Faster RCNN CPU模式下进行训练
一、首先参照博客http://blog.csdn.net/qq_14975217/article/details/51495844
对py-faster-rcnn内的roi_pooling_layer和smooth_L1_loss_layer进行替换并重新编译,编译过程参考https://github.com/neuleaf/faster-rcnn-cpu 和 http://www.cnblogs.com/justinzhang/p/5386837.html
二、修改相关文件
训练过程参考:http://www.cnblogs.com/CarryPotMan/p/5390336.html
http://blog.csdn.net/sinat_30071459/article/details/51332084
1)下载VOC2007数据集
提供一个百度云地址:http://pan.baidu.com/s/1mhMKKw4
解压,然后,将该数据集放在py-faster-rcnn\data下,用你的数据集替换VOC2007数据集。(替换Annotations,ImageSets和JPEGImages)
(用你的Annotations,ImagesSets和JPEGImages替换py-faster-rcnn\data\VOCdevkit2007\VOC2007中对应文件夹)
2)下载ImageNet数据集下预训练得到的模型参数(用来初始化)
提供一个百度云地址:http://pan.baidu.com/s/1hsxx8OW
解压,然后将该文件放在py-faster-rcnn\data下
下面是训练前的一些修改。
3)如果是训练自己的数据集还需要对配置文件做一些修改,本文完全用的VOC的数据集,所以没有做修改,在接下来训练自己的数据集的时候会再重新写一篇教程
4)为防止与之前的模型搞混,训练前把output文件夹删除(或改个其他名),还要把py-faster-rcnn/data/cache中的文件和
py-faster-rcnn/data/VOCdevkit2007/annotations_cache中的文件删除(如果有的话)。
至于学习率等之类的设置,可在py-faster-rcnn/models/pascal_voc/ZF/faster_rcnn_alt_opt中的solve文件设置,迭代次数可在py-faster-rcnn\tools的train_faster_rcnn_alt_opt.py中修改:
max_iters = [80000, 40000, 80000, 40000]
分别为4个阶段(rpn第1阶段,fast rcnn第1阶段,rpn第2阶段,fast rcnn第2阶段)的迭代次数。可改成你希望的迭代次数。如果改了这些数值,最好把py-faster-rcnn/models/pascal_voc/ZF/faster_rcnn_alt_opt里对应的solver文件(有4个)也修改,stepsize小于上面修改的数值。
5)开始训练,按照教程输入
./experiments/scripts/faster_rcnn_alt_opt.sh 0 ZF pascal_voc
会出现错误的情况:
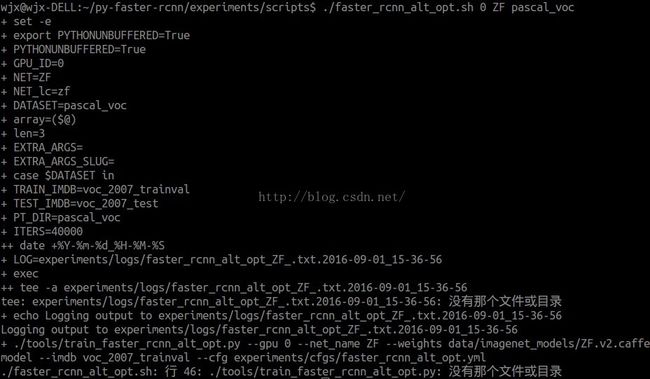
找不到相应的目录,找了半天的错误也没法解决问题,查看faster_rcnn_alt_opt.sh的内容发现是启动
./tools/train_faster_rcnn_alt_opt.py
并给train_faster_rcnn_alt_opt.py传递参数,所以放弃脚本启动的方式,直接在终端输入以下 的命令进行启动
cd /home/wjx/py-faster-rcnn/toolspython train_faster_rcnn_alt_opt.py --gpu 0 --net_name ZF --weights /home/wjx/py-faster-rcnn/data/imagenet_models/ZF.v2.caffemodel --cfg /home/wjx/py-faster-rcnn/experiments/cfgs/faster_rcnn_alt_opt.yml --imdb voc_2007_trainval
出现下面的错误:在cpu only 模式下无法用GPU进行训练

解决方案:打开train_faster_rcnn_alt_opt.py,可以看到定义输入参数的函数,把第34,35,36定以GPU模式训练的部分注释掉,如下面黄色的部分。
def parse_args():"""Parse input arguments"""parser = argparse.ArgumentParser(description='Train a Faster R-CNN network')#parser.add_argument('--gpu', dest='gpu_id',# help='GPU device id to use [0]',# default=0, type=int)parser.add_argument('--net_name', dest='net_name',help='network name (e.g., "ZF")',default=None, type=str)parser.add_argument('--weights', dest='pretrained_model',help='initialize with pretrained model weights',default=None, type=str)parser.add_argument('--cfg', dest='cfg_file',help='optional config file',default=None, type=str)parser.add_argument('--imdb', dest='imdb_name',help='dataset to train on',default='voc_2007_trainval', type=str)parser.add_argument('--set', dest='set_cfgs',help='set config keys', default=None,nargs=argparse.REMAINDER)
重新开始训练,输入下面的指令:
python train_faster_rcnn_alt_opt.py --net_name ZF --weights /home/wjx/py-faster-rcnn/data/imagenet_models/ZF.v2.caffemodel --cfg /home/wjx/py-faster-rcnn/experiments/cfgs/faster_rcnn_alt_opt.yml --imdb voc_2007_trainval
出现下面的问题:
由于注释掉gpu参数部分,所以下面的程序中出现gpu_id会出现错误,所以把train_faster_rcnn_alt_opt.py第214行注释掉
重新开始训练,出现下面的错误:
和上面的错误一样,cpu模式的问题,解决方法:将sh文件里面关于gpu_id的都注释掉。
然后,将train_faster_rcnn_alt_opt.py文件第103行caffe.set_mode_gpu()改为caffe.set_mode_cpu(),才能进行训练
除此之外,如果用alt-opt方式进行训练,需要进入/home/wjx/py-faster-rcnn/models/pascal_voc/ZF/faster_rcnn_alt_opt文件夹下将四个solver文件夹里里面涉及路径的改到绝对路径,否则会报错,如下:
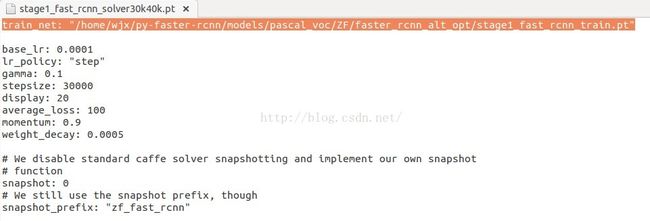
前面提到faster_rcnn_alt_opt.sh无法启动训练,后修改成如下的代码可以进行训练:
#!/bin/bash# Usage:# ./experiments/scripts/faster_rcnn_alt_opt.sh GPU NET DATASET [options args to {train,test}_net.py]# DATASET is only pascal_voc for now## Example:# ./experiments/scripts/faster_rcnn_alt_opt.sh 0 VGG_CNN_M_1024 pascal_voc \# --set EXP_DIR foobar RNG_SEED 42 TRAIN.SCALES "[400, 500, 600, 700]"set -xset -eexport PYTHONUNBUFFERED="True"GPU_ID=$1NET=$2NET_lc=${NET,,}DATASET=$3array=( $@ )len=${#array[@]}EXTRA_ARGS=${array[@]:3:$len}EXTRA_ARGS_SLUG=${EXTRA_ARGS// /_}case $DATASET inpascal_voc)TRAIN_IMDB="voc_2007_trainval"TEST_IMDB="voc_2007_test"PT_DIR="pascal_voc"ITERS=40000;;coco)echo "Not implemented: use experiments/scripts/faster_rcnn_end2end.sh for coco"exit;;*)echo "No dataset given"exit;;esacLOG="/home/wjx/py-faster-rcnn/experiments/logs/faster_rcnn_alt_opt_${NET}_${EXTRA_ARGS_SLUG}.txt.`date +'%Y-%m-%d_%H-%M-%S'`"exec &> >(tee -a "$LOG")echo Logging output to "$LOG"#time ./tools/train_faster_rcnn_alt_opt.py --gpu ${GPU_ID} \time cd /home/wjx/py-faster-rcnn/tools/python train_faster_rcnn_alt_opt.py --net_name ${NET} \--weights /home/wjx/py-faster-rcnn/data/imagenet_models/${NET}.v2.caffemodel \--imdb ${TRAIN_IMDB} \--cfg /home/wjx/py-faster-rcnn/experiments/cfgs/faster_rcnn_alt_opt.yml \${EXTRA_ARGS}set +xNET_FINAL=`grep "Final model:" ${LOG} | awk '{print $3}'`set -xtime cd /home/wjx/py-faster-rcnn/tools/test_net.py --def /home/wjx/py-faster-rcnn/models/${PT_DIR}/${NET}/faster_rcnn_alt_opt/faster_rcnn_test.pt \--net ${NET_FINAL} \--imdb ${TEST_IMDB} \--cfg /home/wjx/py-faster-rcnn/experiments/cfgs/faster_rcnn_alt_opt.yml \${EXTRA_ARGS}
启动训练输入以下的代码:
./faster_rcnn_alt_opt.sh 0 ZF pascal_voc
说明:
一、第一个参数实际的意义是GPU的编号,但是在CPU的模式下进行训练的话此参数没有任何意义,因为关于gpu_id的代码已经在上面注释掉了。
二、原始参数在CPU下进行训练会出现下面的情况,loss=-nan
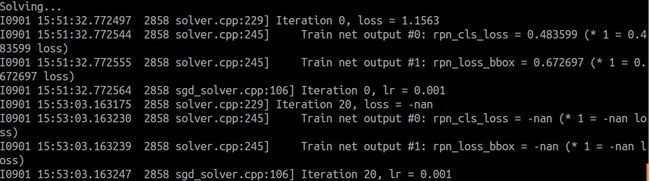
可能的原因分析:按GPU的学习率在CPU上进行训练,CPU的速度可能跟不上
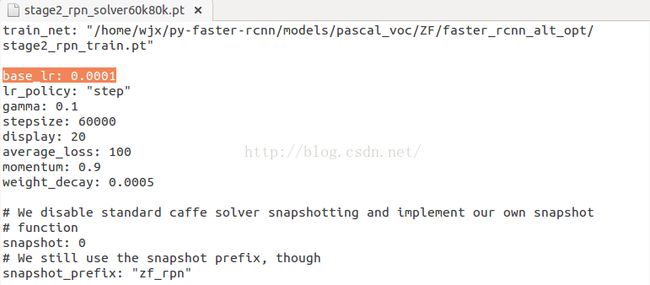
解决方法:把/home/wjx/py-faster-rcnn/models/pascal_voc/ZF/faster_rcnn_alt_opt文件夹下将四个solver文件里面的base_lr由0.001调小一点,调节成0.0001后开始训练,不会出现上面的问题。参考:http://blog.csdn.net/kuaitoukid/article/details/42120961
最后,训练好的模型会保存在~/py-faster-rcnn/output/文件夹下