
MAX_STEP = 10000 # it took me about one hour to complete the training.
IS_PRETRAIN = True
训练函数
| 函数 | 功能 |
|---|---|
| tf.train.Saver() | 创建Saver对象 |
| tf.train.Saver().save(sess, save_path, global_step=step) | 在训练循环中,定期调用 saver.save() 方法,向文件夹中写入包含了当前模型中所有可训练变量的 checkpoint 文件 |
| tf.train.Saver().restore(sess, save_path) | 重载模型的参数,继续训练或用于测试数据或迁移学习 |
| tf.summary.merge_all() | 创建一个可以获取当前图的Summary的操作 |
| tf.summary.FileWriter() | 创建一个可将Summary读入指定路径中文件的对象 |
| tf.summary.FileWriter().add_summary() | 将训练过程中获取的Summary保存在Filewriter指定的文件中 |
| tf.global_variables_initializer() | 返回一个用来初始化计算图中所有global variable的操作 |
| tf.Session() | 创建一个会话,用于执行执行定义好的运算 |
| sess.run() | 先查看图中的依赖关系,得到本次sess.run()需要计算图中那些节点,然后进行一次计算 |
| tf.train.Coordinator() | 创建一个线程管理器(协调器)对象,管理在Session中的多个线程 |
| tf.train.start_queue_runners() | 入队线程启动器,把tensor推入内存序列中,供计算单元调用 |
| tf.train.Coordinator().should_stop() | 线程执行运行循环,当should_stop()返回True时停止 |
注:一次 Saver.save() 后可以在文件夹中看到新增的四个文件,权重等参数以字典的形式被保存到 .ckpt.data 文件中
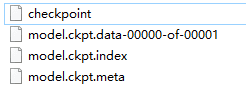
- checkpoint文件记录中间保存模型的位置的,第一行表明最新的模型,其他行是保存的其它模型,随迭代次数从低到高排列
- .meta文件保存了当前图结构,一般网络结构是不会在训练过程中发生改变,只需保存一个
- .data文件保存了当前训练阶段,网络各层的权值,偏置,操作
- .index文件保存了辅助索引信息
#%% Training
def train():
tf.reset_default_graph()
pre_trained_weights = '/content/gdrive/My Drive/CIFAR10_VGG/vgg16.npy'
data_dir = '/content/gdrive/My Drive/CIFAR10_VGG/cifar-10-batches-bin/'
train_log_dir = '/content/gdrive/My Drive/CIFAR10_VGG/logs/train/'#训练日志
val_log_dir = '/content/gdrive/My Drive/CIFAR10_VGG/logs/val/' #验证日志
with tf.name_scope('input'): # Dataloading,return Tensor(images, label_batch)
tra_image_batch, tra_label_batch = input_data.read_cifar10(data_dir=data_dir,
is_train=True,
batch_size= BATCH_SIZE,
shuffle=True)
val_image_batch, val_label_batch = input_data.read_cifar10(data_dir=data_dir,
is_train=False,
batch_size= BATCH_SIZE,
shuffle=False)
logits = VGG.VGG16N(tra_image_batch, N_CLASSES, IS_PRETRAIN) # VGG16(Conv层预设参数)
loss = tools.loss(logits, tra_label_batch) # loss
accuracy = tools.accuracy(logits, tra_label_batch) # accuracy
my_global_step = tf.Variable(0, name='global_step', trainable=False)
train_op = tools.optimize(loss, learning_rate, my_global_step) # optimizer
x = tf.placeholder(tf.float32, shape=[BATCH_SIZE, IMG_W, IMG_H, 3]) # placeholder
y_ = tf.placeholder(tf.int16, shape=[BATCH_SIZE, N_CLASSES])
saver = tf.train.Saver(tf.global_variables()) # saver
summary_op = tf.summary.merge_all()
init = tf.global_variables_initializer()
sess = tf.Session()
sess.run(init)
# load the parameter file, assign the parameters, skip the specific layers
tools.load_with_skip(pre_trained_weights, sess, ['fc6','fc7','fc8']) # skip_layer=['fc6','fc7','fc8'],
# 因为训练自己的数据,全连接层最好不要使用预训练参数
coord = tf.train.Coordinator()
threads = tf.train.start_queue_runners(sess=sess, coord=coord)
tra_summary_writer = tf.summary.FileWriter(train_log_dir, sess.graph) # graph
val_summary_writer = tf.summary.FileWriter(val_log_dir, sess.graph)
try:
for step in np.arange(MAX_STEP):
if coord.should_stop():
break
# 读取数据,转化为Tensor以供 feed_dict
tra_images,tra_labels = sess.run([tra_image_batch, tra_label_batch])
# 优化,计算交叉熵,准确率
_, tra_loss, tra_acc = sess.run([train_op, loss, accuracy],
feed_dict={x:tra_images, y_:tra_labels})
# 每50个epoch 打印loss,accuracy,获取Summary,并调用tf.summary.FileWriter的实例的add_summary方法将训练过程中的Summary以及训练步数保存
if step % 50 == 0 or (step + 1) == MAX_STEP:
print ('Step: %d, loss: %.4f, accuracy: %.4f%%' % (step, tra_loss, tra_acc))
summary_str = sess.run(summary_op)
tra_summary_writer.add_summary(summary_str, step)
# 每200个epoch读取batch大小的验证集进行验证
if step % 200 == 0 or (step + 1) == MAX_STEP:
val_images, val_labels = sess.run([val_image_batch, val_label_batch])
val_loss, val_acc = sess.run([loss, accuracy],
feed_dict={x:val_images,y_:val_labels})
print('** Step %d, val loss = %.2f, val accuracy = %.2f%% **' %(step, val_loss, val_acc)
summary_str = sess.run(summary_op)
val_summary_writer.add_summary(summary_str, step)
# 每2000个epoch调用 saver.save() 方法,向文件夹中写入包含了当前模型中所有可训练变量的 checkpoint 文件
if step % 2000 == 0 or (step + 1) == MAX_STEP:
checkpoint_path = os.path.join(train_log_dir, 'model.ckpt')
saver.save(sess, checkpoint_path, global_step=step)
# epoch设置过小或读取数据失败会引起 tf.errors.OutOfRangeError
except tf.errors.OutOfRangeError:
print('Done training -- epoch limit reached')
finally:
# 终止线程
coord.request_stop()
coord.join(threads)
sess.close()
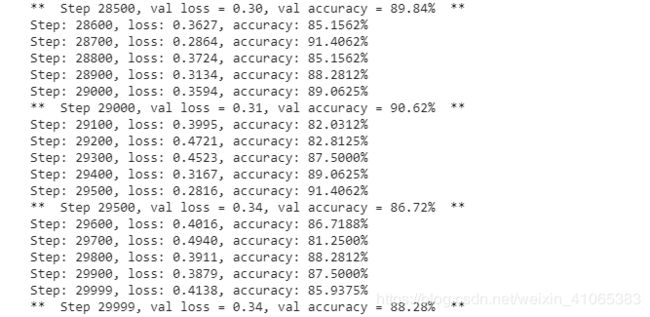
结果如下:
验证函数
| 函数 | 功能 |
|---|---|
| tf.train.get_checkpoint_state() | 返回的是checkpoint文件的内容,其中有model_checkpoint_path和all_model_checkpoint_paths两个属性:model_checkpoint_path保存了最新的tensorflow模型文件的文件名,all_model_checkpoint_paths则有未被删除的所有tensorflow模型文件的文件名 |
| tf.train.Saver().restore(sess, save_path) | 重载模型的参数,继续训练或用于测试数据或迁移学习 |
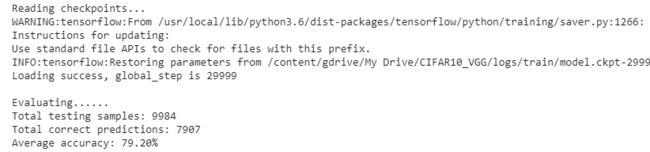
#%% Test the accuracy on test dataset. got about 85.69% accuracy.
import math
def evaluate():
with tf.Graph().as_default():
log_dir = '/content/gdrive/My Drive/CIFAR10_VGG/logs/train/'#训练日志
test_dir = '/content/gdrive/My Drive/CIFAR10_VGG/cifar-10-batches-bin/'
n_test = 10000
images, labels = input_data.read_cifar10(data_dir=test_dir,
is_train=False,
batch_size= BATCH_SIZE,
shuffle=False)
logits = VGG.VGG16N(images, N_CLASSES, IS_PRETRAIN)
correct = tools.num_correct_prediction(logits, labels)
saver = tf.train.Saver(tf.global_variables())
with tf.Session() as sess:
print("Reading checkpoints...")
ckpt = tf.train.get_checkpoint_state(log_dir)
if ckpt and ckpt.model_checkpoint_path:
global_step = ckpt.model_checkpoint_path.split('/')[-1].split('-')[-1]
# 重载上面训练得到的最新的模型
saver.restore(sess, ckpt.model_checkpoint_path)
print('Loading success, global_step is %s' % global_step)
else:
print('No checkpoint file found')
return
coord = tf.train.Coordinator()
threads = tf.train.start_queue_runners(sess = sess, coord = coord)
try:
print('\nEvaluating......')
num_step = int(math.floor(n_test / BATCH_SIZE))
num_sample = num_step*BATCH_SIZE
step = 0
total_correct = 0
while step < num_step and not coord.should_stop():
batch_correct = sess.run(correct)
total_correct += np.sum(batch_correct)
step += 1
print('Total testing samples: %d' %num_sample)
print('Total correct predictions: %d' %total_correct)
print('Average accuracy: %.2f%%' %(100*total_correct/num_sample))
except Exception as e:
coord.request_stop(e)
finally:
coord.request_stop()
coord.join(threads)
#%%
github地址:https://github.com/wait1ess/VGG16_CIFAR (用于本地训练)