dropout防止过拟合的原因
常见的减小过拟合的方法有:正则化 、Early Stop、 增加数据、 dropout【1】。其中,drop out主要用在神经网络模型中,其避免过拟合的原因,参考【2】内内容,理解如下:
1.类似取平均值的作用。
普通的模型(没有dropout),用相同的训练数据去训练3个不同的神经网络,一般会得到3个不同的结果,此时我们可以采用 “3个结果取均值”或者“多数取胜的投票策略”去决定最终结果。(例如 2个网络判断结果为数字9,那么很有可能真正的结果就是数字9,另外1个网络给出了错误结果)。这种“综合起来取平均”的策略通常可以有效防止过拟合问题。因为不同的网络可能产生不同的过拟合,取平均则有可能让一些“相反的”拟合互相抵消。dropout掉不同的隐藏神经元就类似在训练不同的网络(随机删掉一半隐藏神经元导致网络结构已经不同),整个dropout过程就相当于 对很多个不同的神经网络取平均。而不同的网络产生不同的过拟合,一些互为“反向”的拟合相互抵消就可以达到整体上减少过拟合。每一个这样的dropout网络,都可以给出一个分类结果,这些结果有的是正确的,有的是错误的。在训练中,每次的不同的网络都会得到一个结果,当训练次数多的时候,更多的结果可趋向正确的目标,训练了多个网络多数取胜的思想可以用得上。
2.减少神经元之间复杂的共适应关系
因为dropout程序导致两个神经元不一定每次都在一个dropout网络中出现。(这样权值的更新不再依赖于有固定关系的隐含节点的共同作用,阻止了某些特征仅仅在其它特定特征下才有效果的情况)。 迫使网络去学习更加鲁棒的特征 (这些特征在其它的神经元的随机子集中也存在)。换句话说假如我们的神经网络是在做出某种预测,它不应该对一些特定的线索片段太过敏感,即使丢失特定的线索,它也应该可以从众多其它线索中学习一些共同的模式(鲁棒性)。(这个角度看 dropout就有点像L1,L2正则,减少权重使得网络对丢失特定神经元连接的鲁棒性提高,使得避免在某些特定的特征处的权值过于显著,增大其他神经元可能的影响)
3.随机性的添加
dropout具有随机性,使得网络在每次迭代中dropout的神经元不同,因此,可以将神经元之间复杂的联系降低,使得学习到的网络更加鲁棒。且使得优化过程中,可能会避免参数在局部最优处震荡,提高性能。
4.Dropout总结:
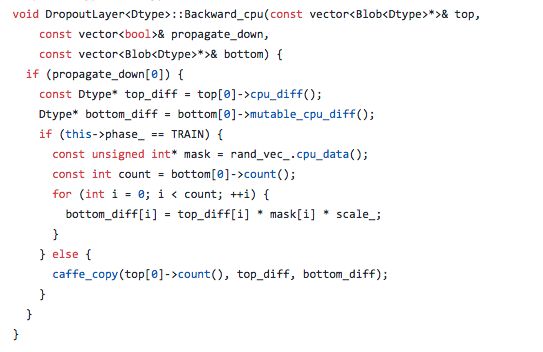
1.伯努利分布:伯努利分布亦称“零一分布”、“两点分布”。称随机变量X有伯努利分布, 参数为p(0 2. dropout其实也是一种正则化,因为也把参数变稀疏(l1,原论文)和变小(l2,caffe实际实现)。只有极少的训练样本可用时,Dropout不会很有效。因为Dropout是一个正则化技术,它减少了模 型的有效容量。为了抵消这种影响,我们必须增大模型规模。不出意外的话,使 用Dropout时较佳验证集的误差会低很多,但这是以更大的模型和更多训练算法的迭 代次数为代价换来的。对于非常大的数据集,正则化带来的泛化误差减少得很小。在 这些情况下,使用Dropout和更大模型的计算代价可能超过正则化带来的好处。http://www.dataguru.cn/article-10459-1.html idea:想利用集成学习bagging的思想,通过训练多个不同的模型来预测结果。但是神经网络参数量巨大,训练和测试网络需要花费大量的时间和内存。 功能:1.解决过拟合 2.加快训练速度 为什么呢work: 1.dropout类似于多模型融合,多模型融合本身能解决解决一下过拟合 因为不同的网络可能产生不同的过拟合,取平均则有可能让一些“相反的”拟合互相抵消。dropout掉不同的隐藏神经元就类似在训练不同的网络(随机删掉一半隐藏神经元导致网络结构已经不同),整个dropout过程就相当于 对很多个不同的神经网络取平均。而不同的网络产生不同的过拟合,一些互为“反向”的拟合相互抵消就可以达到整体上减少过拟合。https://zhuanlan.zhihu.com/p/23178423 2.减少神经元之间复杂的共适应关系: 因为dropout程序导致两个神经元不一定每次都在一个dropout网络中出现。(这样权值的更新不再依赖于有固定关系的隐含节点的共同作用,阻止了某些特征仅仅在其它特定特征下才有效果的情况)。 迫使网络去学习更加鲁棒的特征 (这些特征在其它的神经元的随机子集中也存在)。换句话说假如我们的神经网络是在做出某种预测,它不应该对一些特定的线索片段太过敏感,即使丢失特定的线索,它也应该可以从众多其它线索中学习一些共同的模式(鲁棒性)。(这个角度看 dropout就有点像L1,L2正则,减少权重使得网络对丢失特定神经元连接的鲁棒性提高)https://zhuanlan.zhihu.com/p/23178423 3.正则化。让参数稀疏和让参数变小 4.加噪声。观点十分明确,就是对于每一个dropout后的网络,进行训练时,相当于做了Data Augmentation,因为,总可以找到一个样本,使得在原始的网络上也能达到dropout单元后的效果。 比如,对于某一层,dropout一些单元后,形成的结果是(1.5,0,2.5,0,1,2,0),其中0是被drop的单元,那么总能找到一个样本,使得结果也是如此。这样,每一次dropout其实都相当于增加了样本。https://blog.csdn.net/stdcoutzyx/article/details/49022443 caffe的实现: 论文中的实现: 训练,用伯努利分布生成概率,以概率p打开,概率1-p关闭,打开就是直接把值正常传给下一层,关闭就是不进行正向传播,传给下一层的值是0 测试,用伯努利分布分成概率,将每个权重乘以概率p进行衰减 caffe实现: 训练,用伯努利分布生成概率,以概率p打开,概率1-p关闭。打开的同时要乘以一个系数,相当于把权重放大。关闭还是和论文一样。 测试,直接把上一层的数值传递给下一层,其实也可以直接不用这一层 为什么要这么去实现: https://blog.csdn.net/u012702874/article/details/45030991解答了为什么要在测试的时候rescale,因为如果直接使用dropout丢弃,其实就是选择了其中的n*p个神经元,所有参数乘以p其实也就是相当于选择了n*p,数量级是至少是一样的 至于caffe为什么要放大,https://stackoverflow.com/questions/50853538/caffe-why-dropout-layer-exists-also-in-deploy-testing这个也没能很好解释,只能说是等效的 前向传播: 反向传播(注意:不进行反向传播,其实只是不求梯度,把上一层的梯度直接传给下一层): 如果进行反向传播,还是以概率p传播梯度,概率1-p不传梯度给下一层,也就是0 如果不进行反向传播,直接把上一层的梯度传给下一层 dropout与bagging的关系: 在Bagging的情况下,所有模型是独立 的。在Dropout的情况下,模型是共享参数的,其中每个模型继承的父神经网络参 数的不同子集。参数共享使得在有限可用的内存下代表指数数量的模型变得可能。 在Bagging的情况下,每一个模型在其相应训练集上训练到收敛。在Dropout的情况下,通常大部分模型都没有显式地被训练,通常该模型很大,以致到宇宙毁灭都不 能采样所有可能的子网络。取而代之的是,可能的子网络的一小部分训练单个步骤,参数共享导致剩余的子网络能有好的参数设定。这些是仅有的区别。除了这些,Dropout与Bagging算法一样。例如,每个子网络中遇到的训练集确实是替换采样的 原始训练集的一个子集。 关于Dropout的一个重要见解是,通过随机行为训练网络并平均多个随机决定进 行预测,通过参数共享实现了Bagging的一种形式。 参考资料1:机器学习防止过拟合的方法https://blog.csdn.net/heyongluoyao8/article/details/49429629 参考资料2: Dropout防止过拟合的理解https://blog.csdn.net/u010748502/article/details/80644847 参考资料3: https://zhuanlan.zhihu.com/p/23178423 参考资料4:https://www.cnblogs.com/ymjyqsx/p/9451072.html