像学 SQL 那样学 pandas
作为 pandas 教程的第四篇,本篇将对比 SQL 语言,学习 pandas 中各种类 SQL 操作,文章篇幅较长,可以先收藏后食用,但不可以收藏后积灰~

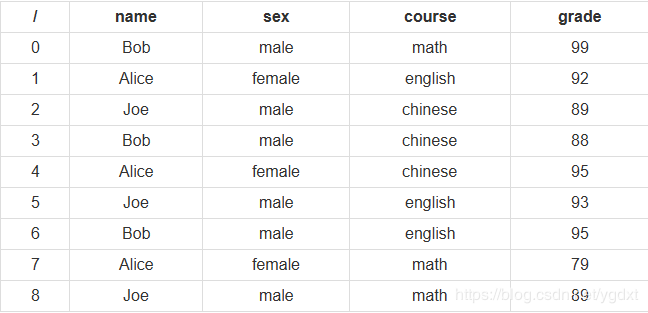
为了方便,依然以下面这个 DataFrame 为例,其变量名为 df,设有一同样结构的 SQL 表,表名为 tb:
and、or、not 和集合资格测试 in
1、and
需求:选择成绩大于 90 分的男生的成绩单
sql 写法:select * from tb where sex="male" and grade>90
pandas 写法:and 符号 &,df[(df['sex']=='male') & (df['grade']>90)]
常见的 pandas 错误写法:
- 由于 sql 的思维惯性,把 & 写成 and。
- & 两侧没加括号,写成
df[df['sex']=='male' & df['grade']>90],这时会报错:TypeError: cannot compare a dtyped [int64] array with a scalar of type [bool],从字面意思来看是 int64 数组和布尔值无法比较,真正的原因是因为 ==、> 运算符的优先级并不比 & 高,从左往右看,第一个运算df['sex']=='male'的结果就是一个布尔值,然后这个布尔值再与 df[‘grade’] 作 & 运算,这样就报错了。解决办法就是像正确写法那样,& 两侧加括号。
这样选择出来的 dataframe,其 index 是不连续的,因为 pandas 的选择,连同原来的 index 一起选择了,符合条件的行,在原来的 dataframe 中,index 几乎不可能连续(除开巧合)。所以必须 reset_index 下,这个函数有两个值得注意的参数 inplace 和 drop,inplace 在 【】就讲过,如果原地修改就设置为 True,至于这个 drop ,设置为 False 则 index 列会被还原为普通列,否则的话就直接丢失,这里我们设置为 True,直接丢掉,否则的话,就会出现以只带文件名方式读取了保存 index 的 csv 文件那样的错误:出现一列 “unnamed: 0”。
and_df = df[(df['sex']=='male') & (df['grade']>90)]
and_df.reset_index(inplace=True, drop=True)
2、or
需求:选择分数大于 95 或者小于 85 的学生的成绩单
sql 写法:select * from tb where grade>95 or grade<85
pandas 写法:or 符号 |,即df[(df['grade']>95) | (df['grade']<85)]
3、not
需求:选择分数大于等于 85 并且小于等于 95 分的学生
分析:这个需求有很多写法,可以用 and, 也可以利用求补思想,即 not
sql 写法:select * frim tb where grade not in(select grade from tb where grade>85 and grade<95)
pandas 写法:not 符号 -,即 df[-((df['grade']>95) | (df['grade']<85))]
4、集合资格测试 in
需求:选择分数为 89、95 之一的学生
sql 写法:select * from tb where grade in (89, 95)
pandas 写法:df[df['grade'].isin([89, 95])]
上述的四个例子,都是整行查询,即 select * from xxx where yyy=zzz 的形式,如果只需要查询某个字段,比如查询男生中语文成绩最差的学生的名字,以通过 loc 表达式实现,如下:
math_best_student = df.loc[(df['course']=='chinese')&(df['sex']=='male'), ['name','grade']].sort_values('grade').reset_index(drop=True).iloc[0, 0]
这行代码语法糖较多,分三步拆解:
- 条件选择:所有男生的语文成绩的姓名、(语文)成绩两个字段
- 成绩升序:按照成绩升序排列,注意 reset_index 重置索引,不需要 inplace,否则没有返回值,无法再黏语法糖。
- 切片选择:第 0 个学生,即成绩最差的学生的第 0 列 ,即 name 列。
groupby
groupby 即分组聚合,df.group_by() 即可实现,它返回的是一个 GroupBy 对象而不是 dataframe
需要对这个 GroupBy 对象进行后续的聚合函数调用才会返回 dataframe。
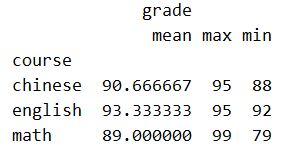
需求:数学、语文、英语三门课各自的平均分,最高分、最低分
sql 写法:select avg(grade),max(grade),min(grade) from tb group by course
pandas 写法:
gb_df = df.groupby('course').agg({
'grade': ['mean', 'max', 'min']
})
其打印结果如下:
连接
sql 中有四种连接:内连接,左外连接,右外连接,全外连接,
以 df 为左表,right_df 为右表,在 name 字段连接为例。
df = pd.DataFrame({'name':['Bob','Alice','Joe']*3,
'sex':['male','female','male']*3,
'course': ['math', 'english', 'chinese', 'chinese', 'chinese', 'english', 'english', 'math', 'math'],
'grade':[99,92,89,88,95,93,95,79,89]})
right_df = pd.DataFrame({
'name': ['Bob', 'Alice', 'Miller'],
'number': [1001, 1002, 1003]
})
| 连接 | 解释 |
|---|---|
| 内连接 | 在 name 列上取交集,只保留左右两表都出现的 name,即只有 Bob、Alice 两人的共六门成绩 |
| 左外连接 | 保留左表中 name 中出现的而右表没有出现的,同时对应右表的 number 字段置空 |
| 右外连接 | 参见左外连接 |
| 全外连接 | 都置空 |
pandas 有 merge 和 join 两个函数可以实现连接,区别如下:
- merge 默认在左右两表中相同列合并,也可以 on, left_on, right_on 指定(左/右)列
- join 默认在 index 合并,也可以 on 指定,没有 left_on、right_on
可以看到 merge 使用范围更广一点。
这四种连接对应的 sql 及 pandas 写法如下表
| 连接 | sql | pandas |
|---|---|---|
| 内连接 | select * from tb inner join right_tb on tb.name=right_tb.name | df.merge(right_df, how=‘inner’) df.merge(right_df, on=‘name’, how=‘inner’) inner_df = df.merge(right_df, left_on=‘name’, right_on=‘name’, how=‘inner’) |
| 左外连接 | select * from tb left join right_tb on tb.name=right_tb.name | df.merge(right_df, how=‘left’) |
| 右外连接 | select * from tb right join right_tb on tb.name=right_tb.name | df.merge(right_df, how=‘right’) |
| 全外连接 | select * from tb full outer join right_tb on tb.name=right_tb.name | df.merge(right_df, how=‘outer’) |