Python爬取链家房价信息
房子问题近些年来越来越受到大家的关注,要了解近些年的房价,首先就要获取网上的房价信息,我们以链家网上出售的房价信息为例,将数据爬取下来并存储起来。
这次信息的爬取我们依然采取requests-Beautiful Soup的线路来爬取链家网上的出售房的信息。需要安装好anaconda,并保证系统中已经有requests库,Beautiful Soup4库和csv库已经安装。
网页分析
我们要爬取的网页如下,我们需要的信息有房子的名称和价格
https://sh.lianjia.com/ershoufang/
如下图:
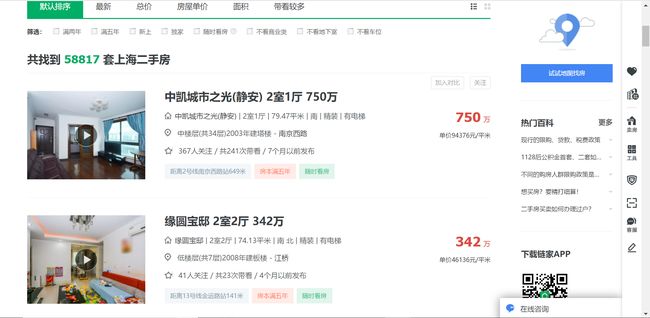
下面我们来分析我们所要提取的信息的位置,打开开发者模式查找元素,我们找到房子的名称和价格;如下图:
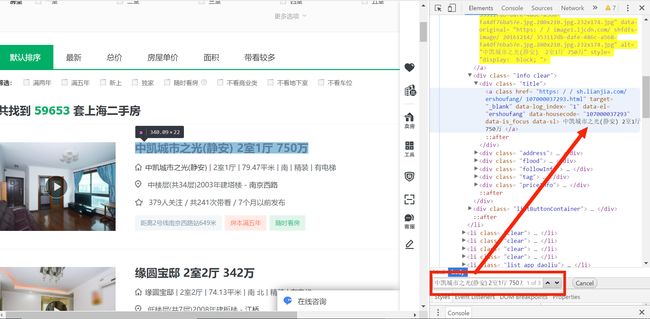
我们可以看到我们所需要的房子名称的信息在{div class="title"}里面,价格信息在{div class="totalPrice"}里面,所有的信息都封装在li标签里面。
我们分析了一个网页里面的网页结构,要爬取其他网页的信息还要看到更多的结构;
第一个网页链接:https://sh.lianjia.com/ershoufang/pg1
第二个网页链接:https://sh.lianjia.com/ershoufang/pg2
第三个网页链接:https://sh.lianjia.com/ershoufang/pg3
每页的链接都以pg+某页数字结尾,我们以此发现规律。
程序结构
接下来我们来编写程序的主体结构:
import requests
from bs4 import BeautifulSoup
import csv
def getHTMLText(url): #获取网页信息
return ""
def get_data(list,html): #获取数据并存储下来
def main():
start_url = "https://sh.lianjia.com/ershoufang/pg"
depth = 20
info_list = []
for i in range(depth):
url = start_url + str(i)
html = getHTMLText(url)
get_data(info_list,html)
main()根据各个函数的目的,来填充函数的具体内容,第一个函数要获取网页信息:
def getHTMLText(url):
try:
r = requests.get(url)
r.raise_for_status()
r.encoding = r.apparent_encoding
return r.text
except:
return "产生异常"第二个函数是要获取数据并存储在文件中;
def get_data(list,html):
soup = BeautifulSoup(html,'html.parser')
infos = soup.find('ul',{'class':'sellListContent'}).find_all('li') #找到所有的li标签
with open(r'/Users/11641/Desktop/lianjia.csv','a',encoding='utf-8') as f: #创建一个lianjia.csv的文件并写入
for info in infos:
name = info.find('div',{'class':'title'}).find('a').get_text()
price =info.find('div',{'class':'priceInfo'}).find('div',{'class','totalPrice'}).find('span').get_text()
f.write("{},{}\n".format(name,price))上面我们就写完了这个爬虫程序
但是要注意的是:运行完成的程序以csv文件保存下来,如果直接用excel打开可能会有乱码现象,一般用如下步骤解决:
- 用记事本打开文件,另存为选择编码为:ANSI,存储文件;
- 将存储的新文件用excel打开,另存为excel文件格式,就可永久存储文件
我们来看一下文件存储的效果,如下图:

程序代码
上面我们成功的写完了链家二手房爬虫的代码,并成功输出了我们大致所要的结果,全部代码如下;
#爬取链家二手房信息
import requests
from bs4 import BeautifulSoup
import csv
def getHTMLText(url):
try:
r = requests.get(url,timeout=30)
r.raise_for_status()
r.encoding = r.apparent_encoding
return r.text
except:
return '产生异常'
def get_data(list,html):
soup = BeautifulSoup(html,'html.parser')
infos = soup.find('ul',{'class':'sellListContent'}).find_all('li')
with open(r'/Users/11641/Desktop/lianjia.csv','a',encoding='utf-8') as f:
for info in infos:
name = info.find('div',{'class':'title'}).find('a').get_text()
price =info.find('div',{'class':'priceInfo'}).find('div',{'class','totalPrice'}).find('span').get_text()
f.write("{},{}\n".format(name,price))
def main():
start_url = 'https://sh.lianjia.com/ershoufang/pg'
depth = 20
info_list =[]
for i in range(depth):
url = start_url + str(i)
html = getHTMLText(url)
get_data(info_list,html)
main()总结:
1.爬虫主要用requests库和Beautiful Soup库可以简明地爬取网页上的信息;
2.先定好程序主要框架,再根据目的需求填充函数内容:获取网页信息>爬取网页数据>存储数据;
3.对于所有的信息存储于多页,要观察网页信息,构造每页的url链接来解决;
4.最重要的是解析网页结构,最好可以用标签树的形式确定字段所在的标签,并遍历全部标签存储数据。