2020 年最新微博内容及评论爬虫
微博爬虫综述
今天手把手教大家如何写成一份微博爬虫的代码,可以自己爬取微博的热门话题或评论,方便做相关的数据分析和可视化。
该项目的 Github 地址是 https://github.com/Python3Spiders/WeiboSuperSpider
,请不要利用该爬虫项目获得的数据作任何违法用途。
微博爬虫主要有两个导向,一个是微博内容的爬虫,其目的字段包括微博文本、发布者、转发/评论/点赞数等,另一个是微博评论的爬虫,其目的字段主要是评论文本和评论者。
微博的爬虫的目的网站主要有四个,pc 站weibo.com、weibo.cn 以及对应的 m(mobile) 站 m.weibo.com(无法在电脑上浏览)、m.weibo.cn,总得来说,.cn 比 .com 更简单 UI 更丑,m 站比 pc 站更简单 UI 更丑。
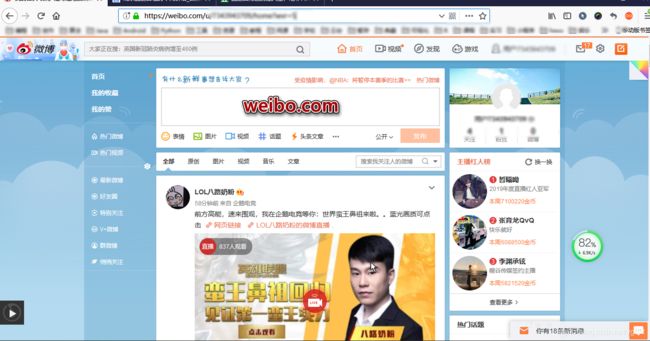
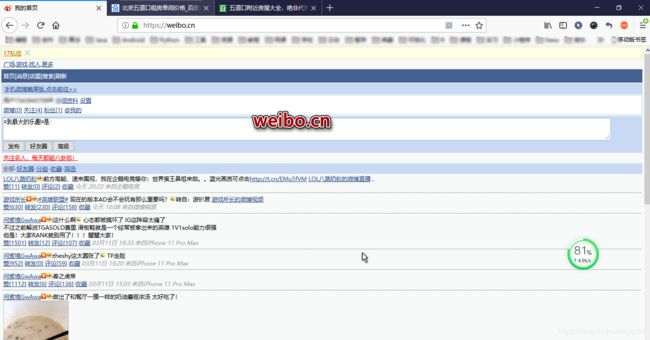


Github 仓库详解
仓库的目录如下图所示,主要是分两部分 GUI 功能集中版 和 无 GUI 功能独立版,GUI 即 Graph User Interface(图形用户接口)。
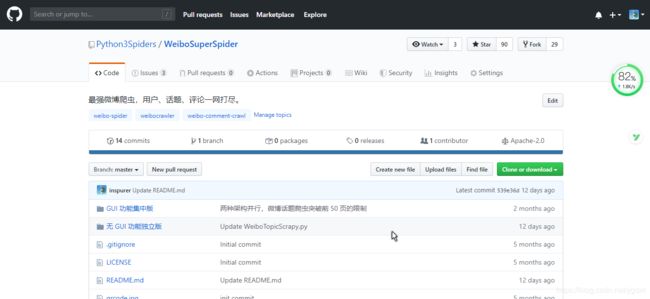
GUI 功能集中版
最开始只有 GUI 功能集中版 这一部分,主代码是 GUI.py 和 WeiboCommentScrapy.py。
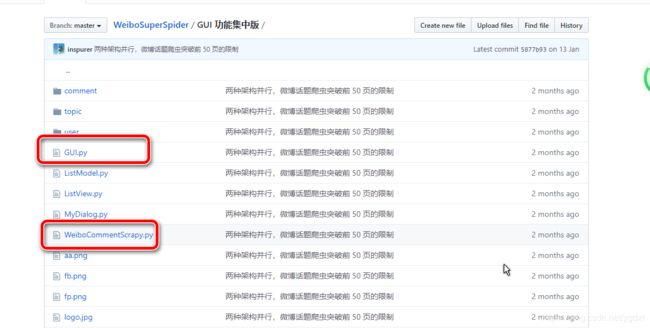
GUI.py 包括爬虫逻辑和 GUI 界面,是基于 PyQt5 构建的,爬虫部分由三个类 WeiboSearchScrapy、WeiboUserScrapy、WeiboTopicScrapy,他们的目标站点都是 weibo.cn,都继承自线程类 Thread。
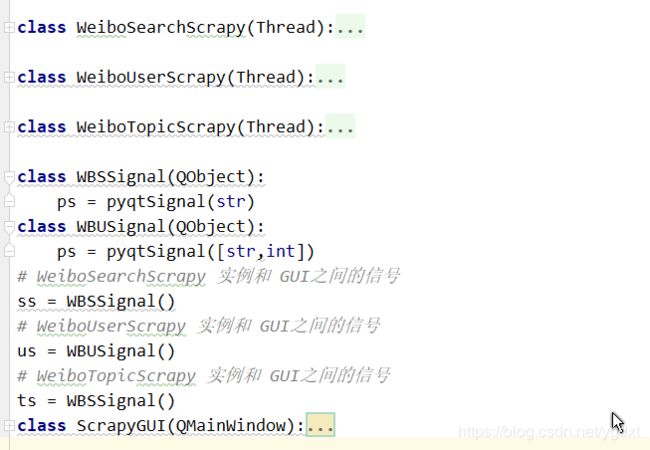
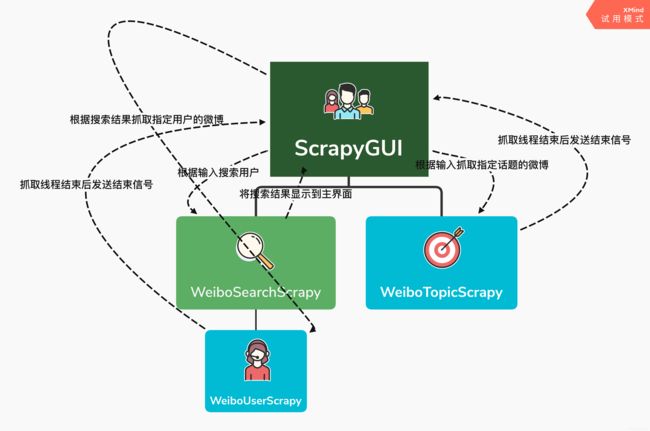
GUI.Py 里面实现的是用户/话题爬虫,即爬取指定用户/话题下的微博,当我们在界面点击提交了一个抓取任务,就会开启对应的线程类爬虫,抓取完毕通过该类和主界面之间的信号提示抓取完成。
GUI.py 运行效果图如下:
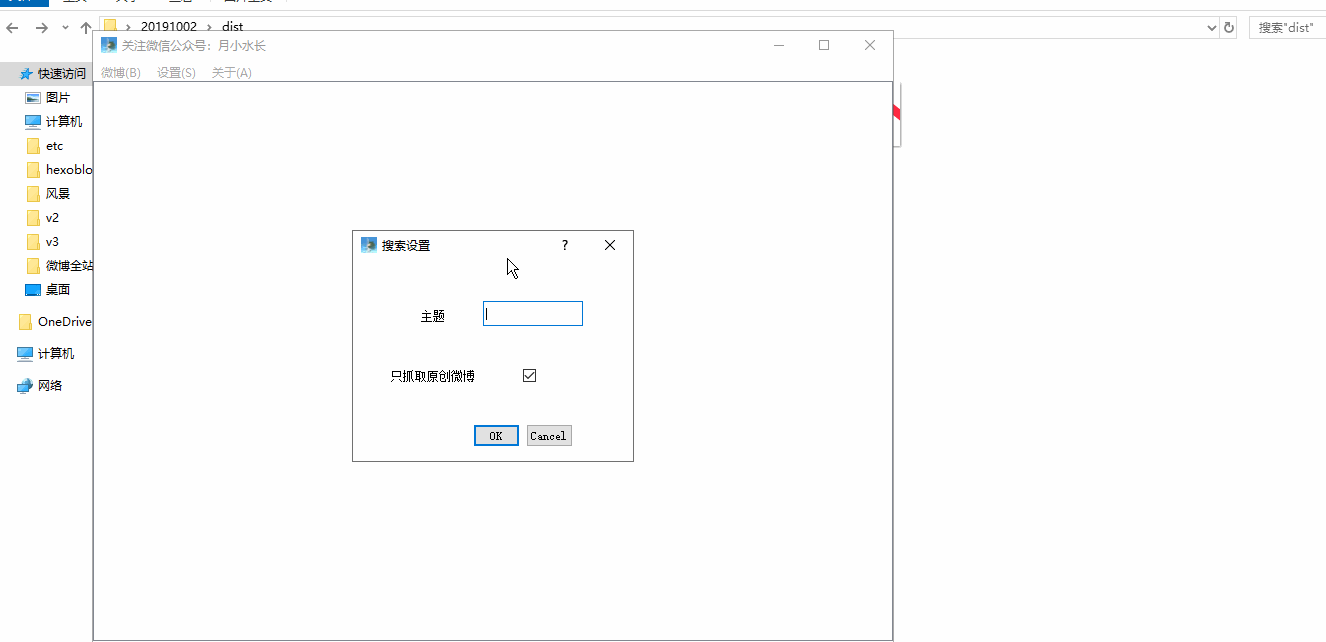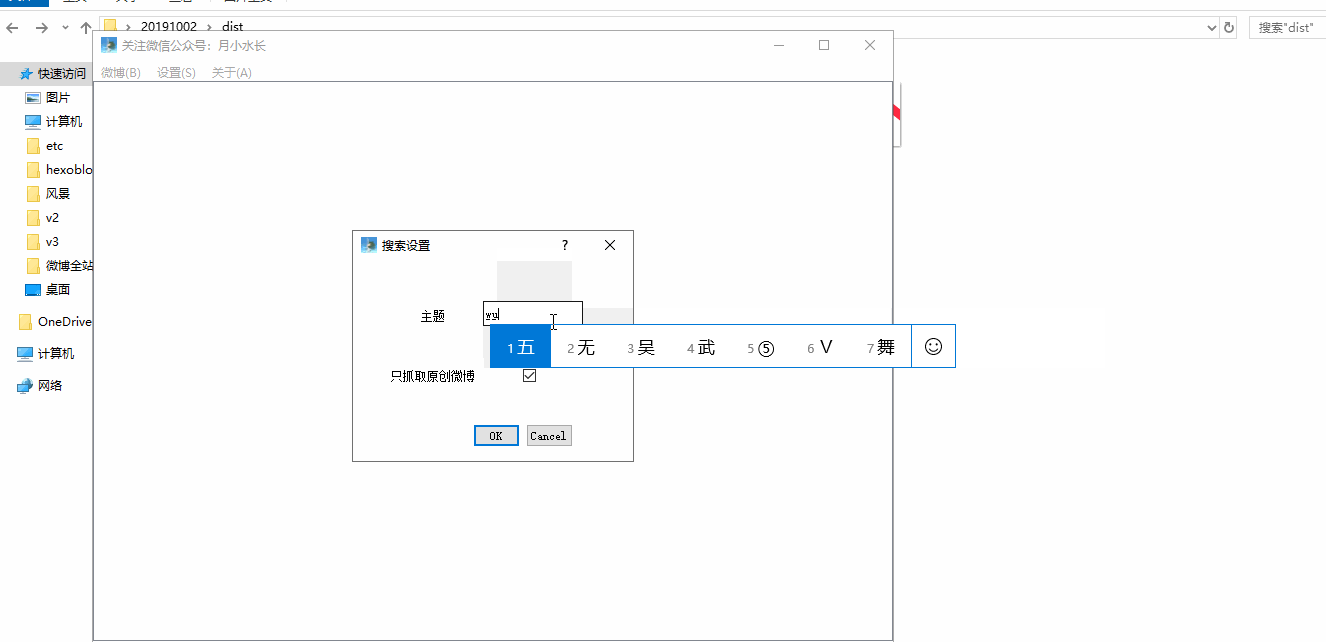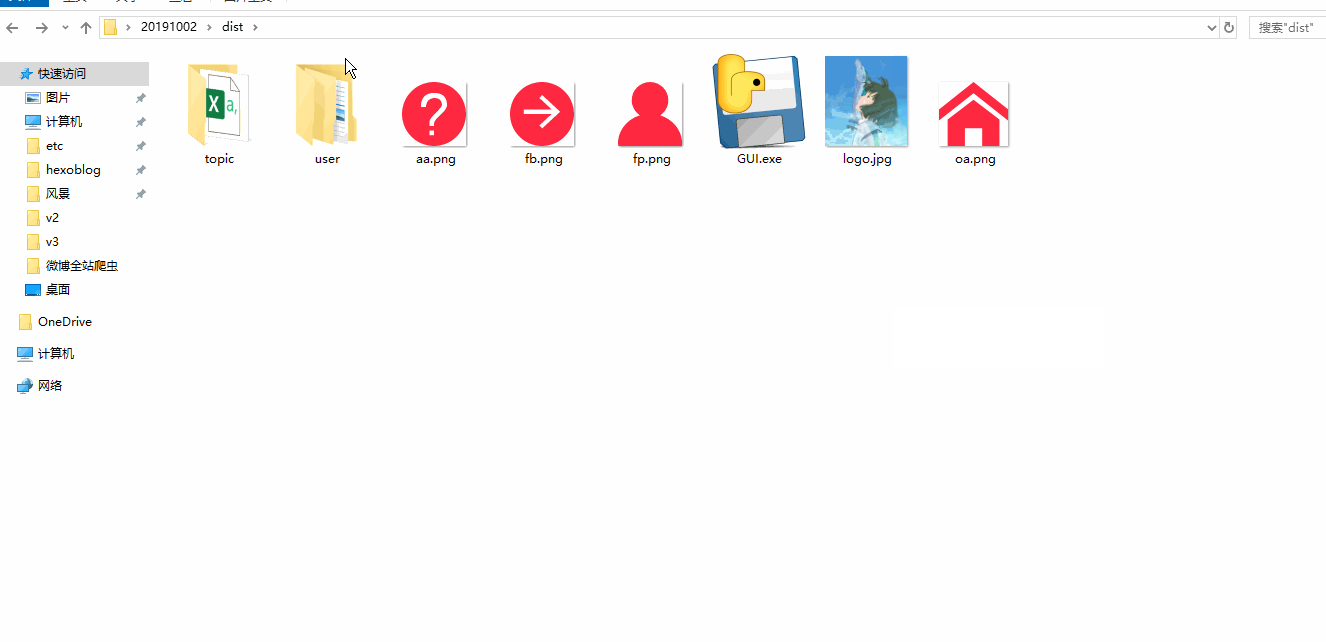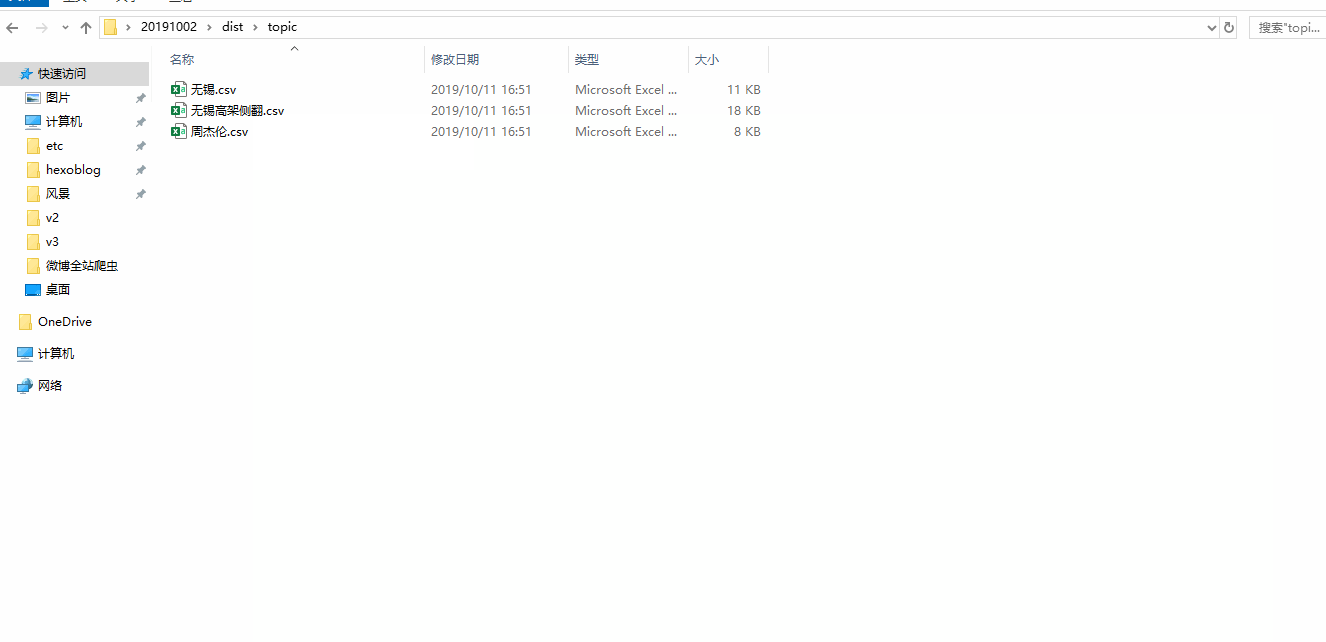
无论是微博用户,还是话题爬虫,都有 50 页左右的限制。
爬取了微博之后,我们可以使用 WeiboCommentScrapy.py 爬取指定微博的评论,怎么指定,参考下图
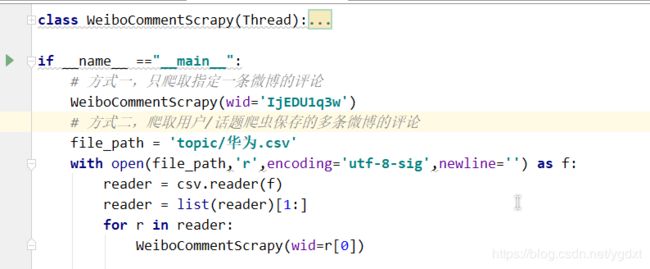
注意 weibo.cn 站微博的 id 是类似 IjEDU1q3w 这种格式,和后面的 m.weibo.cn 的微博 id 格式不同(它的纯数字,比较长),该评论爬虫只能爬取前 100 页的。
微博用户/话题/评论 爬虫的数据依次保存在 user/topic/comment 文件夹下的 csv 文件中。
20200313 实测 GUI 功能集中版的代码仍可用,exe 失效了,因为代码每更新一次就要打包、发布一次 exe,比较麻烦,我就没更新 exe 了( exe 是第一版代码打包了,现在第三版了)
注意 GUI 功能集中版均是针对 weibo.cn 的,也就是界面最丑的那个站,不要把 weibo.com 或者 m.weibo.cn 的 cookie 放到这来,否则会出现以下错误:
encoding error : input conversion failed due to input error, bytes 0xC3 0x87 0xC3 0x82
encoding error : input conversion failed due to input error, bytes 0xC3 0x87 0xC3 0x82
encoding error : input conversion failed due to input error, bytes 0xC3 0x87 0xC3 0x82
I/O error : encoder error
encoding error : input conversion failed due to input error, bytes 0xC3 0x87 0xC3 0x82
encoding error : input conversion failed due to input error, bytes 0xC3 0x87 0xC3 0x82
encoding error : input conversion failed due to input error, bytes 0xC3 0x87 0xC3 0x82
I/O error : encoder error
同时,如果出现了诸如PermissionError: [Errno 13] Permission denied: 'comment/IaYZIu0Ko.csv 之类的错误,则是因为你在 excel 中打开了 这个 csv 文件,同时程序还在继续向这个文件追加写,获取不到锁因而报错,如果想一边跑一边查看文件内容,可以用 Pycharm 的 CSV Plugin 插件。
无 GUI 功能独立版
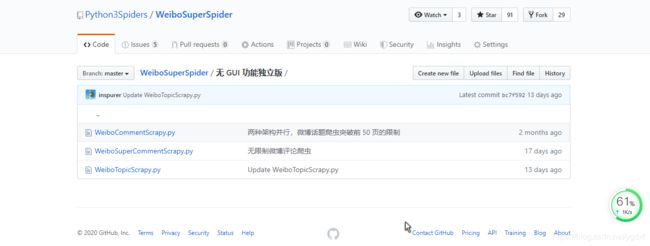
该文件下有三个文件 WeiboCommentScrapy.py、WeiboTopicScrapy.py、WeiboSuperCommentScrapy.py,前面两个都还是针对 weibo.cn 的,WeiboTopicScrapy.py 作了相应的升级,可以支持时间跨度搜索,比如之前假如这个话题有 1000 页吗,我们最多只能爬取 130 页,但是可能把这 1000 页按照时间段拆分,每个时间段(Year-Month-Day,不支持小时及以下时间颗粒度)无论长短,都最多能获取 130 页。
而 WeiboSuperCommentScrapy.py 则是针对 m.weibo.cn 的,这个评论爬虫没有 100 页的限制,我一条微博拿到了几w+的评论,但是有的只能拿到几k(实际评论几w+),这点很迷。该文件运行可以不自己设置 cookie,可以通过账号登录自动获取 cookie,这一步是学习的一位简书博主的文章(https://www.jianshu.com/p/8dc04794e35f)不过经过调试我发现其中有个参数 max_id_type 会在 17 页+1,同时做了对评论的回复的解析保存。
解析的代码如下,直接提取 json :
def info_parser(data):
id,time,text = data['id'],data['created_at'],data['text']
user = data['user']
uid,username,following,followed,gender = \
user['id'],user['screen_name'],user['follow_count'],user['followers_count'],user['gender']
return {
'wid':id,
'time':time,
'text':text,
'uid':uid,
'username':username,
'following':following,
'followed':followed,
'gender':gender
}
抓取的代码如下:
def start_crawl(cookie_dict,id):
base_url = 'https://m.weibo.cn/comments/hotflow?id={}&mid={}&max_id_type=0'
next_url = 'https://m.weibo.cn/comments/hotflow?id={}&mid={}&max_id={}&max_id_type={}'
page = 1
id_type = 0
comment_count = 0
requests_count = 1
res = requests.get(url=base_url.format(id,id), headers=headers,cookies=cookie_dict)
while True:
print('parse page {}'.format(page))
page += 1
try:
data = res.json()['data']
wdata = []
max_id = data['max_id']
for c in data['data']:
comment_count += 1
row = info_parser(c)
wdata.append(info_parser(c))
if c.get('comments', None):
temp = []
for cc in c.get('comments'):
temp.append(info_parser(cc))
wdata.append(info_parser(cc))
comment_count += 1
row['comments'] = temp
print(row)
with open('{}/{}.csv'.format(comment_path, id), mode='a+', encoding='utf-8-sig', newline='') as f:
writer = csv.writer(f)
for d in wdata:
writer.writerow([d['wid'],d['time'],d['text'],d['uid'],d['username'],d['following'],d['followed'],d['gender']])
time.sleep(5)
except:
print(res.text)
id_type += 1
print('评论总数: {}'.format(comment_count))
res = requests.get(url=next_url.format(id, id, max_id,id_type), headers=headers,cookies=cookie_dict)
requests_count += 1
if requests_count%50==0:
print(id_type)
print(res.status_code)
反爬措施主要是设置 User-Agent 和 Cookie,欢迎大家尝试,有问题请留言。