基于keras框架与mnist数据集的resnet代码详解
先说过程:
①起初是想使用cifar-10数据集进行训练的,由于cifar数据集中的图片size较大,我跑在自己的笔记本电脑上,如果完全按照官方给出的网络结构图来训练时会出现OOM(out of memory)的问题(不排除是当时我代码不够规范造成的)。所以对channel数进行了微调。
②一开始用原生tensorflow编写,在参考网上resnet代码时也是原生tensorflow方法使用得比较多。但是在我自己写这份代码时发现原生tensorflow比较繁杂,不便于debug,于是考虑使用基于原生tensorflow的框架。由于slim框架没找到官方文档,所以改用了keras。keras中文官方文档看这里。用了框架之后代码就变得十分简洁易用啦。
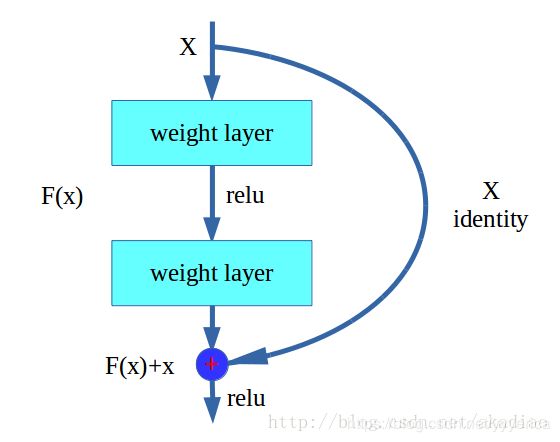
对resnet的理解,我认为简单来说就是将原输入X与经卷积之后的F(X)相加的结果y与真值y_进行比较,从而使网络不必学习如何拟合整个y_,而只需要对残差y_ - X = F(x)这部分进行学习即可。这种结构的优点是作用效果与传统网络相同,但是简化了模型的学习。
本文代码所对应的模型结构:
| layer_name | output_size | 9-layer |
| conv1 | 28x28x16 | 3x3,16,stride = 1 |
| conv2 | 14x14x16 | 3x3,16 x2 3x3,16 |
| conv3 | 7x7x32 | 3x3,32 x2 3x3,32 |
| 1x1 | average pool,softmax |
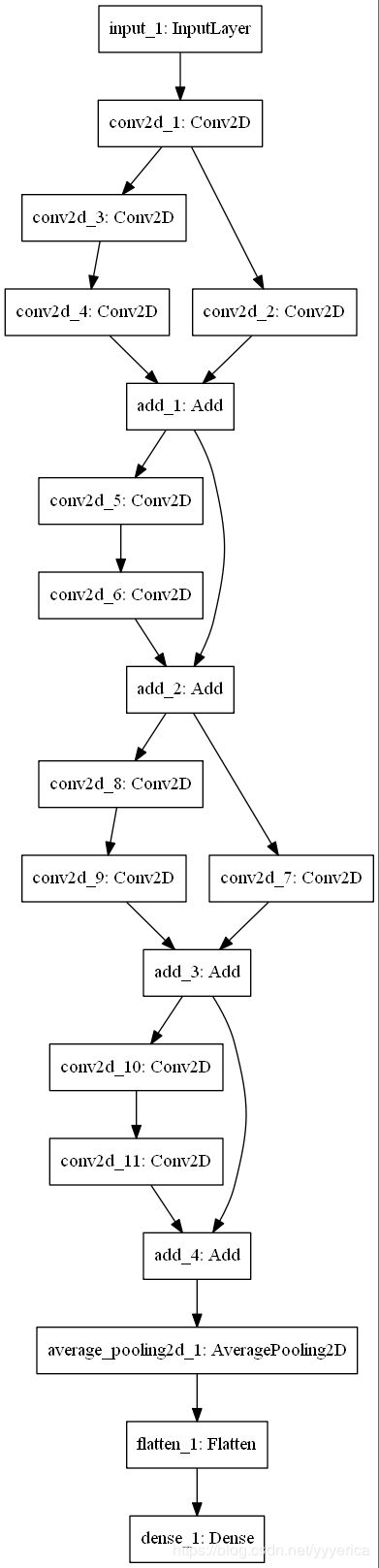
模型构建参考:
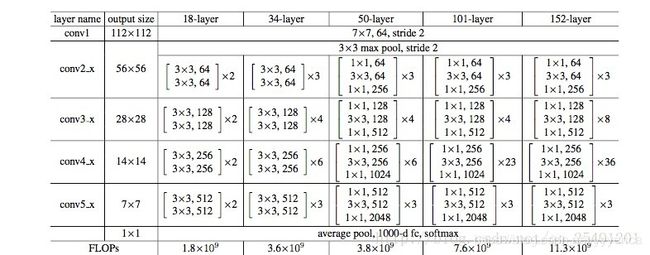
1.图示中的18-layer
2.以及下图的block结构
接下来是代码流程
1.载入数据
import kerasfrom keras.datasets import mnist
(x_train, y_train), (x_test, y_test) = mnist.load_data()
# 数据集会默认下载到C:\Users\xxx\.keras\datasets 中2.将图片像素值范围缩小至0到1
x_train = x_train.astype('float32')
x_test = x_test.astype('float32')
# 将像素范围缩至0到1
x_train /= 255
x_test /= 2553.将labels转换为稠密格式
y_train = keras.utils.to_categorical(y_train, num_classes) # 60000个
y_test = keras.utils.to_categorical(y_test, num_classes) # 10000个4.构建模型
① conv_1(结合数据集对kernel size进行了调整)
# conv_1 28x28→28x28x16
x = Conv2D(16,
kernel_size=(3, 3),
activation='relu',
input_shape=input_shape,
padding='same'
)(inpt)②conv_2 和 conv_3
由于MNIST数据集的输入图像size较小,所以省略了maxpooling这一步骤,防止丢失太多信息
以下是每个block的实现,参数i用于判断当前是第几个block,在第一个block处取步长为2
def res_block(x, channels, i):
if i == 1: # 第二个block
strides = (1, 1)
x_add = x
else: # 第一个block
strides = (2, 2)
# x_add 是对原输入的bottleneck操作
x_add = Conv2D(channels,
kernel_size=(3, 3),
activation='relu',
padding='same',
strides=strides)(x)
x = Conv2D(channels,
kernel_size=(3, 3),
activation='relu',
padding='same')(x)
x = Conv2D(channels,
kernel_size=(3, 3),
padding='same',
strides=strides)(x)
x = add([x, x_add])
Activation(K.relu)(x)
return x
# conv_2 28x28x16→14x14x16
for i in range(2):
x = res_block(x, 16, i)
# conv_3 14x14x16→7x7x32
for i in range(2):
x = res_block(x, 32, i)③最后进行池化和全连接,softmax输出
x = AveragePooling2D(pool_size=(7, 7))(x)
x = Flatten()(x)
x = Dense(num_classes, activation='softmax')(x)
对整个训练集(60000个样本)进行了12轮训练
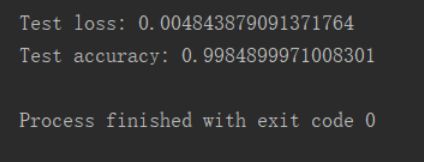
训练集上的正确率 0.99+
测试集上的准确率 0.998
附上完整代码:
from __future__ import print_function
import keras
from keras.datasets import mnist
from keras.layers import Input, Dense, Dropout, Flatten, add
from keras.layers import Conv2D, Activation, MaxPooling2D, AveragePooling2D
from keras import backend as K
from keras.callbacks import ModelCheckpoint
import tensorflow as tf
from keras.models import Model
from keras.utils import plot_model
batch_size = 128
num_classes = 10
epochs = 12 # 训练次数=12*60000
model_path = 'modeldir.mnist'
# input image dimensions
img_rows, img_cols = 28, 28
flag = "train" # one of "train" or "eval"
def res_block(x, channels, i):
if i == 1: # 第二个block
strides = (1, 1)
x_add = x
else: # 第一个block
strides = (2, 2)
# x_add 是对原输入的bottleneck操作
x_add = Conv2D(channels,
kernel_size=(3, 3),
activation='relu',
padding='same',
strides=strides)(x)
x = Conv2D(channels,
kernel_size=(3, 3),
activation='relu',
padding='same')(x)
x = Conv2D(channels,
kernel_size=(3, 3),
padding='same',
strides=strides)(x)
x = add([x, x_add])
Activation(K.relu)(x)
return x
def build_model(input_shape):
inpt = Input(shape=input_shape)
# conv_1 28x28→28x28x16
x = Conv2D(16,
kernel_size=(7, 7),
activation='relu',
input_shape=input_shape,
padding='same'
)(inpt)
# x = MaxPooling2D(pool_size=(3, 3), strides=(2, 2))(x)
# conv_2 28x28x16→14x14x16
for i in range(2):
x = res_block(x, 16, i)
# conv_3 14x14x16→7x7x32
for i in range(2):
x = res_block(x, 32, i)
x = AveragePooling2D(pool_size=(7, 7))(x)
x = Flatten()(x)
x = Dense(num_classes, activation='softmax')(x)
# Construct the model.
model = Model(inputs=inpt, outputs=x)
plot_model(model, to_file='resnet.png')
model.compile(loss=keras.losses.categorical_crossentropy,
optimizer=keras.optimizers.Adadelta(),
metrics=['accuracy'])
return model
def train(model, x_train, y_train, x_test, y_test):
checkpoint = ModelCheckpoint(model_path,
monitor='val_loss', # 保存模型的路径。
verbose=1, # 详细信息模式,0 或者 1 。
save_best_only=True,
save_weights_only=False,
mode='auto',
period=1 # 每个检查点之间的间隔(训练轮数)
)
model.fit(x_train, y_train,
batch_size=batch_size, # 每次梯度更新的样本数
epochs=epochs, # 训练模型迭代轮次。一个轮次是在整个训练集上的一轮迭代
verbose=2, # verbose: 0, 1 或 2。日志显示模式。 0 = 安静模式, 1 = 进度条, 2 = 每轮一行。
validation_data=(x_test, y_test),
callbacks=[checkpoint])
def test(model, x_test, y_test):
model.load_weights(model_path)
model.compile(loss='binary_crossentropy', optimizer='adam', metrics=['accuracy'])
score = model.evaluate(x_test, y_test, verbose=0)
print('Test loss:', score[0])
print('Test accuracy:', score[1])
def main(_):
# the data, split between train and test sets
(x_train, y_train), (x_test, y_test) = mnist.load_data() # 数据集会默认下载到C:\Users\xxx\.keras\datasets 中
if K.image_data_format() == 'channels_first':
x_train = x_train.reshape(x_train.shape[0], 1, img_rows, img_cols)
x_test = x_test.reshape(x_test.shape[0], 1, img_rows, img_cols)
input_shape = (1, img_rows, img_cols)
else:
x_train = x_train.reshape(x_train.shape[0], img_rows, img_cols, 1)
x_test = x_test.reshape(x_test.shape[0], img_rows, img_cols, 1)
input_shape = (img_rows, img_cols, 1)
x_train = x_train.astype('float32')
x_test = x_test.astype('float32')
# 将像素范围缩至0到1
x_train /= 255
x_test /= 255
# convert class vectors to binary class matrices
y_train = keras.utils.to_categorical(y_train, num_classes) # 60000个
y_test = keras.utils.to_categorical(y_test, num_classes) # 10000个
_model = build_model(input_shape)
# x_train(60000, 28, 28, 1), y_train(60000,)
if flag == "train":
train(_model, x_train, y_train, x_test, y_test)
elif flag == "eval":
test(_model, x_test, y_test)
if __name__ == '__main__':
tf.app.run()