股票量化交易-获取数据的N种方法
来源:萧遥量化
作者: sally
在上一篇的基础上再分享两个量化股票需要的数据资源。
通过python第三方库pytdx获取
这是个很强大的第三方库,原理是解析通达信的.dat底层数据。没错,我说的就是老少皆宜,平时看盘下单的通达信软件。现在只需要在python里面安装第三方库,就可以获取到原始交易数据了。
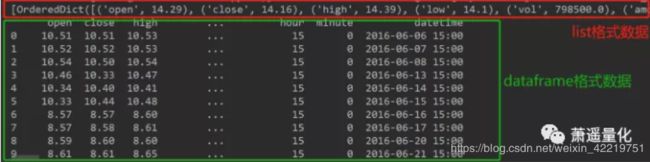
获取行情数据的代码是这样的,返回数据可以是list格式,也可以是dataframe格式。
from pytdx.hq import
TdxHq_APIapi = TdxHq_API()
# 数据获取接口一般返回list结构,如果需要转化为pandas Dataframe接口,可以使用 api.to_df 进行转化
with api.connect('119.147.212.81', 7709):
# 返回普通list
data = api.get_security_bars(9, 0, '000001', 0, 10) print(data)
# 返回DataFrame
data = api.to_df(api.get_security_bars(9, 0, '000001', 0, 800)) print(data)
返回数据如下:
除了行情数据,还可以获得财务数据
from pytdx.crawler.history_financial_crawler import HistoryFinancialListCrawler crawler = HistoryFinancialListCrawler() list_data = crawler.fetch_and_parse() print(pd.DataFrame(data=list_data))
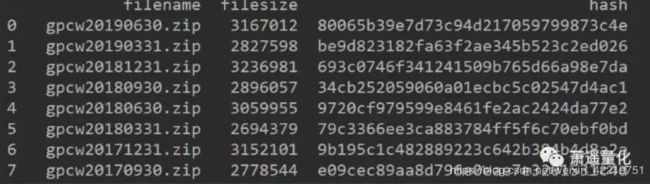
运行上面的程序可以得到下面的结果,这些zip文件就是当季所有股票的财务数据。我们可以看到最新的财务数据已经更新到2019年6月30日。
除了行情数据,还可以获得财务数据
from pytdx.crawler.history_financial_crawler import HistoryFinancialListCrawler crawler = HistoryFinancialListCrawler() list_data = crawler.fetch_and_parse() print(pd.DataFrame(data=list_data))
运行上面的程序可以得到下面的结果,这些zip文件就是当季所有股票的财务数据。我们可以看到最新的财务数据已经更新到2019年6月30日。
下面我们来查看一下最近一个财务周期的数据是怎样的。
from pytdx.reader import HistoryFinancialReader
import pandas as pd
pd.set_option('display.max_columns', None)
print(HistoryFinancialReader().get_df('C://zd_axzq//vipdoc//cw//gpcw20190630.zip'))
注意这里获取数据的地址是需要你自己电脑上通达信的安装目录,如果找不到这个目录呢,可以在浏览器里面搜索gpcw20190630.zip这个文件就能找到了
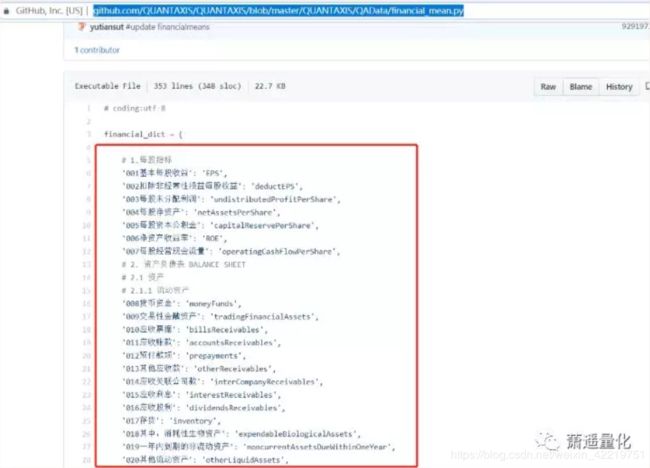
运行上面的代码后可以得到如下的数据,左边的code就是股票代码,右边col001-col300是财务数据,具体每个编号对应哪个财务数据,请查看这里https://github.com/QUANTAXIS/QUANTAXIS/blob/master/QUANTAXIS/QAData/financial_mean.py
从腾讯网站获取历史数据
获取数据的网址是这个:http://web.ifzq.gtimg.cn/appstock/app/fqkline/get?_var=kline_dayqfq¶m=sz000001,day,,,50,qfq&r=0.5643184591626897
其中需要输入几个参数,股票代码,数据的周期(年,月,周,日)
from urllib.request import urlopen
import json
from random import randint
import pandas as pd
pd.set_option('expand_frame_repr', False)
pd.set_option('display.max_rows', 5000)
# =====创建随机数的函数
def _random(n=16):
"""
创建一个n位的随机整数
:param n:
:return:
"""
start = 10**(n-1)
end = (10**n)-1
return str(randint(start, end))
stock_code = 'sz000001'
type = 'day' # day, week, month分别对用日线、周线、月线
num = 640 # 股票最多不能超过640,指数、etf等没有限制
# 构建url
url = 'http://web.ifzq.gtimg.cn/appstock/app/fqkline/get?_var=kline_%sqfq¶m=%s,%s,,,%s,qfq&r=0.%s'
url = url % (k_type, stock_code, k_type, num, _random())
content = urlopen(url).read().decode()
content = content.split('=', maxsplit=1)[-1]
content = json.loads(content)
data = content['data'][stock_code]
if type in data:
data = data[type]
elif 'qfq' + type in data: # qfq是前复权的缩写
data = data['qfq' + type]
else:
raise ValueError('已知的key在dict中均不存在,请检查数据')
df = pd.DataFrame(data)
print(df)
运行代码后获得的数据如下:
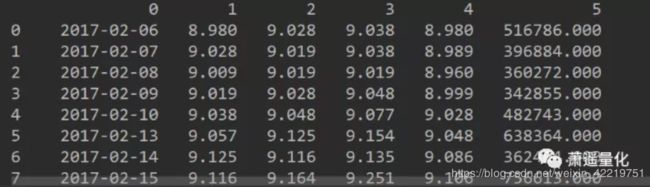
其中0: 'candle_end_time', 1: 'open', 2: 'close', 3: 'high', 4: 'low', 5: 'amount'
复权处理
上面两种方法得到的数据都是未经过复权处理的,那么我们怎样得到复权的数据呢?
我们可以通过计算复权因子来得到复权数据,具体方法如下代码。
import pandas as pd
pd.set_option('expand_frame_repr', False)
pd.set_option('display.max_rows', 5000)
# 导入数据
path = 'D:/sz000001.csv'
df = pd.read_csv(path, encoding='gbk', skiprows=1)
# 计算复权涨跌幅
df['涨跌幅'] = df['收盘价'] / df['前收盘价'] - 1
# 计算复权因子
df['复权因子'] = (1 + df['涨跌幅']).cumprod()
# 计算前复权价
df['收盘价_复权'] = df['复权因子'] * (df.iloc[-1]['收盘价'] / df.iloc[-1]['复权因子'])
# 计算后复权价
df['收盘价_复权'] = df['复权因子'] * (df.iloc[0]['收盘价'] / df.iloc[0]['复权因子'])
# 计算复权后的开盘价、最高价、最低价
df['开盘价_复权'] = df['开盘价'] / df['收盘价'] * df['收盘价_复权']
df['最高价_复权'] = df['最高价'] / df['收盘价'] * df['收盘价_复权']
df['最低价_复权'] = df['最低价'] / df['收盘价'] * df['收盘价_复权']
tushare获取数据
tushare上有丰富的交易数据,财务数据。安装也十分简单,pip install tushare就可以了。https://tushare.pro/
下面示例一下历史交易数据和财务数据的获取
pro = ts.pro_api() df = ts.pro_bar(ts_code='300024.SZ', adj='qfq', start_date='20180101', end_date='20190920') print(df)
这是获取股票300024从2018年1月1号到2019年9月20号的所有前复权数据的代码。运行后返回的数据如下。

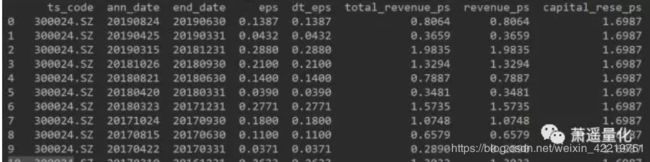
下面是获取财务指标数据的代码
pro = ts.pro_api() df = pro.fina_indicator(ts_code='300024.SZ') print(df)
运行后返回dataframe格式数据,非常方便调取我们需要的列数据。比如我们要调取EPS数据,只需要这样写就可以了print (df['eps'])
掘金量化API
掘金量化是一个在线量化平台,目前推出了可以在本地使用的数据API接口,这个平台类似于聚宽,优矿,可以在线写策略并回测。亮点在于,这个平台支持本地IDE编辑策略,也就是说策略编写是存放在本地而不是在平台的云端,这样可以避免策略泄露。
这是掘金API说明书https://www.myquant.cn/docs/python/73?
具体加载数据和回测仔细看看说明就可以了解。