python/pandas数据分析(十三)-数据清理、转换、合并,重塑
合并数据结构
pandas.merge 根据一个或多个键将不同DataFrame中的行连接起来。
pandas.concat 沿着一条轴将多个对象堆叠起来
具体可以参考之前专门讲数据合并的章节
索引上的合并
有时,DF中的链接键位于其索引中。left_index=True or right_index=True(or 两个都传入)以说明索引应该被用作链接键
left1=pd.DataFrame({'key':list('abaabc'),'value':range(6)})
right1=pd.DataFrame({'group_val':[3.5,7]},index=['a','b'])
left1
right1

pd.merge(left1,right1,left_on='key',right_index=True)
对于层次化索引也适用
righth=pd.DataFrame(np.arange(12).reshape((6,2)),
index=[['Nevada','Nevada','Ohio','Ohio','Ohio','Ohio'],
[2001,2000,2000,2000,2001,2002]],
columns=['event1','event2'])
righth
lefth=pd.DataFrame({'key1':['Ohio','Ohio','Ohio','Nevada','Nevada'],
'key2':[2000,2001,2002,2001,2002],
'data':np.arange(5.)})
lefth
pd.merge(lefth,righth,left_on=['key1','key2'],right_index=True)
DataFrame 还有一个更方便的join方法用于实现按索引进行合并,具体可以参考之前写的文章
轴向连接
concat axis=1 列
合并重叠数据
np.where 实现一种矢量化的if-else
np.where(pd.isnull(a),b,a)重塑(reshape)与轴向转换(pivot)
stack 将数据的列旋转为行
unstack : 将数据的行旋转为列
ldata=pd.DataFrame(np.arange(12).reshape((4,3)),
columns=['date','item','value'])
ldata
pivoted=ldata.pivot('date','item','value')
pivoted
date, item 连个参数分别用作行和列索引的列名,最后一个参数值则用于填充DF.
增加一列:
ldata['value2']=np.random.randn(len(ldata))
ldata
如果不带最后一个参数则生成一个带有层次化的列 
用set_index 创建层次化的索引
unstacked=ldata.set_index(['date','item'])
unstacked
unstacked.unstack('item')就变成了povit 
移除重复数据
DataFrame中常常出现重复行,如
data1=pd.DataFrame({'k1':['one']*3+['two']*4,
'k2':[1,1,2,3,3,4,4]})
data1!
DataFrame的duplicated方法返回一个布尔型的Series,表示各行是否是重复行
data1.duplicated()
0 False
1 True
2 False
3 False
4 True
5 False
6 True
dtype: bool
drop_duplicates方法返回一个移除了重复行的DataFrame
data1.drop_duplicates()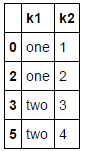
假设你只想过滤还多了一列v1,想过滤这一列的重复项
data1['v1']=range(7)
data1.drop_duplicates(['k1'])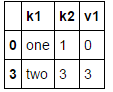
默认保留第一个出现的组合
Map
data3=pd.DataFrame({'food':['bacon','beef','honey ham'],
'ounces': [3,2,1]})
data3
meat_to_animal={
'bacon':'pig',
'beef': 'cow',
'honey ham':'cow'
}
data3['animal']=data3['food'].map(str.lower).map(meat_to_animal)
data3

Series的map方法可以接受一个函数或者含有映射关系的字典型对象
替换值
fillna
map
一次替换一个值
data.replace(-999,np.nan)一次替换多个值
data.replace([-999,-1000], np.nan)对不同的值进行不同的替换
data.replace([-999,-1000],[np.nan,0])传入参数也可以是字典
data.replace({-999:np.nan, -1000:0})重命名
data.rename(index=str.title,columns=str.upper)离散化与面元划分
ages=[20,21,22,24,27,21,23,37,31,64,45,41,32]
bins=[18,25,35,60,100]
cats=pd.cut(ages,bins)
cats
[(18, 25], (18, 25], (18, 25], (18, 25], (25, 35], ..., (25, 35], (60, 100], (35, 60], (35, 60], (25, 35]]
Length: 13
Categories (4, object): [(18, 25] < (25, 35] < (35, 60] < (60, 100]]pandas 返回一个特殊的categorical对象,将其看做一组表示面元名称的字符串。实际上,他含有一个表示不同分类名称的levels数组以及一个座位年龄数据进行标号的labels属性
cats.codes
array([0, 0, 0, 0, 1, 0, 0, 2, 1, 3, 2, 2, 1], dtype=int8)
cats.categories
Index(['(18, 25]', '(25, 35]', '(35, 60]', '(60, 100]'], dtype='object')
pd.value_counts(cats)
(18, 25] 6
(35, 60] 3
(25, 35] 3
(60, 100] 1
dtype: int64qcut 可以按照样本分位数对数据进行面元分隔。
data5=np.random.randn(1000)# 正态分布
cats=pd.qcut(data,4) #按照4分位进行切割检测或者过滤异常值
seed( ) 用于指定随机数生成时所用算法开始的整数值,如果使用相同的seed( )值,则每次生成的随即数都相同,如果不设置这个值,则系统根据时间来自己选择这个值,此时每次生成的随机数因时间差异而不同。
np.random.seed(12345)
data4=pd.DataFrame(np.random.randn(1000,4))
data4.describe()
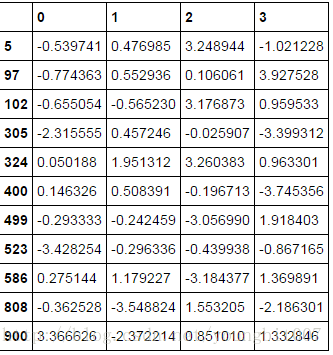
col=data4[3]
col[np.abs(col)>3]
97 3.927528
305 -3.399312
400 -3.745356
Name: 3, dtype: float64
选出绝对值超过3的行
data4[(np.abs(data4)> 3).any(1)]