matchzoo中文支持研究笔记
在几个公众号中都看到有matchzoo的推荐,是一个通用的文本匹配工具包,主要是几种最新的深度学习文本匹配模型,到本篇博客为止,这里记录下自己在看matchzoo中文支持研究的笔记,原github地址:https://github.com/NTMC-Community/MatchZoo
以github的tutorials为例:
import matchzoo as mz
task = mz.tasks.Ranking()
print(task)
train_raw = mz.datasets.qa.load_data(stage='train', task=task) #qa是datasets下新建的包,放置中文数据
test_raw = mz.datasets.qa.load_data(stage='test', task=task)
print(train_raw.left.head())
print(train_raw.right.head())
print(train_raw.relation.head())
print(train_raw.frame().head()) #数据格式如下图3
emb = mz.embedding.load_from_file(mz.datasets.embeddings.EMBED_CPWS,mode='word2vec') #加载word2vec词向量
model_class = mz.models.ArcI
model, preprocessor, data_generator_builder, embedding_matrix = mz.auto.prepare(
task=task,
model_class=model_class,
data_pack=train_raw,
embedding=emb
)
print(model.params) #展示模型中可调参数
model.params['mlp_num_units'] = 3 #直接调整参数
print("embedding_matrix: \n",type(embedding_matrix),'\n',embedding_matrix)
preprocessor._units = [
mz.preprocessors.units.tokenize_ch.Tokenize(),
# mz.preprocessors.units.lowercase.Lowercase(), #preprocessor中数据预处理单元修改,可直接赋值
mz.preprocessors.units.punc_removal.PuncRemoval(),
]
# preprocessor.fit(train_raw)
train_processed = preprocessor.transform(train_raw, verbose=0)
test_processed = preprocessor.transform(test_raw, verbose=0)
# vocab_unit = preprocessor.context['vocab_unit'] #此部分是为了显示处理过程
# print('Orig Text:', train_processed.left.loc['L-0']['text_left'])
# sequence = train_processed.left.loc['L-0']['text_left']
# print('Transformed Indices:', sequence)
# print('Transformed Indices Meaning:',
# '/'.join([vocab_unit.state['index_term'][i] for i in sequence]))
train_gen = data_generator_builder.build(train_processed)
test_gen = data_generator_builder.build(test_processed)
model.fit_generator(train_gen, epochs=1)
model.evaluate_generator(test_gen)
# model.save('my-model') #保存模型
# loaded_model = mz.load_model('my-model') #加载模型
数据加载load_data
这里是直接在datasets包下创建了一个新包,把其他tutorials文件下面__init__.py 的代码拷贝进去就可以直接使用以下形式:
train_raw = mz.datasets.qa .load_data(stage='train', task=task) #这里的qa是我加在dataset下,放置中文训练数据
test_raw = mz.datasets.qa.load_data(stage='test', task=task)
也可以不创建文件夹,直接按照__init__.py的形式处理下文件,处理成matchzoo.pack读入数据后供后续使用
数据格式
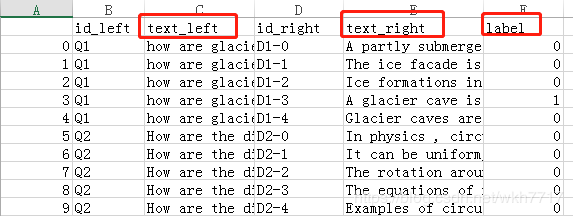
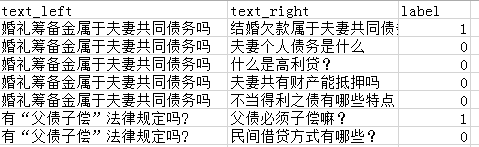
包中给到的数据示例如上图1,其中text_left/text_right/label是必须存在的,id_left/id_right可以不存在,不存在时程序处理自动补充,中文示例数据如下图2:
程序补充为图3:

中文分词
matchzoo仅支持英文形式,nltk分词工具以空格分词,默认情况下数据进来后首先经过3个处理步骤Tokenize、Lowercase、 PuncRemoval,其次是对text_left/text_right的固定长度填充、字符过滤等数据操作,如图4:

数据处理、分词部分主要是对preprocessors包下面文件进行修改,不指定preprocessor时,默认采用basic_preprocessor,BasicPreprocessor类中__init__() 函数中调用base_preprocessor.py中默认处理单元Tokenize、Lowercase、 PuncRemoval:
def _default_units(cls) -> list:
return [
mz.preprocessors.units.tokenize.Tokenize(),
mz.preprocessors.units.lowercase.Lowercase(),
mz.preprocessors.units.punc_removal.PuncRemoval(),
]
因此需要修改中文分词时preprocessor也要做相应的修改,可以重新构建preprocessor文件,也可以在程序中直接指定:
preprocessor._units = [
mz.preprocessors.units.tokenize_ch.Tokenize(),
# mz.preprocessors.units.lowercase.Lowercase(), #preprocessor中数据预处理单元修改,可直接赋值
mz.preprocessors.units.punc_removal.PuncRemoval(),
]
结果:

3个基础处理器
- Tokenize:分词,需要在原来代码tokenize.py中修改,或者重新写一个文件分词文件,将需要的分词方式写在transform函数中就可以,例如用结巴分词等,这里可以有更复杂的处理形式,需要注意的是用户词典问题,加载用户词典需要一定的时间且只需加载一次就可以,不好直接写在transform中,一次模型调用一般只创建一个preprocessor,因此我是直接在preprocessors包的__init__.py 中加载用户词典。
def transform(self, input_: str) -> list:
return jieba.lcut(input_)
# return nltk.word_tokenize(input_)
preprocessors >__init__.py
path = Path(__file__).parent.joinpath('userdict').joinpath('userdict.txt') #用户词典的位置 'usetdict/userdict.txt'
jieba.load_userdict(str(path))
采用结巴分词并添加分词词典后结果:(默认填充为30个字符)

- Lowercase:转化为小写的形式,中文中此步骤基本用不到
- PuncRemoval:删除标点符号,中文形式不用修改
中文embedding添加
词向量形式
matchzoo中目前支持两种形式的词向量形式,word2vec和glove的,可以自己手动添加其他形式的词向量,在embedding包下面的embedding.py文件夹下,load_from_file()函数,只需要添加其他mode就可以。
def load_from_file(file_path: str, mode: str = 'word2vec') -> Embedding:
if mode == 'word2vec':
data = pd.read_csv(file_path,
sep=" ",
index_col=0,
header=None,
skiprows=1)
elif mode == 'glove':
data = pd.read_csv(file_path,
sep=" ",
index_col=0,
header=None,
quoting=csv.QUOTE_NONE)
else:
raise TypeError(f"{mode} is not a supported embedding type."
f"`word2vec` or `glove` expected.")
return Embedding(data)
加载预训练词向量
预训练的词向量可以放在datasets包下的embedding包下面,init.py下可以定义一些常量
DATA_ROOT = Path(__file__).parent
EMBED_RANK = DATA_ROOT.joinpath('embed_rank.txt')
EMBED_10 = DATA_ROOT.joinpath('embed_10_word2vec.txt')
EMBED_10_GLOVE = DATA_ROOT.joinpath('embed_10_glove.txt')
EMBED_CPWS = DATA_ROOT.joinpath('cpwsword2vec.txt')
设置好需要加载的预训练词向量之后,通过embedding.load_from_file()对词向量加载,并且在生成模型时指定embedding,即预训练的词向量
emb = mz.embedding.load_from_file(mz.datasets.embeddings.EMBED_CPWS,mode='word2vec') # 加载word2vec词向量
model_class = mz.models.ArcI
model, preprocessor, data_generator_builder, embedding_matrix = mz.auto.prepare(
task=task,
model_class=model_class,
data_pack=train_raw,
embedding=emb
)
这里是直接采用mz.auto.prepare()函数来构建模型,也可以按照函数中的形式自己灵活设置。加载预训练词向量主要是在preparer.py函数中_build_model()函数调用_build_matrix()函数中实现
只有with_embedding=True时,才使用预训练的词向量
模型参数调整
模型内部有默认参数,可通过model.params查看模型中有哪些参数,然后在使用过程中修改
print(model.params) #展示模型中可调参数
model.params['mlp_num_units'] = 3 #直接调整参数