多种方式爬取猫眼电影TOP100
最近开始学习爬虫,用的是崔庆才老师的教程,其中第一个实战就是爬取猫眼电影的TOP100,使用的是requests+re。但我觉得re有点复杂,于是探索了一下用其他解析库来爬取。
爬取思路:
首先我要爬取的网站为:https://maoyan.com/board/4?offset=,当翻到第二时网址变成了https://maoyan.com/board/4?offset=10,第三页网址时变成了https://maoyan.com/board/4?offset=20,所以要爬取的十页的话只要写一个for循环,让第一页后面逐一加10就行了。
网页的构造:
网页的源代码如下图,可以看到一部电影的信息是存放在一个dd节点中,所以只要把所有的dd节点全部爬取下来,然后循环遍历就行了。要提取的信息中电影名在p节点下的a节点中,主演在class为star的p节点中,上映时间类似于主演,评分这里需要注意的是它在两个不同的i节点中。

本文使用的IDE是pycharm或者jupyter。
1、requests+re爬取
直接贴上崔庆才老师的代码了,感觉网上一搜到处都是这一段:
import json
import requests
from requests.exceptions import RequestException
import re
import time
def get_one_page(url):
try:
headers = {
'User-Agent' : 'Mozilla/5.0 (Macintosh; Inter Mac OS X 10_13_3) Applewebkit/537.36 (KHTML, like Gecko) Chrome/65.0.3325.162 Safari/537.36'
}
response = requests.get(url, headers = headers)
if response.status_code == 200:
return response.text
return None
except RequestException:
return None
def parse_one_page(html):
pattern = re.compile('.*?board-index.*?>(\d+).*?data-src="(.*?)".*?name">(.*?).*?star">(.*?).*?releasetime">(.*?)' +
'.*?integer">(.*?).*?fraction">(.*?).*? ', re.S)
items = re.findall(pattern, html)
for item in items:
yield {
'index' : item[0],
'image' : item[1],
'title' : item[2],
'actor' : item[3].strip()[3:],
'time' : item[4].strip()[5:],
'score' : item[5] + item[6]
}
def write_to_file(content):
with open(r'C:\Users\juno\Desktop\PYTHOY\reptile-python3\result.txt', 'a', encoding='utf-8') as f:
f.write(json.dumps(content, ensure_ascii= False) + '\n')
def main(offset):
url = 'https://maoyan.com/board/4?offset=' + str(offset)
html = get_one_page(url)
for item in parse_one_page(html):
print(item)
write_to_file(item)
if __name__ == "__main__":
for i in range(10):
main(offset=i * 10)
time.sleep(1)
2、requests+pyqyery爬取
首先,导入库和对网页进行解析,这部分很简单,和崔老师的也一样:
import requests
from pyquery import PyQuery as pq
import pandas as pd
import time
def get_one_page(url):
headers = {
'User-Agent' : 'Mozilla/5.0 (Macintosh; Inter Mac OS X 10_13_3) Applewebkit/537.36 (KHTML, like Gecko) Chrome/65.0.3325.162 Safari/537.36'
}
response = requests.get(url, headers = headers)
return response.text
然后,对单个页面进行解析,提取dd节点,使用items将其构造成可遍历的对象。我一开始提取的时候,总是想着直接就提取要的信息,然后一提取就是十部电影名+十部电影主演等等,然后一一用for循环进行提取,工作量大不说,还总是报错,实在是太蠢了。
def parse_one_page(html):
doc = pq(html)
docs = doc('dd')
for i in docs.items():
name = i.find('.name').text()
star = i.find('.star').text().strip()[3:]
time = i.find('.releasetime').text().strip()[5:]
score = i.find('.score').text()
maoyan.append([name, star, time, score])
然后写一下主函数,主要的功能是为了遍历循环,提出100部电影,然后进行存储。关于为什么用DataFrame数据类型,首先是我稍微熟悉一点,然后在jupyter中比较好看,虽然这里不是使用的jupyter。
def main(offset):
url = 'https://maoyan.com/board/4?offset=' + str(offset)
html = get_one_page(url)
parse_one_page(html)
if __name__ == "__main__":
maoyan = []
for i in range(0, 100, 10):
main(offset = i)
time.sleep(1)
res = pd.DataFrame(maoyan, columns=["电影名称", "主演", "上映时间", "评分"])
res.to_csv("maoyan.csv")
最后看一下提取的结果,如果用excel打开csv文件出现乱码,那就是编码方式不对。更改编码方式的方法是:数据——新建查询——从文件——从CSV——(找到刚刚保存的maoyan.csv文件)——文件原始格式下找到utf-8——加载,最终得到如下结果:
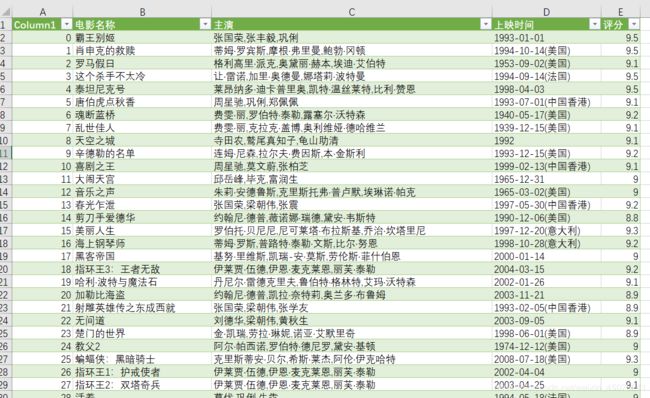
其实这只是一个小爬虫,不用写成多个函数的形式,但是函数的形式显得更加规范和清晰。直接在jupyter下写的如下:
import requests
from pyquery import PyQuery as pq
import pandas as pd
import time
maoyan = []
for i in range(0, 100, 10):
url = 'https://maoyan.com/board/4?offset=' + str(i)
headers = {
'User-Agent' : 'Mozilla/5.0 (Macintosh; Inter Mac OS X 10_13_3) Applewebkit/537.36 (KHTML, like Gecko) Chrome/65.0.3325.162 Safari/537.36'
}
response = requests.get(url, headers = headers)
doc = pq(response.text)
docs = doc('dd')
for i in docs.items():
name = i.find('.name').text()
star = i.find('.star').text().strip()[3:]
time = i.find('.releasetime').text().strip()[5:]
score = i.find('.score').text()
maoyan.append([name, star, time, score])
res = pd.DataFrame(maoyan, columns = ["电影名称", "主演", "上映时间", "评分"])
res
结果是这样的:
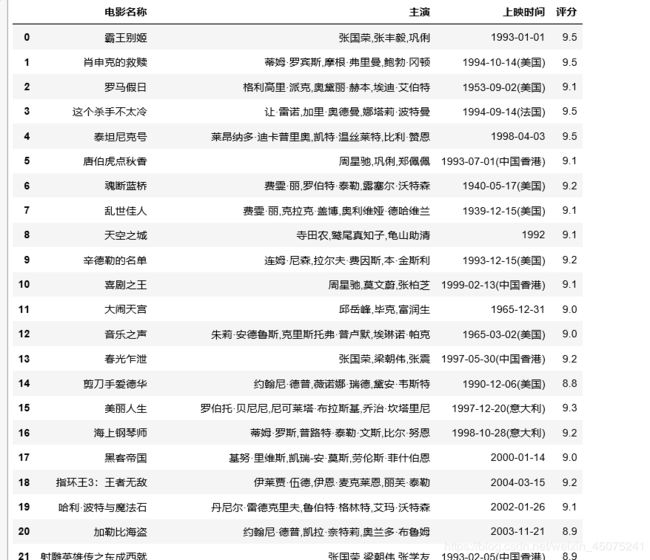
3、requests+xpath爬取
使用xpath的部分就直接在jupyter中写了。使用xpath进行解析时,需要使用lxml的etree模块中HTML将获取的源码构建成可以用xpath解析的对象。xpath进行信息提取和文件的查询提取很类似,但是需要主要的是每一个节点都要看仔细,比如我在提取电影名称的时候,一开始直接就在class为name的p节点中提取文本,结果什么都没有,看了半天才看清文本在下面的a节点中。还需要注意的用xpath提取的是一个列表类型,后面还行加一个列表的索引,来提取信息。
import requests
from lxml import etree
import pandas as pd
url = "https://maoyan.com/board/4?offset="
headers = {
"User-Agent" : "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/74.0.3729.131 Safari/537.36"
}
response = requests.get(url, headers = headers).text
html = etree.HTML(response)
maoyan = []
for i in range(0, 100, 10):
url = 'https://maoyan.com/board/4?offset=' + str(i)
headers = {
'User-Agent' : 'Mozilla/5.0 (Macintosh; Inter Mac OS X 10_13_3) Applewebkit/537.36 (KHTML, like Gecko) Chrome/65.0.3325.162 Safari/537.36'
}
response = requests.get(url, headers = headers)
html = etree.HTML(response.text)
res = html.xpath('//div[@class="content"]//dd')
for result in res:
name = result.xpath('.//p[@class="name"]/a/@title')[0]
star = result.xpath('.//p[@class="star"]/text()')[0].strip()[3:]
time = result.xpath('.//p[@class="releasetime"]/text()')[0].strip()[5:]
score = result.xpath('.//p//i[@class="integer"]/text()')[0] + result.xpath('.//p//i[@class="fraction"]/text()')[0]
maoyan.append([name, star, time, score])
t100 = pd.DataFrame(maoyan, columns = ["电影名称", "主演", "上映时间", "评分"])
t100
提取的结果如下,和使用pyquery没啥区别。
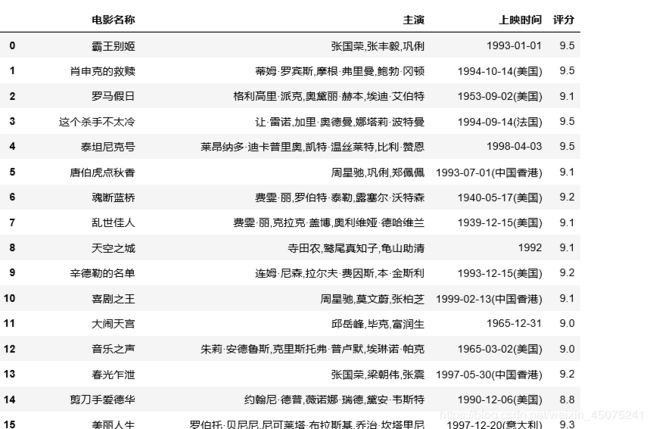
总结一下,完成这部分的编写,让我对于pyquery和xpath有了一定的了解。看书练习的时候都是解析一些自己编的超短的html,没啥感觉,实际用起来问题还是挺多的,还是多练习。