使用语义预训练模型ERNIE进行多标签文本分类
ERNIE:Enhanced Representation through Knowledge Integration(baidu)
贡献:
- 通过实体和短语mask能够学习语法和句法信息的语言模型
- 在很多中文自然语言处理任务上达到state-of-the art
- 放出了代码和与训练模型
方法:与BERT类似
训练数据集:中文维基百科,百度百科,百度新闻,百度贴吧
参数:L=12,H=768,A=12(BERT BASE)
数据连接:链接:https://pan.baidu.com/s/1RsB6mSeUznIFVlY1x8pC_w 提取码:4ydz
本项目代码需要使用GPU环境来运行(本例在Aistudio上运行)
# 安装PaddleHub
!pip install --upgrade paddlehub -i https://pypi.tuna.tsinghua.edu.cn/simple
数据说明:
原始数据集为高中下地理,历史,生物,政治四门学科数据,每个学科下各包含第一层知识点,如历史下分为近代史,现代史,古代史。
原始数据示例:
[题目]
我国经济体制改革首先在农村展开。率先实行包产到组、包产到户的农业生产责任制的省份是( )
①四川 ②广东 ③安徽 ④湖北A. ①③B. ①④C. ②④D. ②③题型: 单选题|难度: 简单|使用次数: 0|纠错复制收藏到空间加入选题篮查看答案解析答案:A解析:本题主要考察的是对知识的识记能力,比较容易。根据所学知识可知,在四川和安徽,率先实行包产到组、包产到户的农业生产责任制,故①③正确;②④不是。所以答案选A。知识点:
[知识点:]
经济体制改革,中国的振兴
对数据处理:
将数据的[知识点:]作为数据的第四层标签,显然不同数据的第四层标签数量不一致
仅保留题目作为数据特征,删除[题型]及[答案解析]
加载自定义数据集:
用户仅需要继承HubDataset类,替换数据集存放地址即可。 下面代码示例展示如何将自定义数据集加载进PaddleHub使用。
import os
import pandas as pd
import paddlehub as hub
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import MultiLabelBinarizer
读取数据
#这里需要把数据上传到aistudio上
DATA_OUTPUT_DIR='/home/aistudio/data/data28259/'
data_path=os.path.join(DATA_OUTPUT_DIR,'baidu_95.csv')
df=pd.read_csv(data_path,header=None, names=["labels", "content"], dtype=str)
数据预处理
#将标签数字化
df['labels']=df['labels'].apply(lambda x:x.split())
mlb = MultiLabelBinarizer()
y = mlb.fit_transform(df['labels'])
y=[' '.join([str(j) for j in i]) for i in y.tolist()]
df['labels']=y
classes_df=pd.DataFrame(mlb.classes_)
df.head()
输出:
0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 ...#标签,1为对应此位置的标签
菠菜从土壤中吸收的氮元素可以用来合成()A.淀粉和纤维素B.葡萄糖和DNAC.核酸和蛋白质D..
# 训练数据集划分
train_df, test_df = train_test_split(df, test_size=0.8, random_state=42)
# 测试和验证集划分
test_df, dev_df = train_test_split(test_df, test_size=0.5, random_state=42)
# 保存数据
train_df.to_csv(os.path.join(DATA_OUTPUT_DIR, 'train.tsv'),index=None,header=None)
dev_df.to_csv(os.path.join(DATA_OUTPUT_DIR, 'dev.tsv'),index=None,header=None)
test_df.to_csv(os.path.join(DATA_OUTPUT_DIR, 'test.tsv'),index=None,header=None)
# 保存类别标签
classes_df.to_csv(os.path.join(DATA_OUTPUT_DIR,'classes.csv'),index=None,header=None)
数据加载
此部分和BERT基本相同,都是自己创建一个读取数据的类(继承封装好的基类)
from __future__ import absolute_import
from __future__ import division
from __future__ import print_function
from collections import namedtuple
import codecs
import os
import csv
from paddlehub.dataset.dataset import InputExample, BaseDataset
from paddlehub.common.downloader import default_downloader
from paddlehub.common.dir import DATA_HOME
from paddlehub.common.logger import logger
class Baidu95(BaseDataset):
"""
ChnSentiCorp (by Tan Songbo at ICT of Chinese Academy of Sciences, and for
opinion mining)
"""
def __init__(self):
self.dataset_dir = DATA_OUTPUT_DIR
if not os.path.exists(self.dataset_dir):
logger.info("Dataset not exists.".format(self.dataset_dir))
else:
logger.info("Dataset {} already cached.".format(self.dataset_dir))
self._load_train_examples()
self._load_test_examples()
self._load_dev_examples()
def _load_train_examples(self):
self.train_file = os.path.join(self.dataset_dir, "train.tsv")
self.train_examples = self._read_tsv(self.train_file)
def _load_dev_examples(self):
self.dev_file = os.path.join(self.dataset_dir, "dev.tsv")
self.dev_examples = self._read_tsv(self.dev_file)
def _load_test_examples(self):
self.test_file = os.path.join(self.dataset_dir, "test.tsv")
self.test_examples = self._read_tsv(self.test_file)
def get_train_examples(self):
return self.train_examples
def get_dev_examples(self):
return self.dev_examples
def get_test_examples(self):
return self.test_examples
def get_labels(self):
return pd.read_csv(os.path.join(DATA_OUTPUT_DIR,'classes.csv'),names=['labels'])['labels'].tolist()
@property
def num_labels(self):
"""
Return the number of labels in the dataset.
"""
return len(self.get_labels())
def _read_tsv(self, input_file, quotechar=None):
"""Reads a tab separated value file."""
with codecs.open(input_file, "r", encoding="UTF-8") as f:
reader = csv.reader(f, delimiter=",", quotechar=quotechar)
examples = []
seq_id = 0
header = next(reader) # skip header
for line in reader:
example = InputExample(
guid=seq_id, label=[int(i) for i in line[0].split(' ')], text_a=line[1])
seq_id += 1
examples.append(example)
return examples
dataset = Baidu95()
安装ernie-tiny
!hub install ernie_tiny
# 更换name参数即可无缝切换BERT中文模型, 代码示例如下
max_seq_len=256
module = hub.Module(name="bert_chinese_L-12_H-768_A-12") # (name="bert_chinese_L-12_H-768_A-12")
inputs, outputs, program = module.context(trainable=True, max_seq_len=max_seq_len)
如果想尝试其他语义模型(如ernie_tiny, R等),只需要更换Module中的name参数即可.
模型名 PaddleHub Module
ERNIE, Chinese hub.Module(name='ernie')
ERNIE 2.0 Tiny, Chinese hub.Module(name='ernie_tiny')
ERNIE 2.0 Base, English hub.Module(name='ernie_v2_eng_base')
ERNIE 2.0 Large, English hub.Module(name='ernie_v2_eng_large')
RoBERTa-Large, Chinese hub.Module(name='roberta_wwm_ext_chinese_L-24_H-1024_A-16')
RoBERTa-Base, Chinese hub.Module(name='roberta_wwm_ext_chinese_L-12_H-768_A-12')
BERT-Base, Uncased hub.Module(name='bert_uncased_L-12_H-768_A-12')
BERT-Large, Uncased hub.Module(name='bert_uncased_L-24_H-1024_A-16')
BERT-Base, Cased hub.Module(name='bert_cased_L-12_H-768_A-12')
BERT-Large, Cased hub.Module(name='bert_cased_L-24_H-1024_A-16')
BERT-Base, Multilingual Cased hub.Module(nane='bert_multi_cased_L-12_H-768_A-12')
BERT-Base, Chinese hub.Module(name='bert_chinese_L-12_H-768_A-12')
#加载数据集的作用,老reader了。
dataset = Baidu95()
reader = hub.reader.MultiLabelClassifyReader(
dataset=dataset,
vocab_path=module.get_vocab_path(),
max_seq_len=max_seq_len,
use_task_id=False)
metrics_choices = ['acc','f1']
优化器设置
strategy = hub.AdamWeightDecayStrategy(
learning_rate=5e-5,
weight_decay=0.01,
warmup_proportion=0.0,
lr_scheduler="linear_decay",
)
config = hub.RunConfig(use_cuda=True, num_epoch=5, batch_size=32, strategy=strategy)
运行模型
# Define a classfication finetune task by PaddleHub's API
pooled_output = outputs["pooled_output"]
feed_list = [
inputs["input_ids"].name,
inputs["position_ids"].name,
inputs["segment_ids"].name,
inputs["input_mask"].name
]
multi_label_cls_task = hub.MultiLabelClassifierTask(
data_reader=reader,
feature=pooled_output,
feed_list=feed_list,
num_classes=dataset.num_labels,
config=config)
# Finetune and evaluate by PaddleHub's API
# will finish training, evaluation, testing, save model automatically
multi_label_cls_task.finetune_and_eval()
预测:
import numpy as np
# 预测数据
data = [[d.text_a, d.text_b] for d in dataset.get_test_examples()]
# 预测标签
test_label = np.array([d.label for d in dataset.get_test_examples()])
# 预测
run_states = multi_label_cls_task.predict(data)
def inverse_predict_array(batch_result):
return np.argmax(batch_result, axis=2).T
results = [run_state.run_results for run_state in run_states]
predict_label=np.concatenate([inverse_predict_array(batch_result) for batch_result in results])
from sklearn.metrics import f1_score
print('f1 micro:{}'.format(f1_score(test_label,predict_label,average='micro')))
print('f1 samples:{}'.format(f1_score(test_label,predict_label,average='samples')))
print('f1 macro:{}'.format(f1_score(test_label,predict_label,average='macro')))
PaddleHub一键加载ERNIE
import paddlehub as hub
module = hub.Module(name="ernie")
模型名 PaddleHub Module
ERNIE, Chinese hub.Module(name='ernie')
ERNIE 2.0 Tiny, Chinese hub.Module(name='ernie_tiny')
ERNIE 2.0 Base, English hub.Module(name='ernie_v2_eng_base')
ERNIE 2.0 Large, English hub.Module(name='ernie_v2_eng_large')
RoBERTa-Large, Chinese hub.Module(name='roberta_wwm_ext_chinese_L-24_H-1024_A-16')
RoBERTa-Base, Chinese hub.Module(name='roberta_wwm_ext_chinese_L-12_H-768_A-12')
BERT-Base, Uncased hub.Module(name='bert_uncased_L-12_H-768_A-12')
BERT-Large, Uncased hub.Module(name='bert_uncased_L-24_H-1024_A-16')
BERT-Base, Cased hub.Module(name='bert_cased_L-12_H-768_A-12')
BERT-Large, Cased hub.Module(name='bert_cased_L-24_H-1024_A-16')
BERT-Base, Multilingual Cased hub.Module(nane='bert_multi_cased_L-12_H-768_A-12')
BERT-Base, Chinese hub.Module(name='bert_chinese_L-12_H-768_A-12')
构建reader
接着生成一个文本分类的reader,reader负责将dataset的数据进行预处理,首先对文本进行切词,接着以特定格式组织并输入给模型进行训练。
ClassifyReader的参数有以下三个:
dataset: 传入PaddleHub Dataset;
vocab_path: 传入ERNIE/BERT模型对应的词表文件路径;
max_seq_len: ERNIE模型的最大序列长度,若序列长度不足,会通过padding方式补到max_seq_len, 若序列长度大于该值,则会以截断方式让序列长度为max_seq_len;
sp_model_path: 传入 ERNIE tiny的subword切分模型路径;
word_dict_path: 传入 ERNIE tiny的词语切分模型路径;

reader = hub.reader.ClassifyReader(
dataset=dataset,
vocab_path=module.get_vocab_path(),
max_seq_len=128)
选择Fine-Tune优化策略
适用于ERNIE/BERT这类Transformer模型的迁移优化策略为AdamWeightDecayStrategy。
AdamWeightDecayStrategy的参数:
learning_rate: 最大学习率
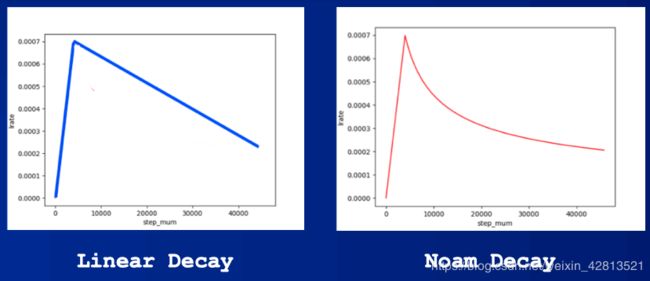
lr_scheduler: 有linear_decay和noam_decay两种衰减策略可选
warmup_proprotion: 训练预热的比例,若设置为0.1, 则会在前10%的训练step中学习率逐步提升到learning_rate
weight_decay: 权重衰减,类似模型正则项策略,避免模型overfitting
optimizer_name: 优化器名称
strategy = hub.AdamWeightDecayStrategy(
weight_decay=0.01,
warmup_proportion=0.1,
learning_rate=5e-5,
lr_scheduler="linear_decay",
optimizer_name="adam")
选择运行配置
在进行Finetune前,我们可以设置一些运行时的配置,例如如下代码中的配置,表示:
use_cuda:设置为False表示使用CPU进行训练。如果您本机支持GPU,且安装的是GPU版本的PaddlePaddle,我们建议您将这个选项设置为True;
num_epoch:Finetune时遍历训练集的次数,;
batch_size:每次训练的时候,给模型输入的每批数据大小为16,模型训练时能够并行处理批数据,因此batch_size越大,训练的效率越高,但是同时带来了内存的负荷,过大的batch_size可能导致内存不足而无法训练,因此选择一个合适的batch_size是很重要的一步;
log_interval:每隔10 step打印一次训练日志;
eval_interval:每隔50 step在验证集上进行一次性能评估;
checkpoint_dir:训练的参数和数据的保存目录;
strategy:Fine-tune策略;
use_data_parallel: 设置为False表示单卡训练;设置为True表示多卡训练
use_pyreader: 设置为False表示不使用py_reader读取数据;设置为True表示使用py_reader读取数据
config = hub.RunConfig(
use_cuda=True,
num_epoch=1,
checkpoint_dir="hub_ernie_text_cls_demo",
batch_size=32,
log_interval=10,
eval_interval=50,
use_pyreader=False,
use_data_parallel=False,
strategy=strategy)
组建Finetune Task
有了合适的预训练模型和准备要迁移的数据集后,我们开始组建一个Task。
获取module的上下文环境,包括输入和输出的变量,以及Paddle Program;
从输出变量中找到用于情感分类的文本特征pooled_output;
在pooled_output后面接入一个全连接层,生成Task;
TextClassifier Task的参数有:
data_reader:读取数据的reader;
config: 运行配置;
feature:从预训练提取的特征;
feed_list:program需要输入的变量;
num_classes:数据集的类别数量;
metric_choic:任务评估指标,默认为"acc"。metrics_choices支持训练过程中同时评估多个指标,作为最佳模型的判断依据,例如[“matthews”, “acc”],"matthews"将作为主指标,为最佳模型的判断依据;
inputs, outputs, program = module.context(
trainable=True, max_seq_len=128)
# Use "pooled_output" for classification tasks on an entire sentence.
pooled_output = outputs["pooled_output"]
feed_list = [
inputs["input_ids"].name,
inputs["position_ids"].name,
inputs["segment_ids"].name,
inputs["input_mask"].name,
]
cls_task = hub.TextClassifierTask(
data_reader=reader,
feature=pooled_output,
feed_list=feed_list,
num_classes=dataset.num_labels,
config=config,
metrics_choices=["acc"])
NOTE: Reader参数max_seq_len、moduel的context接口参数max_seq_len三者应该保持一致,最大序列长度max_seq_len是可以调整的参数,建议值128,根据任务文本长度不同可以调整该值,但最大不超过512。
开始Finetune
我们选择finetune_and_eval接口来进行模型训练,这个接口在finetune的过程中,会周期性的进行模型效果的评估,以便我们了解整个训练过程的性能变化。
run_states = cls_task.finetune_and_eval()
使用模型预测
当Finetune完成后,我们使用模型来进行预测,整个预测流程大致可以分为以下几步:
- 构建网络
- 生成预测数据的Reader
- 切换到预测的Program
- 加载预训练好的参数
- 运行Program进行预测

import numpy as np
inv_label_map = {val: key for key, val in reader.label_map.items()}
# Data to be prdicted
data = [[d.text_a, d.text_b] for d in dataset.get_test_examples()[:3]]
index = 0
run_states = cls_task.predict(data=data)
results = [run_state.run_results for run_state in run_states]
for batch_result in results:
# get predict index
batch_result = np.argmax(batch_result, axis=2)[0]
for result in batch_result:
print("%s\tpredict=%s" % (data[index][0], inv_label_map[result]))
index += 1
总的来说,PaddleHub完成迁移学习过程只需下图所展示的6步即可完成。
![]()