Practical Full Resolution Learned Lossless Image Compression
实用的全分辨率学习无损图像压缩
Fabian Mentzer Eirikur Agustsson Luc Van Gool
ETH Zurich, Switzerland 瑞士苏黎世联邦理工学院
摘要:
我们提出了第一个实用的学习型无损图像压缩系统L3C,并证明其性能优于流行的工程编解码器、PNG、WebP和JPEG2000。该方法的核心是一个用于自适应熵编码的完全并行的分层概率模型,可以实现端对端的优化。与最近的自回归离散概率模型(如PixelCNN)相比,我们的方法I)联合对图像分布以及学习的辅助表示进行建模,而不是只对RGB空间中的图像分布进行建模;2)只需要三个前向传递来预测所有像素的概率,而不是每个像素一个。因此,与最快的PixelCNN变体(MultiscalePixelCNN)相比,L3C在采样时获得了超过两个数量级的加速。此外,我们发现学习辅助表示是至关重要的,并大大优于预定义的辅助表示,如RGB金字塔。
1.引言
由于基于概率的离散生成模型学习像素上的概率分布,理论上可以用于无损图像压缩[40]。然而,最近关于使用深度神经网络进行学习压缩的研究只关注有损压缩[4,41,42,34,1,3,44]。实际上,关于离散生成模型的文献[46、45、35、32、20]在很大程度上忽略了作为无损压缩系统的应用,无论是比特率还是运行时间都没有与经典的编解码(如PNG[31]、WebP[47]、JPEG2000[38]和FLIF[39])进行比较。这并不奇怪,因为(无损)熵编码使用基于概率的离散生成模型意味着解码复杂度本质上等同于模型的采样复杂度,这使得许多最新的最先进的自回归模型,如PixelCNN[46]、PixelCNN++[35]和多尺度PixelCNN[32]不切实际,在一个GPU上需要几分钟或几个小时来生成中等大小的图像,通常小于256×256px(见表2)。这些模型的计算复杂度主要是由采样(从而解码)操作的顺序性造成的,其中需要按光栅扫描顺序计算图像的每个(子)像素的正向传递。
在本文中,我们解决了这些挑战(离散生成模型在无损压缩中需要花费大量时间),并开发了一个完全并行的学习型无损压缩系统,性能优于流行的经典系统PNG、WebP和JPEG2000。
我们的系统(见图1)基于完全并行的学习特征提取器和预测器的层次结构,这些特征提取器和预测器是为压缩任务联合训练的。我们的代码可以在网上找到。特征提取器的作用是建立辅助层次特征表示,帮助预测器对图像和辅助特征本身进行建模。我们的实验表明,学习特征表示是至关重要的,启发式(预定义)的选择,如多尺度RGB金字塔导致次优性能。
更详细地说,为了编码图像x,我们通过S个特征提取器E(S)和预测器D(S)来处理它。然后,我们在单次前向传播中并行处理,得到了对x和辅助特征z(s)的概率分布p的预测。然后将这些预测与自适应算术编码器一起使用,以获得x和辅助特征的压缩位流(第3.1节提供算术编码的介绍)。然而,算术解码器现在需要p来解码位流。D(S)从辅助特征z(S)的最小尺度出发,假设其先验一致,预测下一个尺度z(S - 1)的辅助特征的分布,从而从比特流中解码。预测和解码交替进行,直到算术解码器得到图像x。步骤见附录中的图A4。
在实际应用中,我们的模型只需要使用S = 3个特征提取器和预测器,因此在解码时,我们只需要结合自适应算术编码执行三个并行(像素上)前向传播。
我们的模型的并行特性使其解码速度比自回归模型快几个数量级,而学习使我们能够获得与最先进的工程无损编解码器具有竞争力的压缩率。
总之,我们的贡献如下:
- 我们提出一个完全并行分层概率模型,同时学习产生一个辅助特征表示帮助预测任务的特征提取器,以及建模所有变量的联合分布的预测模型(第3部分)。
- 我们表明,基于我们的对离散对数似然优化的非自回归概率模型的熵编码可以获得比WebP、JPEG2000和PNG更好的压缩率,而PNG的压缩率远远高于WebP和JPEG2000。我们的表现仅略好于最先进的FLIF,而在概念上要简单得多(第5.1节)。
- 同时,我们的模型在运行时复杂度和数量级上都比基于PixelCNN的方法快。特别是,我们的模型比PixelCNN++[35]快5.31·1e(4),比高速优化的MS-PixelCNN[32]快5.06·1e(2)(第5.2节)。
2.相关工作:
基于概率的生成模型:如前所述,本质上所有基于概率的离散生成模型都可以与算术编码器一起用于无损压缩。获得最先进性能的一组著名模型是自回归PixelRNN/PixelCNN的变体[46,45]。PixelRNN和PixelCNN将图像分布的像素组织成一个序列,分别对(所有)先前像素使用掩模卷积的RNN和CNN有条件地预测每个像素的分布。因此,这些模型需要的网络评估次数等于预测的子像素数(3·W·H)。PixelCNN++[35]在这方面进行了多方面的改进,包括对每个像素的联合分布进行建模,从而消除了对先前通道的限制,将前向传播减少到W·H。MS-PixelCNN[32]并行化PixelCNN通过减少像素块之间的依赖关系,用浅PixelCNN并行处理,需要O(logWH)次前向传播。[20]为PixelCNN配备了辅助变量(图像灰度版或RGB金字塔),以鼓励对高层特征建模,从而提高整体建模性能。[7,29]提出了类似于PixelCNN/PixelRNN的自回归模型,但它们还依赖于注意机制来增加感受野。
工程编解码器:著名的PNG[31]分两个阶段进行:首先用一个简单的自回归滤波器将图像可逆地转换为更可压缩的表示形式,该滤波器根据周围的像素更新像素,然后使用deflate算法[11]对图像进行压缩。WebP[47]使用了更多复杂的转换,包括使用整个图像片段来编码新的像素和自定义熵编码方案。JPEG2000[38]包含一种无损模式,其中tiles(块)在编码步骤之前被可逆地转换,而不是不可逆地删除频率。目前最先进的(非学习)算法是FLIF[39]。它依赖于强大的预处理和一种基于CABAC[33]的复杂熵编码方法MANIAC,该方法在编码过程中每个信道生成一个动态决策树作为自适应上下文模型。
有损压缩中的上下文模型:在有损压缩中,研究了上下文模型作为一种有效无损编码图像表示的方法。经典方法在[24,26,27,50,48]中进行了讨论。最近的学习方法包括[22,25,28],在这些方法中学习了关于潜在表示的浅自回归模型。[5]给出了一个有点类似于L3C的模型:它们的自动编码器类似于我们的第一个尺度,而hyper编码器/解码器类似于我们的第二个尺度。然而,由于他们训练有损图像压缩,他们的自动编码器可以直接预测RGB像素。此外,他们预测z(1)的不确定性σ而不是(logistics)物流的混合。最后,他们没有学习z(2)的概率分布,而是假设条目是i.i.d.,并且符合单变量非参数密度模型,而在我们的模型中,可以递归地训练和应用更多的阶段。
压缩的连续似然模型:连续似然模型的目标,如VAEs[19]和RealNVP[12],其中p(x’)为连续分布,与其离散对应关系密切。 特别地,通过设置x’=x+u,其中x为离散图像,u为均匀量化噪声,则p(x’)的连续似然是离散q(x) = Eu(p(x’))[40]似然的下界。然而,部署这样的模型进行压缩有两个挑战。首先,离散似然q(x)需要可用(这涉及到一个non-trivial(非平凡)的积分步骤)。此外,(自适应)算术编码的内存复杂度取决于q分解变量域的大小(参见第3.1节的(自适应)算术编码)。由于域在x中的像素数呈指数增长,除非q是可分解的,否则将其与自适应算术编码一起使用是不可行的。
3.方法
3.1 无损压缩
一般情况下,在无损压缩中,给出了一些符号流x,这些符号流由集合X = {1,…,|X|}根据概率质量函数p~独立地、同分布地画出(i.i.d)。目标是使用“code”将这个流编码为最小长度的位流,s.t.接收器可以从位流中解码符号。
3.2 框架

图1 L3C体系结构概述。特征提取器E(s)计算量化(Q)辅助层次特征表示z(1),…,z(S),与图像x的联合分布p(x,z(1),…,z(S)),通过非自回归预测器D(S)对联合分布进行建模。特征f (s)将信息汇总到s级,并用于预测下一个级别的p。

图2. 单个尺度s的架构细节。s = 1时,Ein(1)为被归一化为[1,1]的RGB图像x。所有垂直的黑线都是卷积,它们有Cf = 64个滤波器,除非下面写了用其他方式表示。卷积为stride 1,带有3×3个滤波器,除上述情况外(使用sSfF = stride s, filter f)。我们将预测器D(s+1)中的特征f (s+1)添加到D(s)的第一层(尺度之间的跳过连接)。灰色块是残差块,在右侧显示一次。C为z(s)的通道数,Cp(s - 1)为最终通道数,见第3.4节。特殊块用红色表示:U是pixelshuffling upsampling [37]。A*是第3.2节中描述的“atrous convolution(无效卷积)”层。我们使用热图来可视化z(s),参见第a .4节。
图2给出了一个尺度s的详细描述。与PixelCNN和PixelRNN等自回归模型不同,PixelCNN和PixelRNN将图像在子像素xt上的分布自回归分解为
![]()
而我们对所有子像素进行联合建模,引入一个学习的辅助特征表示层次结构z(1),…,z(S),来简化建模任务。

图A1:表示z(1),z (2),z(3)的前三个通道的可视化热图;,每个包含L={1,…,25}的值;例如:;25克,正如下面的刻度所示。

表2:我们方法(L3C)的采样时间与PixelCNN文献的比较。前两行是使用批大小(BS) 1得到的结果,其他行使用BS=30得到结果,因为这是在[32]中报告的。[*]:我们使用PixelCNN++[35]发布的代码获得的时间,我们使用同一GPU计算L3C (Titan X Pascal)。[y]:[32]中报道的时间,在Nvidia Quadro M4000 GPU上获得(没有可用代码)。[工]:为了更好地理解这些数字,我们将运行时与320x320图像上其他方法的线性插值运行时间进行了比较。
3.5 损失函数
我们现在准备定义损失,这是[35]中引入的离散Logistic混合损失的一般化。回顾第3.1节,我们的目标是对x和表示z(s)的真实联合分布建模,即p~(x,z (1),…,z (s))尽可能精确地使用我们的模型p(x,z (1),…,z (s))。因此,z(s) = F (s)(x)由学习的特征提取器块E(s)定义,且p(x,z (1),…,z (s))是离散化(条件)logistic混合模型的乘积,其参数通过f (s)定义,这些参数使用学习预测块D(s)计算。如第3.1节所述,编码x,z (1),…,z (s)到我们的模型p(x,z (1),…,z (s))所产生的预期编码成本为交叉熵
H(p~,p)。
因此,我们直接最小化H(~ p,p)关于特征提取器块E(s)和预测器块D(s)在样本上的参数。其中,给定N个训练样本x1,…,xN,设Fi(s)= F(s)(xi)为第i个样本的特征表示。我们最小化:

请注意,损失分解为不同表示的交叉熵的和。还请注意,这种损失对应于我们模型数据的负对数可能性,我们的模型通常采用生成模型文献(如[46])中的视角。
通过目标传播梯度 我们强调,与生成模型文献相比,我们学习了表示,传播梯度到E(s)和D(s),因为我们损失的每个部分都依赖于D(s+1),…,D(S)通过logistic分布的参数化和E(S),…,E(1)因为可微分的Q。因此,我们的网络可以自主学习权衡,该权衡是在a)使特征提取器E(s)的输出z(s)更容易被预测器D(s+1)估计和b)在z(s)输入足够的信息使得预测器D(s)来预测z(s - 1)。
3.1 无损压缩
一般情况下,在无损压缩中,给出了一些符号流x,这些符号流由集合X根据概率质量函数p~独立同分布地抽取出来的。目标是使用“code”将这个流编码为最小长度的位流,使得接收器可以从位流中解码符号。理想情况下,编码器最小化每个符号的期望比特数
![]()
其中l(j)为编码符号j的长度(即,更可能的符号应该得到更短的编码)。信息论为任何可能的编码提供(如[9])边界L~ >=H(~ p),其中H(~ p) = Ej~p[log ~ p(j)]为香农熵[36]。
算术编码 对于足够长的符号流,一种几乎达到下界H(~ p)的策略是算术编码[49]。将符号流编码为1个[0,1)之间的数。
自适应算术编码 与我们刚刚描述的i.i.d.设置相反,本文中我们感兴趣的是对自然图像的像素进行无损编码,这些像素已知是高度相关的,因此根本没有i.i.d.。设xt为图像x的子像素, p~img(x)为所有子像素的联合分布。然后我们可以考虑因式分解
![]()
现在,为了编码x,我们可以将子像素xt作为我们的符号流,并使用
![]()
编码第t个子像素。注意,这对应于在编码过程中改变前一段的p~ (j),一般称为自适应算术编码(AAC)[49]。 对于AAC,接收机还需要知道每一步变化的p~,即,它们必须是先验的,或者因式分解必须是casual(因果的)(如上所述),以便接收方可以从已经解码的符号计算它们。
交叉熵

给定某个p,我们可以通过最小化式(1)来最小化用p~分布的符号编码符号流所需的比特成本。
这自然可以推广到上一段中描述的非i.i.d的情况,用不同的p~(xt)和p(xt)对每个符号xt和最小化
![]()
下面几节将描述如何使用自然图像的pimg分层因果分解来有效地进行学习无损图像压缩(L3C)。
3.2 框架
与PixelCNN和PixelRNN等自回归模型不同,PixelCNN和PixelRNN在子像素xt上将图像分布的自回归分解为
![]()
我们对所有子像素进行联合建模,引入辅助特征表示的学习层次结构z(1),…,z(S)简化建模任务。我们将z(s)的维数固定为C×H’×W’,其中通道数C为超参数(在我们报告的模型中C = 5),和H’ =
H/(2exp(s)),W’=W/(2exp(s))。给定一个H×W维图像。具体地说,我们将图像x和特征表示z(s)的联合分布建模为

其中p(z(S))为均匀分布。特征表示可以手工设计或学习。具体来说,一方面,我们考虑z(s) = B2s(x)的RGB金字塔,其中B2s是具有子采样因子2s的双三次(空间)子采样算子。另一方面,我们认为学习表示z(s)=F(s)(x)使用一个特征提取器F(s)。我们使用图1中所示的层次模型使用组合F(s)=QE(s)···E(1),E(s)的特征提取器块,Q是一个标量可微量化函数(见3.3部分)。图1中的D(s)为预测块,我们将E(s)和D(s)参数化为卷积神经网络。
令z(0)=x,我们对所有s∈{0,…,S}的条件分布进行参数化为:
![]()
使用预测器特征
![]()
注意f(s+1)总结了z(S),…,z(s+1)的信息。
该预测器基于EDSR[23]的超分辨率架构,其动机是我们的预测任务与超分辨率有一定的关联,因为两者都是涉及空间上采样的密集预测任务。我们镜像预测器来获得特征提取器,并在不使用BatchNorm[16]的情况下遵循[23]。
3.6. 与MS-PixelCNN的关系
当我们的方法中的辅助特性z(s)被限制在一个非学习的RGB金字塔中时(参见第4节中的基线),这有点类似于MS-PixelCNN[32]。特别是,[32]结合了这样一个金字塔和向上扩展的网络,这些网络在我们的体系结构中扮演着与预测器相同的角色。然而,至关重要的是,他们依赖于将这些预测器与浅PixelCNN结合起来,并一次向上扩展一个维度(W×H->2W×H->2W×2H)。虽然它们的复杂度从PixelCNN[46]所需的O(WH)前向传播降低到了O(logWH),但实际上它们的方法仍然比我们的方法慢两个数量级(见第5.2节)。此外,我们强调这些相似性只适用于我们的RGB基线模型,而我们的最佳模型是通过与预测器联合训练的学习特征提取器训练获得的。
结论:
提出并评价了一个具有辅助特征表示的全并行层次概率模型。我们的L3C模型在所有数据集上都优于PNG、JPEG2000和WebP。此外,它显著优于依赖于预定义启发式特征表示的RGB共享基线和RGB基线,说明学习这些表示是至关重要的。此外,我们观察到,使用基于PixelCNN的方法无损压缩全分辨率图像的时间需要比L3C长2到5个数量级。
为了进一步改进L3C,未来的工作可以研究像素间的弱自回归形式和/或模型网络对当前图像的动态适应。此外,探索特定领域的应用也很有趣,例如医学图像数据。
代码:
oral presentation
先决条件代码:
克隆repo(回购协议),并创建一个conda环境如下:
conda create --name l3c_env python=3.7 pip --yes
conda activate l3c_env
我们需要PyTorch, CUDA和一些PIP包:
conda install pytorch torchvision cudatoolkit=10.0 -c pytorch
pip install -r pip_requirements.txt
为了测试我们的熵编码,您还必须安装torchac,如下所述。
说明:
- 我们使用Python 3.7和PyTorch 1.1测试这段代码
- 训练代码也适用于PyTorch 0.4,但是对于测试,我们使用了torchac模块,它需要PyTorch 1.0或更新版本才能构建,如下所示。
- 代码依赖于tensorboardX==1.2,尽管TensorBoard现在是PyTorch的一部分(从1.1开始)
发布的模型:
我们发布了以下经过训练的模型:

参见 Evaluation of Models,以了解如何对数据集进行评估。
训练:
要自己训练模型,您必须首先准备数据,如prepare Open Images train中所示。然后,使用以下命令之一,详细说明如下:

每个发布的模型都在泰坦Xp上接受了大约5天的训练。
注意:我们不提供多gpu训练的代码。对于nn.DataParallel,代码必须稍微改变:在net.py、EncOut、DecOut是namedtuple,它不受nn.DataParallel的支持。
评估:
要测试一个实验,请使用test.py。例如,要测试L3C和baseline,运行:
python test.py /path/to/logdir 0524_0001,0524_0002,0524_0003 /some/imgdir,/some/other/imgdir \
--names "L3C,RGB Shared,RGB" --recursive=auto
要使用熵编码器并获取编码/解码的时间,使用–write_to_files(这需要torchac,见下面):
python test.py /path/to/logdir 0524_0001 /some/imgdir --write_to_files=files_out_dir
python test.py -h提供了更多的flags(标志)。
结果:
在准备这个repo(应该是指这个代码说明)时,我们发现去掉PixelCNN++代码最初引入的损失中的一个近似值会稍微提高L3C的最终比特率,而基线的性能会稍微变差。
代码包含了没有近似的损失。我们注意到,arXiv v2与CVPR Camera Ready版本是一样的,并且在那里得到了近似的结果。
但是,如果使用提供的代码进行重新训练,就会得到新的结果。为了清晰起见,我们将发布的代码得到的新结果与Camera Ready中的结果进行了比较:

这里,bpsp OI表示Open Images Test中每子像素的比特数。
我们没有重新训练ImageNet32和ImageNet64模型。
代码的详细信息:
实验:
每当train.py执行时,就会启动一个新的实验。每个实验都基于一个特定的网络配置文件(存储在configs/ms中)和一个数据加载文件(存储在configs/dl中)。实验由log date惟一标识,log date就是日期和时间(例如0506_1107)。配置文件由fjcommon中的解析器解析,它允许分层级配置。此外,还有global_config.py,以通过-p标志传递附加参数来允许快速更改,这些参数在代码中随处可见,请参见下面。配置文件加上global_config标志指定了训练网络所需的所有参数。
当一个实验开始时,一个包含所有这些信息的目录作为LOG_DIR_ROOT传递给train.py(请参阅python train.py -h)。
例如,running
python train.py configs/ms/cr.cf configs/dl/oi.cf log_dir -p upsampling=deconv
结果生成一个文件夹log_dir,并在其中调用另一个文件夹
0502_1213 cr oi upsampling=deconv
检查点(权重)将存储在名为ckpts的子文件夹中。
然后,可以通过传递要log date到test.py来简单地评估这个实验。,加上一些图片文件夹:
python test.py logs 0502_1213 data/openimages_test,data/raise1k
我们在data/openimages_test和data/raise1k的图像中测试。
要使用另一个模型作为预训练模型,请使用–restore和–restore_restart:
python train.py configs/ll/cr.cf configs/dl/oi.cf logs --restore 0502_1213 --restore_restart
代码的命名VS论文

参见src/multiscale_network/multiscale.py中的注释。
代码结构:
代码是相当模块化的,因为它用于实验不同的东西。核心是MultiscaleBlueprint类,它具有以下主要功能:forward、get_loss、sample。它被MultiscaleTrainer和MultiscaleTester所使用。网络是由MultiscaleNetwork创建的,它将所需的所有PyTorch模块组合在一起。logistics loss的离散化混合在DiscretizedMixLogisticsLoss中,在代码中通常称为dmll或dmol。
对于位编码,有一个Bitcoding类,它使用ArithmeticCoding类,而算术编码类又使用我的torchac模块,用c++编写,如下所述。
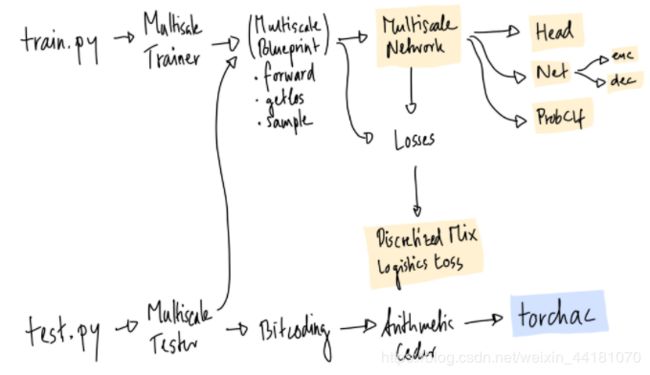
torchac模块:PyTorch中的快速熵编码
我们实现了一个熵编码模块作为PyTorch的c++扩展,因为目前还没有可用的快速Python熵编码模块。如果您计划为test.py使用–write_to_file标志(请参阅Evaluation of Models),则需要构建它。
实现是基于这篇博客文章,这意味着我们实现算术编码。它没有优化,但是,它比在纯python中做同样的事情要快得多(因为所有的位移位等等)。编码整个512 x 512图像只需0.202秒(见本文附录A)。
优化代码的一个很好的起点可能是range_coder.cc实现的TFC。
模块可以使用CUDA或不使用CUDA来构建。CUDA和非CUDA版本之间的唯一区别是:在CUDA中,来自torchac.py的_get_uint16_cdf通过一个简单/非优化的CUDA内核(torchac_kernel.cu)完成,它有一个好处:我们可以直接写入共享内存!这节省了从GPU到CPU的昂贵复制步骤。
然而,用CUDA编译可能会很麻烦。在我们的机器上,它与比版本5更新但比版本6更老的GCC(使用5.5进行测试),结合nvcc 9使用。我们没有测试其他配置,但是它们可以工作。如果您对其他配置工作(或不工作)有深入了解,请评论。
主要部分(算术编码),总是在CPU上。
编译:
确保最近的gcc在$PATH中可用(运行 gcc --version,用5.5进行测试)。对于CUDA,确保nvcc -V给出所需的版本(使用9.0进行测试)。
然后做:
conda activate l3c_env
cd src/torchac
COMPILE_CUDA=auto python setup.py
- COMPILE_CUDA=auto:如果gcc在5到6之间,并且nvcc 9是可用的,则使用CUDA
- COMPILE_CUDA=force:使用CUDA,不要检查gcc或nvcc
- COMPILE_CUDA=no: 不适用CUDA
这将在pip中安装一个名为torchac-backend-cpu或torchac-backend-gpu的包。要测试它是否有效,您可以这样做:
conda activate l3c_env
cd src/torchac
python -c "import torchac"
它不应该打印任何东西。
采样:
要从L3C取样,使用test.py与–sample:
python test.py /path/to/logdir 0524_0001 /some/imgdir --sample=samples
这将在目录samples中生成输出。每个图像,你会得到类似的东西
# Ground Truth
0_IMGNAME_3.549_gt.png
# Sampling from RGB scale, resulting bitcost 1.013bpsp
0_IMGNAME_rgb_1.013.png
# Sampling from RGB scale and z1, resulting bitcost 0.342bpsp
0_IMGNAME_rgb+bn0_0.342.png
# Sampling from RGB scale and z1 and z2, resulting bitcost 0.121bpsp
0_IMGNAME_rgb+bn0+bn1_0.121.png
参见论文5.4节。(“Sampling Representations”)。
使用L3C压缩图像:
要对单个图像进行编码/解码,请使用l3c.py。这需要torchac:
# Encode to out.l3c
python l3c.py /path/to/logdir 0524_0001 enc /path/to/img out.l3c
# Decode from out.l3c, save to decoded.png
python l3c.py /path/to/logdir 0524_0001 dec out.l3c decoded.png
为训练准备开放的图像:
选择一:简单的方法
使用prep_openimages.sh脚本。在Python 3、skimage (pip install scikit-image, 0.13.1版本测试过)和awscli (pip install awscli)的环境中运行它:
cd src
./prep_openimages.sh
这将下载所有图像到DATA_DIR。确保有足够的空间,因为这个脚本将创建大约300gb的数据。而且,它可能会运行几个小时。
在./prep_openimages.sh完成之后,所有内容都在DATA_DIR/train_oi和DATA_DIR/val_oi中。按照./prep_openimages.sh打印的说明更新配置文件。您可以使用rm -rf DATA_DIR/download和rm -rf DATA_DIR/imported来释放一些空间。
选择二:一步一步来
1.下载 Open Images training sets and validation set,我们使用0、1、2部分,加上验证集:
aws s3 --no-sign-request cp s3://open-images-dataset/tar/train_0.tar.gz train_0.tar.gz
aws s3 --no-sign-request cp s3://open-images-dataset/tar/train_1.tar.gz train_1.tar.gz
aws s3 --no-sign-request cp s3://open-images-dataset/tar/train_2.tar.gz train_2.tar.gz
aws s3 --no-sign-request cp s3://open-images-dataset/tar/validation.tar.gz validation.tar.gz
2.解压缩到一个文件夹,比如data。现在应该有了data/train_0、data/train_1、data/train_2以及data/validation。
3.(可选)要执行与本文相同的预处理,请运行以下命令。注意,它需要skimage包。为了加快速度,您可以通过完成task_array.sh在某些服务器上分发它。见import_train_images.py。
python import_train_images.py data train_0 train_1 train_2 validation
4.将所有(预处理的)图像放到一个训练和一个验证文件夹中,比如data/train_oi和data/validation_oi。
5.(可选)如果您使用的是慢速文件系统,它有助于data/train_oi的内容的缓存。运行
cd src
export CACHE_P="data/cache.pkl" # <--- Change this
export PYTHONPATH=$(pwd)
python dataloaders/images_loader.py update data/train_oi "$CACHE_P" --min_size 128
min_size确保跳过较小的图像。注意:如果跳过此步骤,请确保训练文件夹中没有尺寸小于128的文件。如果他们在那里,训练可能会崩溃。
6.更新数据加载配置configs/dl/oi.cf: 设置train_imgs_glob = ‘data/train_oi’(或您使用的任何文件夹)。如果您执行了前面的步骤,请设置image_cache_pkl = 'data/cache。如果没有,设置image_cache_pkl = None。最后,更新val_glob = ‘data/validation_oi’。
7.(可选)有一个固定的验证图像来监视训练是有帮助的。您可以将任何图像放在src/train/fixedimg.jpg中,它将用于此目的(请参阅multiscale_train .py)。
代码的未来工作:
添加对nn.DataParallel的支持
采用PyTorch的TensorBoard支持,而不是pip包。
论文勘误表:
p.6:“在ImageNet32/64上,我们将批大小增加到120[…]。” —> 批大小实际上也是30,就像其他实验一样。
p.13、图A2:预测因子D(1)之间不应该有箭头,因为我们只训练了一个预测因子。
引用:
如果您使用本文发布的研究成果,请引用本文:
@inproceedings{mentzer2019practical,
Author = {Mentzer, Fabian and Agustsson, Eirikur and Tschannen, Michael and Timofte, Radu and Van Gool, Luc},
Booktitle = {Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR)},
Title = {Practical Full Resolution Learned Lossless Image Compression},
Year = {2019}}