Yolo的搭建和在Windows下封装以及工程应用
概述
最近一直在研究基于深度学习的目标检测这一块,之前用过faster_rcnn和R-FCN,相对来说检测的准确率应该是可以的,但是实际的检测速度还是很不理想的,考虑实际工程的需求,所以后来想着用yolo来做目标检测,经过测试发现yolo确实是在检测速度上有很大的提高,但是调试了源码发现只是yolo的底层检测函数是满足实时的要求,而它基于视频的目标检测的demo我测试了一下大概是16FPS左右(不知道是不是我的原因,认识了一个网友,说他的测试能达到很高的帧率。),我是完全按照官网步骤测试的。后来测试了一张图片(1902*1080)发现整个测试的时间大约是0.4s左右,根本无法满足实时的要求,最后自己优化底层的代码并封装了一下yolo,最后的测试结果是0.06s左右(1902*1080)。下面将详细描述yolo的整个学习过程和步骤。
yolo的darknet安装
不管是安装yolo的v1还是v2的版本过程都是一样的,其对应的版本都可以去官网上面去下载:
http://pjreddie.com/darknet/yolo/
Yolo是很少依赖第三方库的,底层都是基于c语言写的,为了显示检测结果和加速检测时间效率需要安装opencv和cuda。我主要是以前一直在用caffe,所以之前就安装过opencv和cuda。这里我说明一下,网上有的说opencv的版本必须是opencv2.4.10的版本,我个人觉得并不一定,我的linux下面的opencv就是3.0,Windows下面用的是2.4.9的版本都是能用的,cuda用的是7.5的。这里就不累赘的说opencv和cuda的安装过程了,要是没有安装的可以去网上找找相关的资料(很多的),也可以去看看我之前的博客。
下面的安装步骤是基于Linux下面的:
1. 安装Git
sudo apt-get install git2. 安装darknet
在你想要安装的文件终端下输入:
git clone http://github.com/pjreddie/darknet.git或者直接下载yolo对应的版本包,直接解压就行。
切换到darknet文件下:
执行:
cd darknet修改Makefile文件,为了使其支持opencv和cuda:
修改如下:
OPENCV=1
NVCC = /usr/local/cuda-7.5/bin/nvcc (这里的路径是你cuda的nvcc的路径)
GPU=1 (要是没有GPU这里可以不用,也就是GPU=0,yolo也支持cpu版本只不过速度有点慢)保存退出,执行如下:
sudo make –j4等待编译的完成。编译完成后可以测试一下安装是否成功。
测试:这里测试的命令是v2版本的
sudo ./darknet detect cfg/yolo.cfg yolo.weights data/dog.jpg我都是按照官网上的步骤来的,测试的结果如下: 
yolo训练自己的数据(voc2007格式的)
v1和v2两个版本训练的过程都是不一样的,下面将分开介绍。
V1版本的训练
V1的训练过程我主要是参考了在目标检测方面的有很深研究的小咸鱼的博客:
http://blog.csdn.net/sinat_30071459/article/details/53100791
训练的步骤内容如下:
由于以前我研究过其它的深度学习的目标检测的网络模型,用的是也是voc2007格式的数据。所以,我们和作者一样,将VOC数据集转成YOLO训练所需格式,转换过程很简单,因为作者提供了转换的python代码:darknet\scripts\voc_label.py
(1)将数据集拷贝到darknet\scripts下
(2)我们打开voc_label.py并修改该代码:
sets=[('2007', 'train'), ('2007', 'val'), ('2007', 'test')]
classes = ["head","top","bag","down","shoes"] classes根据你的数据集类别改。还有需要注意的是,代码里写的文件夹是VOCdevkit,我们的可能是VOCdevkit2007,修改成VOCdevkit即可。
然后,终端进入darknet\scripts,执行:
sudo python voc_label.py 此后可以看到,VOCdevkit\VOC2007里多了一个labels文件夹(如下),里面有每张图片的标注文件(文件内容形如0 0.488888888889 0.289256198347 0.977777777778 0.429752066116;其中前面的0表示head,1表示top,即前面你写的classes的顺序,以此类推。后面为包围框信息,作了转换)。

darknet\scripts下多了2007_train.txt、2007_val.txt和2007_test.txt三个文件(如下),这三个文件是数据集中图片的路径。由于yolo训练只需要一个txt文件,文件中包含所有你想要训练的图片的路径,因此,我们可以用2007_train.txt、2007_val.txt和2007_test.txt包含的图片均用来训练,因此执行:
sudo cat 2007_* > train.txt 现在,我们已经将数据集中的训练集和验证集全都放在一个txt文件中,这些图片用来作为YOLO的训练图片。
3.修改代码
(1) 修改darknet\src\yolo.c
char *voc_names[] = {"head","top","bag","down","shoes"} 改成你的数据集类别;
char *train_images = "/home/luj/darknet/scripts/train.txt";
char *backup_directory = "/home//luj/darknet/backup/"; train_images应该指向我们刚得到的train.txt;backup_directory指向的路径是训练过程中生成的weights文件保存的路径(可以在darknet下新建文件夹backup然后指向它)。这两个路径按自己系统修改即可。
draw_detections(im, l.side*l.side*l.n, thresh, boxes, probs, voc_names, alphabet, 5);
else if(0==strcmp(argv[2], "demo")) demo(cfg, weights, thresh, cam_index,filename, voc_names,5, frame_skip, prefix);类别数改为你的数据集类别数(例如我的有5类)。
(2)修改darknet\src\yolo_kernels.cu
draw_detections(det, l.side*l.side*l.n, demo_thresh, boxes, probs, voc_names, voc_labels, 5); 最后的参数改为你的数据集类别数(同上)。
(3)修改darknet\cfg\tiny-yolo.cfg
本文以训练tiny模型为例,因此修改的是tiny-yolo.cfg文件,其他模型修改类似。
1. output= 735 // 该值为side*side*(2*5+类别数),yolo.train.cfg则是side*side*(3*5+类别数)
2. activation=linear
4. [detection]
5. classes= 5 //数据集类别
6. coords=4
7. rescore=1
8. side=7 /////
9. num=2
10. softmax=0
11. sqrt=1
12. jitter=.2 主要修改两个地方。side默认是7也可修改
其他的一些参数可以按自己需求修改,比如学习率、max_batches等。
4.下载预训练模型:
注:经过多次训练的经验,我发现有时候不用预训练的模型,直接进行训练最后得到的模型的效果也很好。
大家可以自己多尝试一下。
(在该模型参数的基础上微调)
下载地址:http://download.csdn.net/detail/sinat_30071459/9677797
该文件放在darknet下即可。
注:经过以上的修改,记得重新make一下darknet!!!
5.训练
在dartnet下执行:
./darknet yolo train cfg/tiny-yolo.cfg darknet.conv.weights 一切正常的话,就开始训练了。
6.测试和结果
执行:
./darknet yolo test cfg/tiny-yolo.cfg backup/tiny-yolo_final.weights 然后输入一张测试图片,结果大致如下:

V2版本的训练
由于V2版本是在yolo v1的基础上进行了改进,所以v2版本的训练跟v1版本的不一样。
这里参考的博客是:
http://blog.csdn.net/ch_liu23/article/details/53558549
训练内容如下:
按darknet的说明编译好后,接下来在darknet-master/scripts文件夹中新建文件夹VOCdevkit,然后将整个VOC2007文件夹都拷到VOCdevkit文件夹下。
然后,需要利用scripts文件夹中的voc_label.py文件生成一系列训练文件和label,具体操作如下:
首先需要修改voc_label.py中的代码,这里主要修改数据集名,以及类别信息,我的是VOC2007,并且所有样本用来训练,没有val或test,并且只检测人,故只有一类目标,因此按如下设置
1. import xml.etree.ElementTree as ET
2. import pickle
3. import os
4. from os import listdir, getcwd
5. from os.path import join
6.
7. #sets=[('2012', 'train'), ('2012', 'val'), ('2007', 'train'), ('2007', 'val'), ('2007', 'test')]
8.
9. #classes = ["aeroplane", "bicycle", "bird", "boat", "bottle", "bus", "car", "cat", "chair", "cow", "diningtable", "dog", "horse", "motorbike", "person", "pottedplant", "sheep", "sofa", "train", "tvmonitor"]
10.
11. sets=[('2007', 'train')]
12. classes = [ "person"]
13.
14.
15. def convert(size, box):
16. dw = 1./size[0]
17. dh = 1./size[1]
18. x = (box[0] + box[1])/2.0
19. y = (box[2] + box[3])/2.0
20. w = box[1] - box[0]
21. h = box[3] - box[2]
22. x = x*dw
23. w = w*dw
24. y = y*dh
25. h = h*dh
26. return (x,y,w,h)
27.
28. def convert_annotation(year, image_id):
29. in_file = open('VOCdevkit/VOC%s/Annotations/%s.xml'%(year, image_id)) #(如果使用的不是VOC而是自设置数据集名字,则这里需要修改)
30. out_file = open('VOCdevkit/VOC%s/labels/%s.txt'%(year, image_id), 'w') #(同上)
31. tree=ET.parse(in_file)
32. root = tree.getroot()
33. size = root.find('size')
34. w = int(size.find('width').text)
35. h = int(size.find('height').text)
36.
37. for obj in root.iter('object'):
38. difficult = obj.find('difficult').text
39. cls = obj.find('name').text
40. if cls not in classes or int(difficult) == 1:
41. continue
42. cls_id = classes.index(cls)
43. xmlbox = obj.find('bndbox')
44. b = (float(xmlbox.find('xmin').text), float(xmlbox.find('xmax').text), float(xmlbox.find('ymin').text), float(xmlbox.find('ymax').text))
45. bb = convert((w,h), b)
46. out_file.write(str(cls_id) + " " + " ".join([str(a) for a in bb]) + '\n')
47.
48. wd = getcwd()
49.
50. for year, image_set in sets:
51. if not os.path.exists('VOCdevkit/VOC%s/labels/'%(year)):
52. os.makedirs('VOCdevkit/VOC%s/labels/'%(year))
53. image_ids = open('VOCdevkit/VOC%s/ImageSets/Main/%s.txt'%(year, image_set)).read().strip().split()
54. list_file = open('%s_%s.txt'%(year, image_set), 'w')
55. for image_id in image_ids:
56. list_file.write('%s/VOCdevkit/VOC%s/JPEGImages/%s.jpg\n'%(wd, year, image_id))
57. convert_annotation(year, image_id)
58. list_file.close() 修改好后在该目录下运行命令:python voc_label.py,之后则在文件夹scripts\VOCdevkit\VOC2007下生成了文件夹lable,该文件夹下的画风是这样的

2.配置文件修改
做好了上述准备,就可以根据不同的网络设置(cfg文件)来训练了。在文件夹cfg中有很多cfg文件,应该跟caffe中的prototxt文件是一个意思。这里以tiny-yolo-voc.cfg为例,该网络是yolo-voc的简版,相对速度会快些。主要修改参数如下
1. [convolutional]
2. size=1
3. stride=1
4. pad=1
5. filters=30 //修改最后一层卷积层核参数个数,计算公式是依旧自己数据的类别数filter=num×(classes + coords + 1)=5×(1+4+1)=30
6. activation=linear
7.
8. [region]
9. anchors = 1.08,1.19, 3.42,4.41, 6.63,11.38, 9.42,5.11, 16.62,10.52
10. bias_match=1
11. classes=1 //类别数,本例为1类
12. coords=4
13. num=5
14. softmax=1
15. jitter=.2
16. rescore=1
17.
18. object_scale=5
19. noobject_scale=1
20. class_scale=1
21. coord_scale=1
22.
23. absolute=1
24. thresh = .6
25. random=1 另外也可根据需要修改learning_rate、max_batches等参数。这里歪个楼吐槽一下其他网络配置,一开始是想用tiny.cfg来训练的官网作者说它够小也够快,但是它的网络配置最后几层是这样的画风:
1. [convolutional]
2. filters=1000
3. size=1
4. stride=1
5. pad=1
6. activation=linear
7.
8. [avgpool]
9.
10. [softmax]
11. groups=1
12.
13. [cost]
14. type=sse 这里没有类别数,完全不知道怎么修改,强行把最后一层卷积层卷积核个数修改又跑不通会出错,如有大神知道还望赐教。
Back to the point。修改好了cfg文件之后,就需要修改两个文件,首先是data文件下的voc.names。打开voc.names文件可以看到有20类的名称,本例中只有一类,检测人,因此将原来所有内容清空,仅写上person并保存。名字仍然用这个名字,如果喜欢用其他名字则请按一开始制作自己数据集的时候的名字来修改。
接着需要修改cfg文件夹中的voc.data文件。也是按自己需求修改,我的修改之后是这样的画风:
1. classes= 1 //类别数
2. train = /home/kinglch/darknet-master/scripts/2007_train.txt//训练样本的绝对路径文件,也就是上文2.1中最后生成的
3. //valid = /home/pjreddie/data/voc/2007_test.txt //本例未用到
4. names = data/voc.names //上一步修改的voc.names文件
5. backup = /home/kinglch/darknet-master/results/ //指示训练后生成的权重放在哪 修改后按原名保存最好,接下来就可以训练了。
ps:yolo v1中这些细节是直接在源代码的yolo.c中修改的,源代码如下 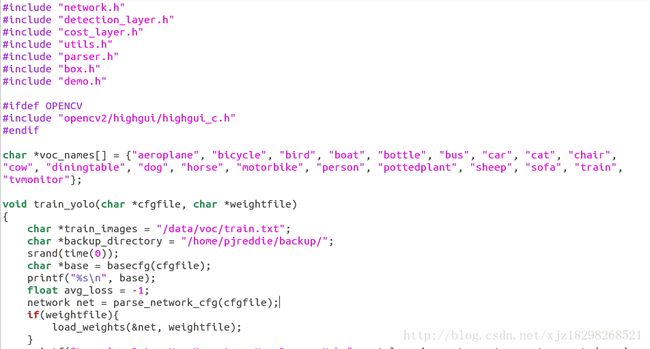
比如这里的类别,训练样本的路径文件和模型保存路径均在此指定,修改后从新编译。而yolov2似乎摈弃了这种做法,所以训练的命令也与v1版本的不一样。
3.运行训练
上面完成了就可以命令训练了,可以在官网上找到一些预训练的模型作为参数初始值,也可以直接训练,训练命令为
/darknet detector train ./cfg/voc.data cfg/tiny-yolo-voc.cfg 如果用官网的预训练模型darknet.conv.weights做初始化,则训练命令为
/darknet detector train ./cfg/voc.data .cfg/tiny-yolo-voc.cfg darknet.conv.weights 不过我没试成功,加上这个模型直接就除了final,不知道啥情况。当然也可以用自己训练的模型做参数初始化,万一训练的时候被人终端了,可以再用训练好的模型接上去接着训练。
训练过程中会根据迭代次数保存训练的权重模型,然后就可以拿来测试了,测试的命令同理:
/darknet detector test cfg/voc.data cfg/tiny-yolo-voc.cfg results/tiny-yolo-voc_6000.weights data/images.jpg 
Windows下封装yolo并调用
这里说明一下:我是参考了小咸鱼的博客的,也是只把别人的开源的工程下载下来调试通了,他实现了yolo的dll封装并调用,也提供了封装的工程代码。但是他的工程只是检测的一个demo,可能是无法满足工程上实时的目标检测。我在他的基础上改了底层的代码和重新封装了dll。下面我将从两个方面讲解整个工程dll的封装以及调用过程。
小咸鱼工程的实践过程
这里贴出小咸鱼的博客地址:http://blog.csdn.net/sinat_30071459/article/details/53161113
我调试了他的工程,我主要用的是GPU版,测试的结果跟他是一样的效果。
* Dll工程直接调用的配置过程如下:*
下载他的封装好的工程,直接配置opencv就行,Opencv的配置过程就和你以前使用opencv的配置过程一样。至于cuda和pthread的配置,小咸鱼在封装dll的时候已经配置好了,你直接就可以跑了。
注:我这里将我自己调DLL的工程上传到csdn上,工程中的yolo模型主要是对行人进行检测,直接下载下来就可以,DLL是我基于小咸鱼进行DLL的工程进行修改了,在速度上比之前的快。
下载网址:http://download.csdn.net/detail/xjz18298268521/9780949
(ps:由于工程比较大,CSND上传的资源大小有限,所以我就把资源上传到百度云盘里了,云盘的链接和密码上传到了csdn上了。)
封装dll工程的配置过程:
下载他的封装dll的工程,用vs2013打开,主要是配置opencv和cuda以及pthread库。
Opencv的配置过程就和你以前使用opencv的配置过程一样。cuda和pthread的配置过程几乎和opencv的是一样,cuda要配置的头文件和lib文件的路径主要是在你安装的路径下,pthread的头文件和库文件工程中都自带了,你直接给包含进来就可以了。要是不会可以给我留言。配置大致如下:
1.添加可执行文件 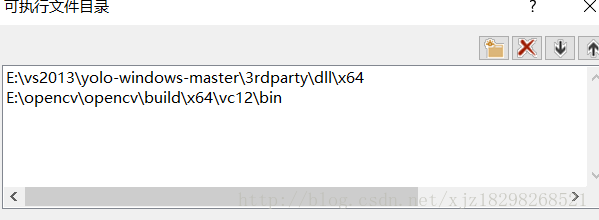
2.添加包含目录 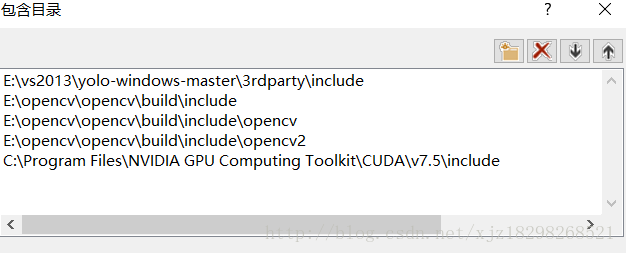
3.添加lib库文件 
4.添加连接器中的输入 
5.配置c/c++中的预处理器 
小咸鱼的博客内容:
http://blog.csdn.net/sinat_30071459/article/details/53161113
自己封装dll的工程
如果你也调试了小咸鱼的工程,你会发现他封装的工程在检测效率上大约是0.4-0.6s左右一张图片,无法满足实时的效果。而且他的工程只是一个test的dll,是遍历一个文件夹测试文件下所有的图片,无法对视频进行有效的检测。而且存在一个问题就是他的dll是c语言来写的,想要用c++来调用的话还是比较麻烦的。我修改的思路如下:
**1. 重构底层代码:
问题一:**
经过测试发现底层最耗时的是图片的load和resize,这两个函数占用的时间大概是0.4s左右有点耗时;
问题二:
模型每次加载的时间比较长;
解决:
我将模型的初始化单独摘出来,放在初始化函数中,每次只需要模型加载一次,解决每次加载模型需要消耗的时间,将dll工程封装为两个接口,一个用于模型加载,一个是检测函数。
我重新写了底层的代码,改写了图片的load和resize函数,我将这两个函数的单独摘出来,放在dll工程外面,也就是调用dll的接口是读入图片和resize图片,并利用opencv的指针访问将图片数据装换成yolo检测模型需要的数据格式,并用指针作为参数传入进去。
我用一个char指针按照我定义的规则将检测坐标以及数目的结果作为参数传出来,并按照规则在外面进行解析。外面调接口的函数是基于c++来写的。
2. 封装的接口有两个
一个是yolo模型的加载函数接口,一个是yolo检测函数的接口,如下图所示: 