keras课程6:layers
1. 综述
layers是重点部分,该部分包含了各种网络结构以及激活函数等。下面一一讲解
2. 激活函数Activation
tf.keras.layers.Activation(activation, **kwargs)
因此参数activation为具体的激活函数。keras中activation参数的值一般取如下:
’elu’, ‘exponential’, ‘hard_sigmoind’, ‘linear’, ‘relu’, ‘selu’, ‘sigmoid’, ‘softmax’, ‘softplus’, ‘softsign’, ‘swish’, ‘tanh’,或者自定义激活函数
课程2中单独讲述了激活函数,当时是tf.keras.activation.relu(),而此时为tf.keras.layers.Activation(‘relu’)。这两者的有什么区别呢?
tf.keras.layers.Activation(‘relu’)常用于深度学习网络结构中,tf.keras.activation.relu()常用于数学运算。
def lstm(max_len, max_cnt, embed_size, embedding_matrix):
_input = Input(shape=(max_len,), dtype='int32')
_embed = Embedding(max_cnt, embed_size, input_length=max_len, weights=[embedding_matrix], trainable=False)(_input)
_embed = SpatialDropout1D(0.1)(_embed)
lstm_result = CuDNNLSTM(100, return_sequences=False)(_embed)
fc = Dropout(0.1)(lstm_result)
fc = Dense(13)(fc)
fc = Dropout(0.1)(fc)
preds = Activation('softmax')(fc) # 深度学习网络结构
model = Model(inputs=_input, outputs=preds)
return model
3. Dense
Dense即线性层,其结构如下:
tf.keras.layers.Dense(
units, activation=None, use_bias=True, kernel_initializer=‘glorot_uniform’,
bias_initializer=‘zeros’, kernel_regularizer=None, bias_regularizer=None,
activity_regularizer=None, kernel_constraint=None, bias_constraint=None,
**kwargs
)
各参数含义如下:
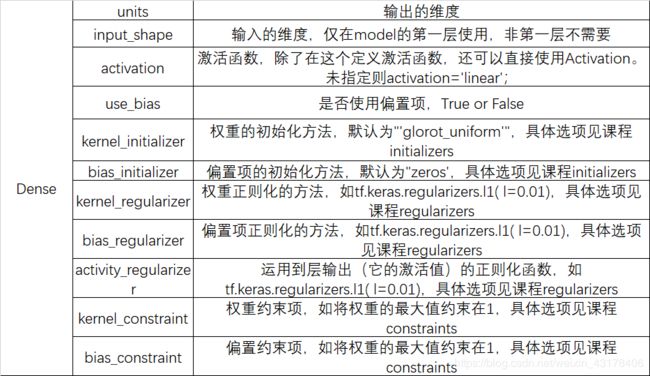
参数中regularizer是正则化项,kernel_regularizer就是对权重添加正则化项,以l2为例,对权重添加正则化项后,损失函数变为:

bias_regularizer原理相同(bias也可以看做是 ω \omega ω)。重点是activity_regularizer,该参数表示对输出项(激活项后的输出)添加正则化。个人理解添加后,损失函数变为如下:
∑ ∣ ∣ L ( y i ^ , y i ∣ ∣ 2 2 \sum||L(\hat{y_i}, y_i||_2^2 ∑∣∣L(yi^,yi∣∣22,个人猜测,未经源码验证。
权重和输出添加正则化的目的:
- 当对权重添加正则化后,权重的值会局限于某一范围内,使得原来很大的值相对变小
- 当我们需要输出很小时,虽然对权重添加了正则化(使得权重值变小)但由于x本身很大,输出仍然可能很大,因此,此时对输出添加权重项,使得输出变小。
constraint为约束项,比如最大权重约束,可以将权重的值约束到小于某个值,还可以将权重约到某一范围(小于等于x,大于等于y),具体约束方法见keras中的constraint。
注意:
- Dense 实现以下操作:output = activation(dot(input, kernel) + bias)其中 activation 是按逐个元素计算的激活函数,kernel是由网络层创建的权值矩阵,以及 bias 是其创建的偏置向量(只在 use_bias 为 True 时才有用)。
- Dense层的输入为(batch_size, …, input_dim),注意中间的省略号,说明中间还可以有很多维度,一般的,我们输入的是2D(batch_size, input_dim)
- Dense层的输出为(batch_size, …, units),units就是参数里指定的,对于2D输入,输出就是(batch_size, units)
4. Conv2D
本章讲述卷积神经网络。其默认表达如下:
tf.keras.layers.Conv2D(
filters, kernel_size, strides=(1, 1), padding=‘valid’, data_format=None,
dilation_rate=(1, 1), activation=None, use_bias=True,
kernel_initializer=‘glorot_uniform’, bias_initializer=‘zeros’,
kernel_regularizer=None, bias_regularizer=None, activity_regularizer=None,
kernel_constraint=None, bias_constraint=None, **kwargs
)
其参数解析如下:

其中padding的方式有两种,‘valid’/‘same’(不区分大小写)


- 注意:
- 输入:
- 当data_format为channels_last时,输入为(batch_size, rows, cols, channels)
- 当data_format为channels_first时,输入为(batch_size, channels, rows, cols)
- 输出:
- 当data_format为channels_last时,输出为(batch_size, new_rows, new_cols, filters)
- 当data_format为channels_first时,输出为(batch_size, filters, new_rows, new_cols)
- 输入:
5. MaxPool2D
最大池化层,结构如下:
tf.keras.layers.MaxPool2D(
pool_size=(2, 2), strides=None, padding=‘valid’, data_format=None, **kwargs
)
参数如下,具体可参考Conv2D


6. GlobalMaxPool2D
最大全局池化,结构如下:
tf.keras.layers.GlobalMaxPool2D(
data_format=None, **kwargs
)
data_format:channels_last or channels_first。默认为在〜/ .keras / keras.json中的Keras配置文件中找到的image_data_format值。 如果从未设置,那么默认是“ channels_last”。

7. AveragePooling2D
平均池化层,结构如下:
tf.keras.layers.AveragePooling2D(
pool_size=(2, 2), strides=None, padding=‘valid’, data_format=None, **kwargs
)


8. GlobalAveragePooling2D
全局平均池化
tf.keras.layers.GlobalAveragePooling2D(
data_format=None, **kwargs
)

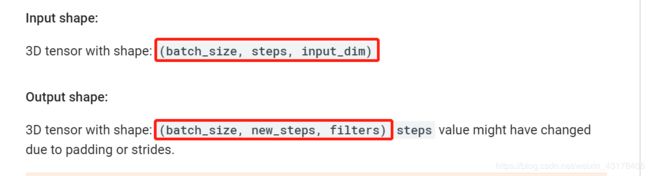
9. Conv1D
主要应用于textcnn,结构如下:
tf.keras.layers.Conv1D(
filters, kernel_size, strides=1, padding=‘valid’, data_format=‘channels_last’,
dilation_rate=1, activation=None, use_bias=True,
kernel_initializer=‘glorot_uniform’, bias_initializer=‘zeros’,
kernel_regularizer=None, bias_regularizer=None, activity_regularizer=None,
kernel_constraint=None, bias_constraint=None, **kwargs
)
参数的具体含义见Con2D,注意,这里的padding有三种选择"valid"/‘same’/‘causal’

10. MaxPool1D
tf.keras.layers.MaxPool1D(
pool_size=2, strides=None, padding=‘valid’, data_format=‘channels_last’,
**kwargs
)

一般地,一维卷积常用于textcnn模型,此时,池化层通常为全局最大池化或全局平均池化。如果非要用MaxPool1D,卷积层的输出(batch_size, new_step, filters)中的filters就是这里输入(batch_size, steps, features)的features
11. AveragePooling1D
同MaxPool1D
tf.keras.layers.AveragePooling1D(
pool_size=2, strides=None, padding=‘valid’, data_format=‘channels_last’,
**kwargs
)

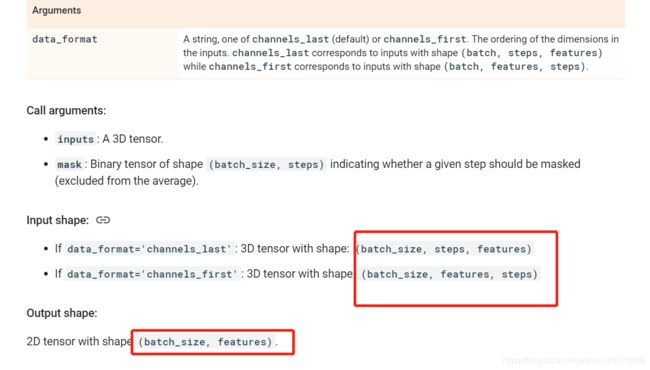
12. GlobalMaxPool1D
tf.keras.layers.GlobalMaxPool1D(
data_format=‘channels_last’, **kwargs
)

一维卷积层的输出(batch_size, new_step, filters)中的filters就是这里输入(batch_size, steps, features)的features
13. GlobalAveragePooling1D
同GlobalMaxPool1D
14 RNN相关
在keras中,关于RNN神经网络共有四个接口AbstractRNNCell、RNN、SimpleRNN、SimpleRNNCell。
14.1 SimpleRNNCell
其结构如下:
tf.keras.layers.SimpleRNNCell(
units, activation=‘tanh’, use_bias=True, kernel_initializer=‘glorot_uniform’,
recurrent_initializer=‘orthogonal’, bias_initializer=‘zeros’,
kernel_regularizer=None, recurrent_regularizer=None, bias_regularizer=None,
kernel_constraint=None, recurrent_constraint=None, bias_constraint=None,
dropout=0.0, recurrent_dropout=0.0, **kwargs
)
参数入下:

这里主要关注三个参数:
- units:决定了输出的维度。就是rnn结构中神经元的个数(可类比成DNN中的 ω \omega ω的维度)
- dropout:相比于Dense和Conv2D,SimpleRNN多了dropout,这里的dropout应用于输入的线性变换。
- recurrent_dropout:应用于循环状态的线性变换
从上面可以看出,dropout应用于线性变化,当然这个线性变化在不同模型中可以有不同的状态,如输入状态,循环状态。
一般来讲SimpleRNNCell需要搭配RNN使用(作为RNN cell参数的值),具体会在RNN中讲解,其简单案例如下所示:
inputs = np.random.random([32, 10, 8]).astype(np.float32)
rnn = tf.keras.layers.RNN(tf.keras.layers.SimpleRNNCell(4))
output = rnn(inputs) # The output has shape `[32, 4]`.
rnn = tf.keras.layers.RNN(
tf.keras.layers.SimpleRNNCell(4),
return_sequences=True,
return_state=True)
# whole_sequence_output has shape `[32, 10, 4]`.
# final_state has shape `[32, 4]`.
whole_sequence_output, final_state = rnn(inputs)
14.2 RNN
搭配SimpleRNNCell使用即可构成RNN模型。其结构如下:
tf.keras.layers.RNN(
cell, return_sequences=False, return_state=False, go_backwards=False,
stateful=False, unroll=False, time_major=False, **kwargs
)
参数如下:
- cell:RNN一个类的实例,其要求如下:
- call方法,参数为(input_at_t, states_at_t),返回(output_at_t, states_at_t_plus_1)
- state_size属性。可以是单个整数(单状态),在这种情况下,它是循环状态的大小。 这也可以是整数的列表/元组(每个状态一个大小)。 state_size也可以是TensorShape或TensorShape的元组/列表,以表示高维状态。
- 一个output_size属性。 它可以是单个整数或TensorShape,代表输出的形状。
- get_initial_state(inputs=None, batch_size=None, dtype=None) 方法
- return_sequences:bool,默认False,返回最后一个输出的最后一层还是最后一个输出的整个序列
- return_state:bool,默认False。True:返回hidden state之外,还要返回最后一个cell state状态
- go_backwards:bool默认为False。是否将输入序列倒序
- stateful:bool,默认False。是否使用有状态的RNN,具体含义见下
- unroll:bool,默认False。 如果为True,则将展开网络,否则将使用符号循环。 展开可以加快RNN的速度,尽管它往往会占用更多的内存。 展开仅适用于短序列
- time_major:bool,默认False,决定输入输出的格式,具体见下
- cell参数可以是SimpleRNNCell,这时就是我们平时使用的RNN模型。也可以是自定义的RNN模型,自定义RNN使用AbstractRNNCell,如何自定义见下
- 关于模型的输入和输出结构,由以下几个参数决定:return_sequence,return_state,go_backwards,time_major。
14.3 SimpleRNN
平时所用的RNN模型就用的这个API,结构如下:
tf.keras.layers.SimpleRNN(
units, activation=‘tanh’, use_bias=True, kernel_initializer=‘glorot_uniform’,
recurrent_initializer=‘orthogonal’, bias_initializer=‘zeros’,
kernel_regularizer=None, recurrent_regularizer=None, bias_regularizer=None,
activity_regularizer=None, kernel_constraint=None, recurrent_constraint=None,
bias_constraint=None, dropout=0.0, recurrent_dropout=0.0,
return_sequences=False, return_state=False, go_backwards=False, stateful=False,
unroll=False, **kwargs
)
参数如下:


关于模型的输入和输出结构,由以下几个参数决定:return_sequence,return_state,time_major。
- 当time_major为False,return_state为False,return_sequence为False时。输入(batch_size, timesteps, dim),输出(batch_size, units)
- 当time_major为False,return_state为False,return_sequence为True。输入(batch_size, timesteps, dim),输出(batch_size, timesteps, units)
- 当time_major为False,return_state为True,return_sequence为False。输入(batch_size, timesteps, dim),输出有两个,都是(batch_size, units)且两者的值都一样。因为第二个值就是最后时刻最后一个状态的输出。
- 当time_major为False,return_state为True,return_sequence为True。输入为(batch_size, timesteps, dim),输出有两个,一个为(batch_size, timesteps, units),另一个为(batch_size, units)。
- 当time_major=True时,就是将timesteps提前到最前边