利用Python进行数据分析(一):IPython及Jupyter notebook
本文为《利用Python进行数据分析》的部分读书笔记
目录
- IPython与Jupyter notebook简介
- IPython基础
- 使用IPython命令行
- 运行Jupyter notebook
- 配置文件
- Jupyter Notebook 文件默认目录的查看以及更改
- Tab补全
- 内省
- 魔术命令
- matplotlib集成
- 更多IPython系统相关内容
- 输入和输出变量
- 删除变量
- 与操作系统交互
- 软件开发工具
- debug
- 代码分析
IPython与Jupyter notebook简介
IPython项目旨在开发一个更具交互性的Python解释器,它使用了一种执行-探索工作流来替代其它语言中典型的编辑-编译-运行工作流。它还提供针对操作系统命令行与文件系统的易用接口。Jupyter项目旨在设计一个适用于更多语言的交互式计算工具。IPython web notebook则成为Jupyter notebook。IPython系统目前可以作为一个内核用于在Jupyter中使用Python。
总而言之,IPython就是一个加强版的Python解释器,Jupyter notebook则是一种基于web的代码笔记本。
IPython基础
使用IPython命令行
$ ipython
Python 3.7.4 (default, Aug 9 2019, 18:34:13) [MSC v.1915 64 bit (AMD64)]
Type 'copyright', 'credits' or 'license' for more information
IPython 7.8.0 -- An enhanced Interactive Python. Type '?' for help.
In [1]:
运行Jupyter notebook
- 在本地运行jupyter notebook
$ jupyter notebook
jupyter notebook可以作为本地计算环境,也可以部署在服务器端。在服务器中开启Notebook服务,即可在本地的浏览器端进行访问。
- 新建一个笔记本

- shift+enter运行代码

- 保存代码
配置文件
在配置文件中可以
- 更改颜色主题
- 执行任意Python语句(例如导入常用的库以及一些你希望每次启动IPython就运行的程序)
- 启动IPython扩展
- 激活Jupyter拓展
- 自定义魔术函数或系统别名
运行下列指令:
jupyter notebook --generate-config
上面的代码会将默认配置文件写入主目录下的.jupyter/jupyter_notebook_config.py。我win10电脑上的路径为D:\Software\Cadence\Cadence\SPB_Data.jupyter\jupyter_notebook_config.py,打开相应文件后即可进行配置。也可以将其重命名为不同的文件,之后在启动jupyter notebook时添加–config参数使用该配置:
jupyter notebook --config=D:\Software\Cadence\Cadence\SPB_Data\.jupyter\jupyter_notebook_config.py
Jupyter Notebook 文件默认目录的查看以及更改
参考:https://blog.csdn.net/nico2333/article/details/84186063
在jupyter_notebook_config.py中搜索c.NotebookApp.notebook_dir,将它的值设置为想要的路径即可
Tab补全
- 对对象的属性名称进行补全

- 路径补全
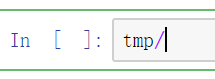
- 函数关键字补全

内省
- 在一个变量名的前后使用问号(?)可以显示一些关于该对象的文档字符串以及其他概要信息:


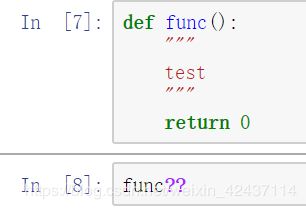
- 使用双问号显示函数源代码

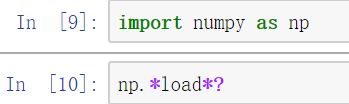
- 搜索IPython命名空间

魔术命令
IPython中的特殊命令被称为魔术命令,前缀符为%。大多数魔术命令都可以使用?查看额外的命令行参数。
- %run: 在IPython会话中运行任意Python程序文件
%run hello_world.py
%run -i hello_world.py #让待运行的脚本使用交互式IPython命名空间中已有的变量
- %load: 将脚本导入一个代码单元
%load hello_world.py
- %time: 报告单个语句的执行时间

wall time(壁钟时间) 测量的时间不是一个非常精确的测量 - %timeit: 多次运行单个语句计算平均执行时间,对于执行时间很短的分析语句和函数特别有用,测得时间也更加精确
%timeit np.dot(a,a)
- %pwd: 显示当前工作目录
其输出可以赋给一个变量

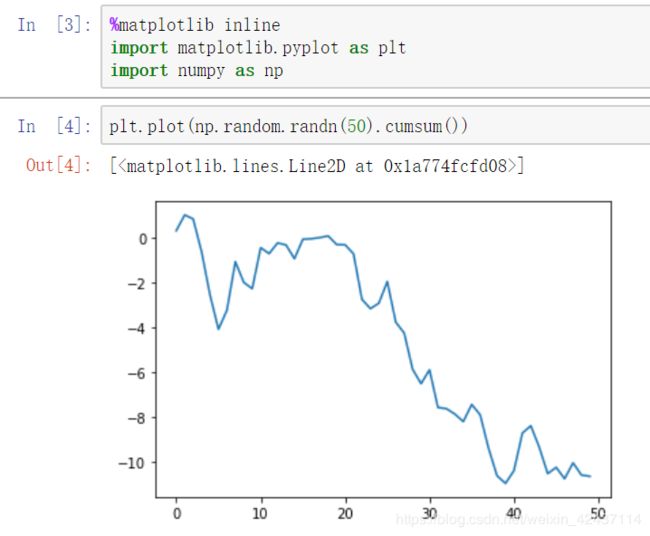
matplotlib集成
更多IPython系统相关内容
输入和输出变量
-
IPython会话存储对输入和输出命令的引用,并将特定变量中的Python对象输出。前两个输出分别存储在_(一个下划线)和__(两个下划线)变量中
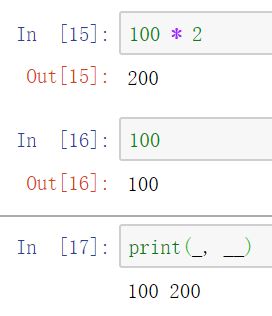
-
输入变量存储在_iX变量中,X为输入行号。对于每个输入变量,都有一个对应的输出变量_X

由于输入变量是字符串,可以使用exec函数再次执行它们
exec(_i19)
删除变量
在处理非常大的数据集时,即使使用del删除变量,IPython的输入和输出历史记录也会导致引用的所有对象不会被垃圾回收。这种情况下,可以使用%reset和%xdel来避免内存问题
- %reset: 删除交互式命名空间中所有的变量/名称
- %xdel: 从IPython机器中移除对象的所有引用
与操作系统交互
- !cmd: 在系统命令行中执行cmd命令
- output = !cmd args: 运行cmd并在output中保存stdout
#Linux
ip_info = !ifconfig wlan0 | grep "inet"
- 使用变量作为命令参数
foo = 'test*'
!ls $foo
- %alias: 为shell命令自定义快捷键
%alias ll ls -l
%alias test_alias (ls; cd ..; ls)
- %bookmark: 目标书签系统允许保存通用目录别名,以便轻松跳转
%bookmark py4da /home/richard/pydata-book
!cd py4da
%bookmark -l #列出所有书签
- %cd directory: 将系统工作目录更改到传递的目录
- %pwd: 返回当前工作目录
软件开发工具
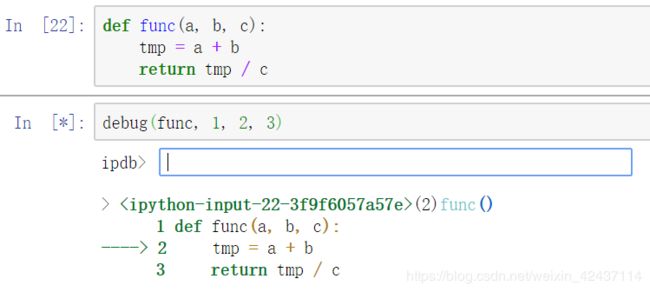
debug
IPython集成并增强了内置的Python pdb调试器,加强的地方包括tab键补全、语法高亮以及异常回溯中每一行的上下文。
Python调试器命令:
| 命令 | 动作 |
|---|---|
| h(elp) | 展示命令列表 |
| help command | 显示command命令的文档 |
| c(ontinue) | 恢复程序执行 |
| q(uit) | 退出调试器 |
| b(reak) number | 在当前文件的number位置设置断点 |
| b(reak) path/file.py:number | 在指定文件的number位置设置断点 |
| s(tep) | 单步进入函数调用 |
| n(ext) | 执行当前行,并进入到当前层级的下一行 |
| u§/d(own) | 在函数调用堆栈中上下移动 |
| a(rgs) | 显示当前函数的参数 |
| debug statement | 在新的(递归)调试器中调用语句statement |
| l(ist) statement | 显示当前堆栈的当前位置和上下文 |
| w(here) | 在当前位置打印带有上下文的完整堆栈回溯 |
调试器命令优先于变量名称,在这种情况下,变量前面加上!来检查变量内容
- 在异常发生后立刻输入%debug,可以唤起调试器并进入抛出异常的堆栈区,默认从最底层即错误发生的地方开始。通过u和d,可以在堆栈回溯的不同层级间切换


- %run -d xxx.py: 在执行所有传递的脚本中的代码前唤起调试器,用于单步执行脚本。必须按下s(step)来进入脚本
%run -d -b2 xxx.py会启动一个已经设置了断点的调试器(在第2行设置断点)




- 两个小技巧
from IPython.core.debugger import Pdb
import sys
def set_trace():
Pdb().set_trace(sys._getframe().f_back)
def debug(f, *args, **kwargs):
return Pdb().runcall(f, *args, **kwargs)
- set_trace()在代码中调用可以充当断点

- debug()允许在任意函数调用中唤起交互式调试器
代码分析
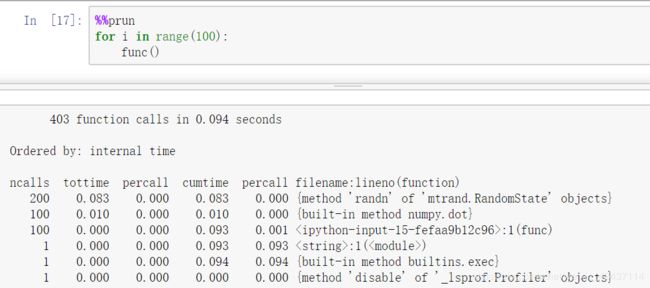
代码分析更多关注于时间开销的位置。使用Python分析工具cProfile模块。cProfile执行程序或任意代码块,同时记录每个函数花费多少时间。
- python -m cProfile -s cumulative xxx.py: 在命令行上运行整个程序,并输出每个函数的聚合时间。
%run -p有相同效果
-s用于指定一个排序顺序

- %prun: 与cProfile采用相同的命令行选项,但会分析任意Python语句而不是整个.py文件
-l 7表示取前7行

- %%prun: 分析整个代码块
- 逐行分析函数
- 安装line_profiler
conda install line_profiler
- 开启IPython扩展
%load_ext line_profiler
- 使用%lprun进行分析

