深度学习笔记(38):第五课第二周第二次作业
前言
实现一个如图所示的句子情感判断器,找出对应的emoji(np序列把我小坑一下)
v1

# GRADED FUNCTION: sentence_to_avg
def sentence_to_avg(sentence, word_to_vec_map):
"""
Converts a sentence (string) into a list of words (strings). Extracts the GloVe representation of each word
and averages its value into a single vector encoding the meaning of the sentence.
Arguments:
sentence -- string, one training example from X
word_to_vec_map -- dictionary mapping every word in a vocabulary into its 50-dimensional vector representation
Returns:
avg -- average vector encoding information about the sentence, numpy-array of shape (50,)
"""
### START CODE HERE ###
# Step 1: Split sentence into list of lower case words (≈ 1 line)
words = (sentence.lower()).split()
# Initialize the average word vector, should have the same shape as your word vectors.
avg = np.zeros(50)
# Step 2: average the word vectors. You can loop over the words in the list "words".
for w in words:
avg += word_to_vec_map[w]
avg = avg/len(words)
### END CODE HERE ###
return avg
# GRADED FUNCTION: model
def model(X, Y, word_to_vec_map, learning_rate = 0.01, num_iterations = 400):
"""
Model to train word vector representations in numpy.
Arguments:
X -- input data, numpy array of sentences as strings, of shape (m, 1)
Y -- labels, numpy array of integers between 0 and 7, numpy-array of shape (m, 1)
word_to_vec_map -- dictionary mapping every word in a vocabulary into its 50-dimensional vector representation
learning_rate -- learning_rate for the stochastic gradient descent algorithm
num_iterations -- number of iterations
Returns:
pred -- vector of predictions, numpy-array of shape (m, 1)
W -- weight matrix of the softmax layer, of shape (n_y, n_h)
b -- bias of the softmax layer, of shape (n_y,)
"""
np.random.seed(1)
# Define number of training examples
m = Y.shape[0] # number of training examples
n_y = 5 # number of classes
n_h = 50 # dimensions of the GloVe vectors
# Initialize parameters using Xavier initialization
W = np.random.randn(n_y, n_h) / np.sqrt(n_h)
b = np.zeros((n_y,))
# Convert Y to Y_onehot with n_y classes
Y_oh = convert_to_one_hot(Y, C = n_y)
# Optimization loop
for t in range(num_iterations): # Loop over the number of iterations
for i in range(m): # Loop over the training examples
### START CODE HERE ### (≈ 4 lines of code)
# Average the word vectors of the words from the i'th training example
avg = sentence_to_avg(X[i],word_to_vec_map)
# Forward propagate the avg through the softmax layer
z = np.dot(W,avg) + b
a = softmax(z)
# Compute cost using the i'th training label's one hot representation and "A" (the output of the softmax)
cost = -np.sum(Y_oh[i]*np.log(a))
### END CODE HERE ###
# Compute gradients
dz = a - Y_oh[i]
dW = np.dot(dz.reshape(n_y,1), avg.reshape(1, n_h))
db = dz
# Update parameters with Stochastic Gradient Descent
W = W - learning_rate * dW
b = b - learning_rate * db
if t % 100 == 0:
print("Epoch: " + str(t) + " --- cost = " + str(cost))
pred = predict(X, Y, W, b, word_to_vec_map)
return pred, W, b
V2
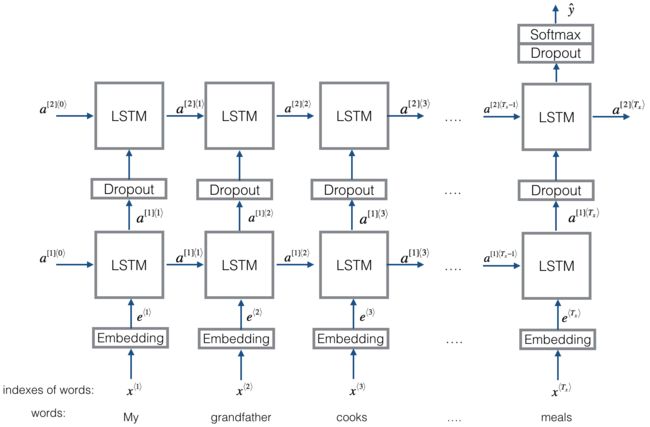
# GRADED FUNCTION: sentences_to_indices
def sentences_to_indices(X, word_to_index, max_len):
"""
Converts an array of sentences (strings) into an array of indices corresponding to words in the sentences.
The output shape should be such that it can be given to `Embedding()` (described in Figure 4).
Arguments:
X -- array of sentences (strings), of shape (m, 1)
word_to_index -- a dictionary containing the each word mapped to its index
max_len -- maximum number of words in a sentence. You can assume every sentence in X is no longer than this.
Returns:
X_indices -- array of indices corresponding to words in the sentences from X, of shape (m, max_len)
"""
m = X.shape[0] # number of training examples
### START CODE HERE ###
# Initialize X_indices as a numpy matrix of zeros and the correct shape (≈ 1 line)
X_indices = np.zeros((m,max_len))
for i in range(m): # loop over training examples
# Convert the ith training sentence in lower case and split is into words. You should get a list of words.
sentence_words =(X[i].lower()).split()
# Initialize j to 0
j = 0
# Loop over the words of sentence_words
for w in sentence_words:
# Set the (i,j)th entry of X_indices to the index of the correct word.
X_indices[i, j] = word_to_index[w]
# Increment j to j + 1
j = j+1
### END CODE HERE ###
return X_indices
# GRADED FUNCTION: pretrained_embedding_layer
def pretrained_embedding_layer(word_to_vec_map, word_to_index):
"""
Creates a Keras Embedding() layer and loads in pre-trained GloVe 50-dimensional vectors.
Arguments:
word_to_vec_map -- dictionary mapping words to their GloVe vector representation.
word_to_index -- dictionary mapping from words to their indices in the vocabulary (400,001 words)
Returns:
embedding_layer -- pretrained layer Keras instance
"""
vocab_len = len(word_to_index) + 1 # adding 1 to fit Keras embedding (requirement)
emb_dim = word_to_vec_map["cucumber"].shape[0] # define dimensionality of your GloVe word vectors (= 50)
### START CODE HERE ###
# Initialize the embedding matrix as a numpy array of zeros of shape (vocab_len, dimensions of word vectors = emb_dim)
emb_matrix = np.zeros((vocab_len,emb_dim))
# Set each row "index" of the embedding matrix to be the word vector representation of the "index"th word of the vocabulary
for word, index in word_to_index.items():
emb_matrix[index, :] = word_to_vec_map[word]
# Define Keras embedding layer with the correct output/input sizes, make it trainable. Use Embedding(...). Make sure to set trainable=False.
embedding_layer = Embedding(vocab_len,emb_dim,trainable = False )
### END CODE HERE ###
# Build the embedding layer, it is required before setting the weights of the embedding layer. Do not modify the "None".
embedding_layer.build((None,))
# Set the weights of the embedding layer to the embedding matrix. Your layer is now pretrained.
embedding_layer.set_weights([emb_matrix])
return embedding_layer
# GRADED FUNCTION: Emojify_V2
def Emojify_V2(input_shape, word_to_vec_map, word_to_index):
"""
Function creating the Emojify-v2 model's graph.
Arguments:
input_shape -- shape of the input, usually (max_len,)
word_to_vec_map -- dictionary mapping every word in a vocabulary into its 50-dimensional vector representation
word_to_index -- dictionary mapping from words to their indices in the vocabulary (400,001 words)
Returns:
model -- a model instance in Keras
"""
### START CODE HERE ###
# Define sentence_indices as the input of the graph, it should be of shape input_shape and dtype 'int32' (as it contains indices).
sentence_indices = Input(shape=input_shape,dtype='int32')
# Create the embedding layer pretrained with GloVe Vectors (≈1 line)
embedding_layer = pretrained_embedding_layer(word_to_vec_map, word_to_index)
# Propagate sentence_indices through your embedding layer, you get back the embeddings
embeddings = embedding_layer(sentence_indices)
# Propagate the embeddings through an LSTM layer with 128-dimensional hidden state
# Be careful, the returned output should be a batch of sequences.
X = LSTM (128, return_sequences = True)(embeddings)
# Add dropout with a probability of 0.5
X = Dropout(0.5)(X)
# Propagate X trough another LSTM layer with 128-dimensional hidden state
# Be careful, the returned output should be a single hidden state, not a batch of sequences.
X = LSTM (128, return_sequences = False)(X)
# Add dropout with a probability of 0.5
X = Dropout(0.5)(X)
# Propagate X through a Dense layer with softmax activation to get back a batch of 5-dimensional vectors.
X = Dense(5)(X)
# Add a softmax activation
X = Activation('softmax')(X)
# Create Model instance which converts sentence_indices into X.
model = Model(sentence_indices,X)
### END CODE HERE ###
return model