14利用SVD简化数据
【转】第14章 利用SVD简化数据
一、svd概述
奇异值分解(Singular Value Decomposition,以下简称SVD)是在机器学习领域广泛应用的算法,它不仅用于降维算法中的特征分解,还可以用于推荐系统,以及自然语言处理领域的隐性语义检索(Latent Semantic Indexing, LSI)或 隐形语义分析(Latent Semantic Analysis, LSA)。
二、svd基本原理
1.矩阵乘法的意义
矩阵乘法的意义是变换,矩阵乘法就是线性变换,包括伸缩、切变、旋转等。一个矩阵乘以一个向量后得到的向量,其实就相当于将这个向量进行了线性变换。比如说下面的一个矩阵:
M = [ 3 0 0 1 ] M=\left[ \begin{array}{ll}{3} & {0} \\ {0} & {1}\end{array}\right] M=[3001]
它其实对应的线性变换是下面的形式:

因为这个矩阵M乘以一个向量(x,y)的结果是:
[ 3 0 0 1 ] [ x y ] = [ 3 x y ] \left[ \begin{array}{ll}{3} & {0} \\ {0} & {1}\end{array}\right] \left[ \begin{array}{l}{x} \\ {y}\end{array}\right]=\left[ \begin{array}{c}{3 x} \\ {y}\end{array}\right] [3001][xy]=[3xy]
2.特征分解
特征值和特征向量的定义如下
A x = λ x A x=\lambda x Ax=λx
其中A是一个![]() 的实对称矩阵,
的实对称矩阵, 是一个n维向量,则我们说
是一个n维向量,则我们说![]() 是矩阵
是矩阵![]() 的一个特征值,而x是矩阵
的一个特征值,而x是矩阵![]() 的特征值
的特征值![]() 所对应的特征向量。
所对应的特征向量。
特征值分解可以得到特征值与特征向量,特征值表示的是这个特征到底有多重要,而特征向量表示这个特征是什么,可以将每一个特征向量理解为一个线性的子空间,我们可以利用这些线性的子空间干很多的事情。不过,特征值分解也有很多的局限,比如说变换的矩阵必须是方阵。
3.奇异值分解
特征值分解是一个提取矩阵特征很不错的方法,但是它只是对方阵而言的,在现实的世界中,我们看到的大部分矩阵都不是方阵,比如说有M个学生,每个学生有N科成绩,这样形成的一个![]() 的矩阵就不可能是方阵,**我们怎样才能描述这样普通的矩阵呢的重要特征呢?**奇异值分解可以用来干这个事情,奇异值分解是一个能适用于任意的矩阵的一种分解的方法:
的矩阵就不可能是方阵,**我们怎样才能描述这样普通的矩阵呢的重要特征呢?**奇异值分解可以用来干这个事情,奇异值分解是一个能适用于任意的矩阵的一种分解的方法:
A m × n = U m × m Σ m × n V n × n T A_{m \times n}=U_{m \times m} \Sigma_{m \times n} V_{n \times n}^{T} Am×n=Um×mΣm×nVn×nT
A是一个![]() 的矩阵,那么得到的U是一个
的矩阵,那么得到的U是一个![]() 的方阵(里面的向量是正交的,U里面的向量称为左奇异向量),Σ是一个
的方阵(里面的向量是正交的,U里面的向量称为左奇异向量),Σ是一个![]() 的矩阵(除了对角线的元素都是0,对角线上的元素称为奇异值),
的矩阵(除了对角线的元素都是0,对角线上的元素称为奇异值),![]() (V的转置)是一个
(V的转置)是一个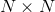 的矩阵(里面的向量也是正交的,V里面的向量称为右奇异向量)。
的矩阵(里面的向量也是正交的,V里面的向量称为右奇异向量)。
那么奇异值和特征值是怎么对应起来的呢?首先,我们将一个矩阵![]() 的转置
的转置![]() ,将会得到一个方阵,我们用这个方阵求特征值可以得到:
,将会得到一个方阵,我们用这个方阵求特征值可以得到:
( A T A ) v i = λ i v i \left(A^{T} A\right) v_{i}=\lambda_{i} v_{i} (ATA)vi=λivi
这里得到的v,就是我们上面的右奇异向量。此外我们还可以得到:
σ i = λ i u i = 1 σ i A v i \begin{aligned} \sigma_{i} &=\sqrt{\lambda_{i}} \\ u_{i} &=\frac{1}{\sigma_{i}} A v_{i} \end{aligned} σiui=λi=σi1Avi
这里的σ就是上面说的奇异值,u就是上面说的左奇异向量。奇异值σ跟特征值类似,在矩阵Σ中也是从大到小排列,而且σ的减少特别的快,在很多情况下,前10%甚至1%的奇异值的和就占了全部的奇异值之和的99%以上了。也就是说,我们也可以用前r大的奇异值来近似描述矩阵,这里定义一下部分奇异值分解:
A m × n ≈ U m × r Σ r × r V r × n T A_{m \times n} \approx U_{m \times r} \Sigma_{r \times r} V_{r \times n}^{T} Am×n≈Um×rΣr×rVr×nT
r是一个远小于m、n的数。右边的三个矩阵相乘的结果将会是一个接近于A的矩阵,在这儿,r越接近于n,则相乘的结果越接近于A。而这三个矩阵的面积之和(在存储观点来说,矩阵面积越小,存储量就越小)要远远小于原始的矩阵A,我们如果想要压缩空间来表示原矩阵A,我们存下这里的三个矩阵:U、Σ、V就好了。
4.奇异值与主成分分析
主成分分析在上一节里面也讲了一些,这里主要谈谈如何用SVD去解PCA的问题。PCA的问题其实是一个基的变换,使得变换后的数据有着最大的方差。方差的大小描述的是一个变量的信息量,我们在讲一个东西的稳定性的时候,往往说要减小方差,如果一个模型的方差很大,那就说明模型不稳定了。但是对于我们用于机器学习的数据(主要是训练数据),方差大才有意义,不然输入的数据都是同一个点,那方差就为0了,这样输入的多个数据就等同于一个数据了。以下面这张图为例子:

这个假设是一个摄像机采集一个物体运动得到的图片,上面的点表示物体运动的位置,假如我们想要用一条直线去拟合这些点,那我们会选择什么方向的线呢?当然是图上标有signal的那条线。如果我们把这些点单纯的投影到x轴或者y轴上,最后在x轴与y轴上得到的方差是相似的(因为这些点的趋势是在45度左右的方向,所以投影到x轴或者y轴上都是类似的),如果我们使用原来的xy坐标系去看这些点,容易看不出来这些点真正的方向是什么。但是如果我们进行坐标系的变化,横轴变成了signal的方向,纵轴变成了noise的方向,则就很容易发现什么方向的方差大,什么方向的方差小了。
一般来说,方差大的方向是信号的方向,方差小的方向是噪声的方向,我们在数据挖掘中或者数字信号处理中,往往要提高信号与噪声的比例,也就是信噪比。对上图来说,如果我们只保留signal方向的数据,也可以对原数据进行不错的近似了。
PCA的全部工作简单点说,就是对原始的空间中顺序地找一组相互正交的坐标轴,第一个轴是使得方差最大的,第二个轴是在与第一个轴正交的平面中使得方差最大的,第三个轴是在与第1、2个轴正交的平面中方差最大的,这样假设在N维空间中,我们可以找到N个这样的坐标轴,我们取前r个去近似这个空间,这样就从一个N维的空间压缩到r维的空间了,但是我们选择的r个坐标轴能够使得空间的压缩使得数据的损失最小。
还是假设我们矩阵每一行表示一个样本,每一列表示一个feature,用矩阵的语言来表示,将一个m * n的矩阵A的进行坐标轴的变化,P就是一个变换的矩阵从一个N维的空间变换到另一个N维的空间,在空间中就会进行一些类似于旋转、拉伸的变化。
A m × n P n × n = A ~ m × n A_{m \times n} P_{n \times n}=\widetilde{A}_{m \times n} Am×nPn×n=A m×n
而将一个m * n的矩阵A变换成一个m * r的矩阵,这样就会使得本来有n个feature的,变成了有r个feature了(r < n),这r个其实就是对n个feature的一种提炼,我们就把这个称为feature的压缩。用数学语言表示就是:
A m × n P n × r = A ~ m × r A_{m \times n} P_{n \times r}=\widetilde{A}_{m \times r} Am×nPn×r=A m×r
但是这个怎么和SVD扯上关系呢?之前谈到,SVD得出的奇异向量也是从奇异值由大到小排列的,按PCA的观点来看,就是方差最大的坐标轴就是第一个奇异向量,方差次大的坐标轴就是第二个奇异向量…我们回忆一下之前得到的SVD式子:
A m × n ≈ U m × r Σ r x x V r × n T A_{m \times n} \approx U_{m \times r} \Sigma_{r x x} V_{r \times n}^{T} Am×n≈Um×rΣrxxVr×nT
在矩阵的两边同时乘上一个矩阵V,由于V是一个正交的矩阵,所以V转置乘以V得到单位阵I,所以可以化成后面的式子
A m × n V r × n ≈ U m × r Σ r × r V r × n T V r × n A m × n V r × n ≈ U m × r Σ r × r r A_{m \times n} V_{r \times n} \approx U_{m \times r} \Sigma_{r \times r} V_{r \times n}^{T} V_{r \times n} \\A_{m \times n} V_{r \times n} \approx U_{m \times r} \Sigma_{r \times r r} Am×nVr×n≈Um×rΣr×rVr×nTVr×nAm×nVr×n≈Um×rΣr×rr
将后面的式子与A * P那个m * n的矩阵变换为m * r的矩阵的式子对照看看,在这里,其实V就是P,也就是一个变化的向量。这里是将一个m * n 的矩阵压缩到一个m * r的矩阵,也就是对列进行压缩,如果我们想对行进行压缩(在PCA的观点下,对行进行压缩可以理解为,将一些相似的sample合并在一起,或者将一些没有太大价值的sample去掉)怎么办呢?同样我们写出一个通用的行压缩例子:
P r × m A m × n = A ~ r × n P_{r \times m} A_{m \times n}=\widetilde{A}_{r \times n} Pr×mAm×n=A r×n
这样就从一个m行的矩阵压缩到一个r行的矩阵了,对SVD来说也是一样的,我们对SVD分解的式子两边乘以U的转置U’
U r × m T A m × n ≈ ∑ r × r V r × n T U_{r \times m}^{T} A_{m \times n} \approx \sum_{r \times r} V_{r \times n}^{T} Ur×mTAm×n≈r×r∑Vr×nT
这样我们就得到了对行进行压缩的式子。可以看出,其实PCA几乎可以说是对SVD的一个包装,如果我们实现了SVD,那也就实现了PCA了,而且更好的地方是,有了SVD,我们就可以得到两个方向的PCA,如果我们对A’A进行特征值的分解,只能得到一个方向的PCA。
三、整体代码
参考代码
参考
机器学习中的数学(5)-强大的矩阵奇异值分解(SVD)及其应用
机器学习实战——SVD(奇异值分解)
奇异值分解(SVD)原理与在降维中的应用
奇异值分解(SVD) — 几何意义
http://www.ams.org/publicoutreach/feature-column/fcarc-svd
apachecn的svd讲解