Python笔记之自定义函数
Python3 定义函数
- Python3 定义函数
- 定义一个函数
- 语法
- 实例求解二元一次方程
- 函数调用
- 参数传递
- 可更改mutable与不可更改immutable对象
- python 传不可变对象实例
- 传可变对象实例
- 参数
- 必选参数
- 关键字参数
- 默认参数
- 可变参数
- 命名关键字参数
- 位置参数
- 不定长参数
- 可变参数列表
- 参数列表的分拆
- Lambda 形式
- 语法
- return语句
- 文档字符串
- 变量作用域
- 全局变量和局部变量
- global 和 nonlocal关键字
- 参数组合
- 函数注解
- 插曲编码风格
定义一个函数
我们自己可以定义一个由自己想要功能的函数,以下是简单的规则:
- 函数代码块以 def 关键词开头,后接函数标识符名称和圆括号 ()。
- 任何传入参数和自变量必须放在圆括号中间,圆括号之间可以用于定义参数。
- 函数的第一行语句可以选择性地使用文档字符串—用于存放函数说明
- 函数内容以冒号起始,并且缩进。
- return [表达式] 结束函数,选择性地返回一个值给调用方。不带表达式的return相当于返回 None。
通俗的说,在Python中,定义一个函数要使用def语句,依次写出函数名、括号、括号中的参数和冒号:,然后,在缩进块中编写函数体,函数的返回值用return语句返回。
浏览廖雪峰的教程之定义函数,不难发现在python中,我们经常会碰到自定义函数,然后封装好,方便自己随时调用。
语法
Python 定义函数使用def关键字,一般格式如下:
def 函数名(参数列表):
函数体默认情况下,参数值和参数名称是按函数声明中定义的的顺序匹配起来的。
实例求解二元一次方程
以廖雪峰教程上的一个练习(定义一个函数quadratic(a, b, c),接收3个参数,返回一元二次方程: ax2+bx+c=0 a x 2 + b x + c = 0 的两个解)。
import math
import cmath
def quadratic(a,b,c):
delta = b*b-4*a*c
if a == 0:
print('该方程仅有一个根')
x=-c/b
return x
elif delta > 0:
print('该方程有两个不同的根')
x1=(-b+math.sqrt(delta))/(2*a)
#sqrt()是不能直接访问的,需要导入 math 模块,通过静态对象调用该方法
x2=(-b-math.sqrt(delta))/(2*a)
return x1,x2
elif delta < 0:
print('该方程有复数根')
x1=(-b+cmath.sqrt(delta))/(2*a)
#因为delta小于0,需要用到复数模块
x2=(-b-cmath.sqrt(delta))/(2*a)
return x1,x2
else:
print('该方程有两个相同的根')
x1=x2=-b/(2*a)
return x1,x2函数调用
quadratic(a,b,c)我觉得这是一种方式。再来一个,假如我们做数据分析,数据处理一些习以为常的流程,将其写成类或者自定义函数然后调用的话,会提高我们的办事效率的。我将求方程根的自定义函数保存成quadratic.py在我后面需要求根的时候就如下操作:
from quadratic import quadratic
如果我们传进去的参数不是3个,比如就传进去了a,b就会报错
TypeError: quadratic() missing 1 required positional argument:'c'对这个的写法差不多停留在这儿了,我解决了该方程有解的情况,再来改正有两个解的情况
import math
import cmath
print('记住a不能为0,才能称之为二次方程')
def quadratic(a,b,c):
delta = b*b-4*a*c
if delta > 0:
print('该方程有两个不同的根')
x1=(-b+math.sqrt(delta))/(2*a)
x2=(-b-math.sqrt(delta))/(2*a)
return x1,x2
elif delta < 0:
print('该方程有两个复数根')
x1=(-b+cmath.sqrt(delta))/(2*a)
x2=(-b-cmath.sqrt(delta))/(2*a)
return x1,x2
else:
print('该方程没有两个解')其实这样看的话,感觉不舒服啊。但是勉强凑合吧。
参数传递
在 python 中,类型属于对象,变量是没有类型的
可更改(mutable)与不可更改(immutable)对象
在 python 中,strings, tuples, 和 numbers 是不可更改的对象,而 list,dict 等则是可以修改的对象。
- 不可变类型:变量赋值 a=5 后再赋值 a=10,这里实际是新生成一个 int 值对象 10,再让 a 指向它,而 5 被丢弃,不是改变a的值,相当于新生成了a。
- 可变类型:变量赋值 la=[1,2,3,4] 后再赋值 la[2]=5 则是将 list la 的第三个元素值更改,本身la没有动,只是其内部的一部分值被修改了。
python 函数的参数传递:
- 不可变类型:类似 c++ 的值传递,如 整数、字符串、元组。如fun(a),传递的只是a的值,没有影响a对象本身。比如在 fun(a)内部修改 a 的值,只是修改另一个复制的对象,不会影响 a 本身。
- 可变类型:类似 c++ 的引用传递,如 列表,字典。如 fun(la),则是将 la 真正的传过去,修改后fun外部的la也会受影响
python 中一切都是对象,严格意义我们不能说值传递还是引用传递,我们应该说传不可变对象和传可变对象。
python 传不可变对象实例
def ChangeInt( a ):
a = 10
b = 2
ChangeInt(b)
print( b ) # 结果是 2实例中有 int 对象 2,指向它的变量是 b,在传递给 ChangeInt 函数时,按传值的方式复制了变量 b,a 和 b 都指向了同一个 Int 对象,在 a=10 时,则新生成一个 int 值对象 10,并让 a 指向它。
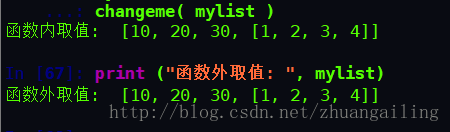
传可变对象实例
# 可写函数说明
def changeme( mylist ):
"修改传入的列表"
mylist.append([1,2,3,4])
print ("函数内取值: ", mylist)
return
# 调用changeme函数
mylist = [10,20,30]
changeme( mylist )
print ("函数外取值: ", mylist)传入函数的和在末尾添加新内容的对象用的是同一个引用。
参数
- 必选参数
- 关键字参数
- 默认参数
- 可变参数
- 命名关键字参数
- 位置参数
- 不定长参数
- 可变参数列表
- 参数列表的分拆
- Lambda 形式
- 文档字符串
- 函数注解
必选参数
必选参数也就是必需参数,须以正确的顺序传入函数。调用时的数量必须和声明时的一样。
关键字参数
关键字参数和函数调用关系紧密,函数调用使用关键字参数来确定传入的参数值。
使用关键字参数允许函数调用时参数的顺序与声明时不一致,因为 Python 解释器能够用参数名匹配参数值。
关键字参数允许传入0个或任意个含参数名的参数,这些关键字参数在函数内部自动组装为一个dict。
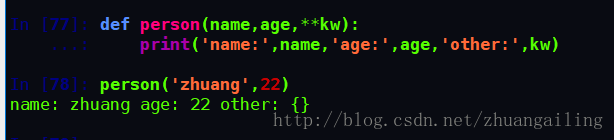
def person(name,age,**kw):
print('name:',name,'age:',age,'other:',kw)函数person除了必选参数name和age外,还接受关键字参数kw。在调用该函数时,可以只传入必选参数:
也可以传入任意个数的关键字参数:
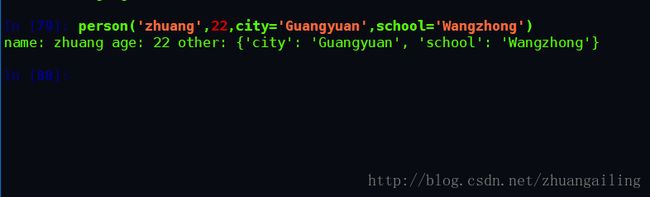
关键字参数有什么用?它可以扩展函数的功能。比如,在person函数里,我们保证能接收到name和age这两个参数,但是,如果调用者愿意提供更多的参数,也能收到。试想做一个用户注册的功能,除了用户名和年龄是必填项外,其他都是可选项,利用关键字参数来定义这个函数就能满足注册的需求。
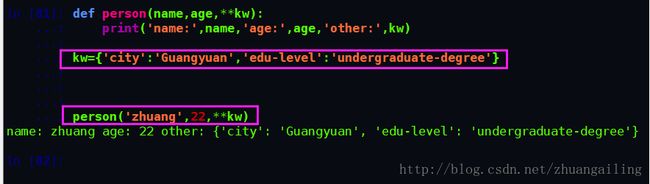
紫色圈的**kw表示把kw这个dict的所有key-value用关键字参数传入到自定义函数的**kw参数,kw将获得一个dict,注意kw获得的dict是紫色圈中kw的一份拷贝,对kw的改动不会影响到函数外圈中的那个kw。
默认参数
默认参数可以简化函数的调用。设置默认参数时,有几点要注意:
- 一是必选参数在前,默认参数在后,否则Python的解释器会报错(思考一下为什么默认参数不能放在必选参数前面)
- 二是如何设置默认参数。当函数有多个参数时,把变化大的参数放前面,变化小的参数放后面。变化小的参数就可以作为默认参数。
使用默认参数最大的好处是能降低调用函数的难度。
例如只需要传入name和age两个参数:
def person(name,age):
print('name:',name)
print('age:',age)调用person()函数就仅仅需要传入两个参数:
person('xiaoming',18)
name: xiaoming
age: 18如果需要加入城市,性别等信息怎么办?则可以将性别和城市设置为默认参数:
def person(name,age,city='Guangyuan',sex='M'):
print('name:',name)
print('age:',age)
print('city:',city)
print('sex:',sex)#调用函数person()
person('xiaogang',19)
name: xiaogang
age: 19
city: Guangyuan
sex: M该是男生的就是男生了呗,那如果是一个女生来报道呢?
person('xiaohong',19,sex='F')这样调用就可以了。可见,默认参数降低了函数调用的难度。但是注意到city参数没传入,看下输出结果
name: xiaohong
age: 19
city: Guangyuan
sex: F看结果,city参数使用的是默认值,在廖雪峰的教程中,有讲到默认参数也有个最大的坑。
def add_end(list1=[]):
list1.append('END')
return list1
其实这个不难理解,因为默认参数list1是[],而不是None,每次调用该函数,如果改变list1的内容,则下次调用时,默认参数的内容就变了,不再是函数定义时的[]了。
定义默认参数要牢记一点:默认参数必须指向不变对象!
修改一下例子:
def add_end(list1=None):
if list1 is None:
list1 = []
list1.append('END')
return list1
为什么要设计str、None这样的不变对象呢?因为不变对象一旦创建,对象内部的数据就不能修改,这样就减少了由于修改数据导致的错误。此外,由于对象不变,多任务环境下同时读取对象不需要加锁,同时读一点问题都没有。在编写程序时,如果可以设计一个不变对象,那就尽量设计成不变对象。
可变参数
在Python函数中,还可以定义可变参数。顾名思义,可变参数就是传入的参数个数是可变的,可以是1个、2个到任意个,还可以是0个。
由于参数个数不确定,我们可以把元素作为一个list或tuple传进来,这样,函数可以定义如下:
def calc(number):
sum = 0
for n in number:
sum = sum + n
return sum
###函数调用
>>>calc(range(101))这个结果想必高斯同学很清楚,哈哈。
但是调用的时候,需要先组装出一个list或tuple
>>>calc([13,19,23,29,37,41,92])
Out[106]: 254
>>>calc((13,19,23,29,37,41,92))
Out[108]: 254
#利用可变参数,调用函数的方式可以简化成这样:
calc(13,19,23,29,37,41,92)但不幸的是我最后一句报错了。
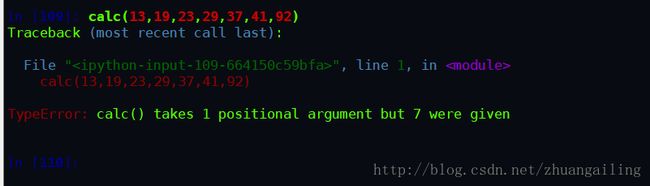
calc()需要1个位置参数,但给出了7个参数。同理,廖雪峰教程上在可变参数调用函数方式简化的地方应该是有问题的,
def calc(*number):
sum = 0
for n in number:
sum = sum + n
return sum将函数的参数改为可变参数,一下就可以了。
>>>calc(1,2,3,4,5,6,7,8,9)
Out[115]: 45假如我们有一个lilst和tuple呢?可以这样:
>>>tuple1=(1,2,3,4,5,6,7,8,9,10)
calc(*tuple1)
Out[116]: 55*tuple1表示把tuple1这个list的所有元素作为可变参数传进去。这种写法相当有用,而且很常见
命名关键字参数
对于关键字参数,函数的调用者可以传入任意不受限制的关键字参数。至于到底传入了哪些,就需要在函数内部通过kw检查。
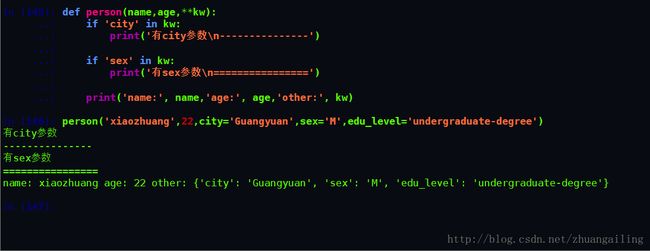
调用者仍可以传入不受限制的关键字参数,但是我发现了个问题
假如我们是这样调用的:
>>>person('xiaozhuang',22,city='Guangyuan',sex='M',edu-level='degree')这个就会报错
File "" , line 1
person('xiaozhuang',22,city='Guangyuan',sex='M',edu-level='undergraduate-degree')
^
SyntaxError: keyword can't be an expression问题就出现在edu-level上,python似乎是拒绝的,所以常见的命名法都是edu_level。
如果要限制关键字参数的名字,就可以用命名关键字参数,例如,只接收name, sex作为关键字参数。这种方式定义的函数如下:
def person(name,sex,*,city,age,edu_level):
print('name:', name,'sex:', sex,'city:',city,'age:',age,'edu_level:',edu_level)和关键字参数**kw不同,命名关键字参数需要一个特殊分隔符*,*后面的参数被视为命名关键字参数。
调用方式如下:
>>>person('xiaozhuang',sex='M',city='Guangyuan',age=22,edu_level='undergraduate_degree')
name: xiaozhuang sex: M city: Guangyuan age: 22 edu_level: undergraduate_degree如果函数定义中已经有了一个可变参数,后面跟着的命名关键字参数就不再需要一个特殊分隔符*了:
命名关键字参数必须传入参数名,这和位置参数不同。如果没有传入参数名,调用将报错:
def person(name,sex,*city,age,edu_level):
print('name:', name,'sex:', sex,'city:',city,'age:',age,'edu_level:',edu_level)
>>>person('xiaozhuang',sex='M',city='Guangyuan',age=22,edu_level='undergraduate_degree')
Traceback (most recent call last):
File "" , line 1, in person('xiaozhuang',sex='M',city='Guangyuan',age=22,edu_level='undergraduate_degree')
TypeError: person() got an unexpected keyword argument 'city' 给到city不是所要的关键字参数
def person(name,sex,*args,city,age,edu_level):
print('name:', name,'sex:', sex,'city:',city,'age:',age,'edu_level:',edu_level)
#############再次调用
>>>person('xiaozhuang','M',city='Guangyuan',age=22,edu_level='undergraduate_degree')
name: xiaozhuang sex: M city: Guangyuan age: 22 edu_level: undergraduate_degree 一下子就听话了,
命名关键字参数可以有缺省值,从而简化调用:
def person(name,sex,*args,city='Guangyuan',age,edu_level='undergraduate_degree'):
print('name:', name,'sex:', sex,'city:',city,'age:',age,'edu_level:',edu_level) 其中city和edu_level具有默认值,调用的时候可以不用传入这两个参数。
>>>person('xiaozhuang','M',age=22)
name: xiaozhuang sex: M city: Guangyuan age: 22 edu_level: undergraduate_degree使用命名关键字参数时,要特别注意,如果没有可变参数,就必须加一个*作为特殊分隔符。如果缺少*,Python解释器将无法识别位置参数和命名关键字参数,从而被视为位置参数。
位置参数
def person(name,age):
print('name:',name,'age:',age)其中,name和age就是位置参数,定义函数person()来讲,有两个位置参数,也是必须传进去的两个参数。
不定长参数
可能需要一个函数能处理比当初声明时更多的参数。这些参数叫做不定长参数,和上述2种参数不同,声明时不会命名。这个见可变参数,两者说的是一样的。
可变参数列表
一个最不常用的选择是可以让函数调用可变个数的参数。这些参数被包装进一个元组。在这些可变个数的参数之前,可以有零到多个普通的参数。任何出现在 *args后的参数是关键字参数,这意味着,他们只能被用作关键字,而不是位置参数,这个也可以看可变参数
参数列表的分拆
当你要传递的参数已经是一个列表,但要调用的函数却接受分开一个个的参数值。这时候你要把已有的列表拆开来。例如内建函数range()需要要独立的start,stop 参数。你可以在调用函数时加一个* 操作符来自动把参数列表拆开:
>>>list(range(10))
>>>args=[1,10]
>>>list(range(*args))
Out[171]: [1, 2, 3, 4, 5, 6, 7, 8, 9]以同样的方式,可以使用**操作符分拆关键字参数为字典:
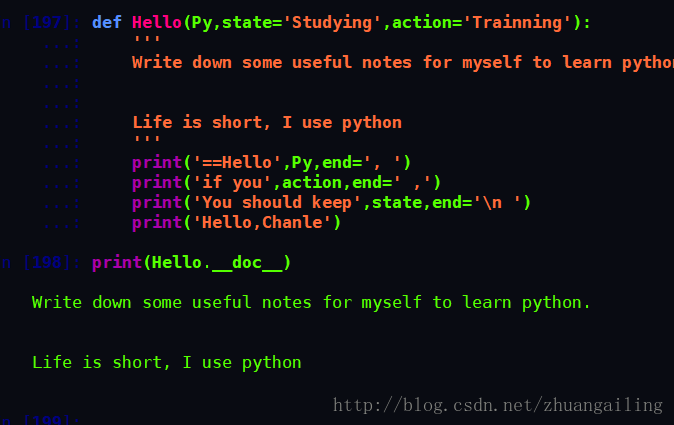
def Hello(Py,state='Studying',action='Trainning'):
print('==Hello',Py,end=', ')
print('if you',action,end=' ,')
print('You should keep',state,end='\n ')
print('Hello,Chanel')
>>>d={'Py':'Python','state':'studying','action':'trainning'}
>>> Hello(**d)
==Hello Python, if you trainning ,You should keep studying
Hello,ChanelLambda 形式
python 使用 lambda 来创建匿名函数,所谓匿名,意即不再使用 def 语句这样标准的形式定义一个函数。通过 lambda 关键字,可以创建短小的匿名函数。这里有一个函数返回它的两个参数的和:lambda a, b: a+b。 Lambda 形式可以用于任何需要的函数对象。出于语法限制,它们只能有一个单独的表达式。语义上讲,它们只是普通函数定义中的一个语法技巧。类似于嵌套函数定义,lambda形式可以从外部作用域引用变量。
- lambda 只是一个表达式,函数体比 def 简单很多。
- lambda的主体是一个表达式,而不是一个代码块。仅仅能在lambda表达式中封装有限的逻辑进去。
- lambda 函数拥有自己的命名空间,且不能访问自己参数列表之外或全局命名空间里的参数。
- 虽然lambda函数看起来只能写一行,却不等同于C或C++的内联函数,后者的目的是调用小函数时不占用栈内存从而增加运行效率。
语法
lambda [arg1 [,arg2,…..argn]]:expression
def f(x,y):
return x**y
####lambda
g = lambda x,y:x**y显然后者要简洁的多。
return语句
return 表达式———语句用于退出函数,选择性地向调用方返回一个表达式。不带参数值的return语句返回None。
文档字符串
第一行应该是关于对象用途的简介。简短起见,不用明确的陈述对象名或类型,因为它们可以从别的途径了解到(除非这个名字碰巧就是描述这个函数操作的动词)。这一行应该以大写字母开头,以句号结尾。
如果文档字符串有多行,第二行应该空出来,与接下来的详细描述明确分隔。接下来的文档应该有一或多段描述对象的调用约定、边界效应等。
Python 的解释器不会从多行的文档字符串中去除缩进,所以必要的时候应当自己清除缩进。这符合通常的习惯。第一行之后的第一个非空行决定了整个文档的缩进格式。(我们不用第一行是因为它通常紧靠着起始的引号,缩进格式显示的不清楚。)留白“相当于”是字符串的起始缩进。每一行都不应该有缩进,如果有缩进的话,所有的留白都应该清除掉。留白的长度应当等于扩展制表符的宽度(通常是8个空格)。
变量作用域
Python 中,程序的变量并不是在哪个位置都可以访问的,访问权限决定于这个变量是在哪里赋值的。
变量的作用域决定了在哪一部分程序可以访问哪个特定的变量名称。Python的作用域一共有4种,分别是:
- L (Local) 局部作用域
- E (Enclosing) 闭包函数外的函数中
- G (Global) 全局作用域
- B (Built-in) 内建作用域
以 L –> E –> G –>B 的规则查找,即:在局部找不到,便会去局部外的局部找(例如闭包),再找不到就会去全局找,再者去内建中找。
x = int(20.501) # 内建作用域
f_count= 10 # 全局作用域
def outer():
o_count = 9 # 闭包函数外的函数中
def inner():
g_count = 8 #局部作用域Python 中只有模块(module),类(class)以及函数(def、lambda)才会引入新的作用域,其它的代码块(如 if/elif/else/、try/except、for/while等)是不会引入新的作用域的,也就是说这这些语句内定义的变量,外部也可以访问.如果是在定义函数中,则是局部变量,外部不能访问
if True:
hi = 'Hello,Chanel'
>>>hi
Out[203]: 'Hello,Chanel'
####
def test():
mas='you are gay'
#看看mas变量能用不
>>>mas
Traceback (most recent call last):
File "" , line 1, in
mas
NameError: name 'mas' is not defined 从报错的信息上看,说明了 msg_inner 未定义,无法使用,因为它是局部变量,只有在函数内可以使用。
全局变量和局部变量
定义在函数内部的变量拥有一个局部作用域,定义在函数外的拥有全局作用域。
局部变量只能在其被声明的函数内部访问,而全局变量可以在整个程序范围内访问。调用函数时,所有在函数内声明的变量名称都将被加入到作用域中。

global 和 nonlocal关键字
当内部作用域想修改外部作用域的变量时,就要用到global和nonlocal关键字
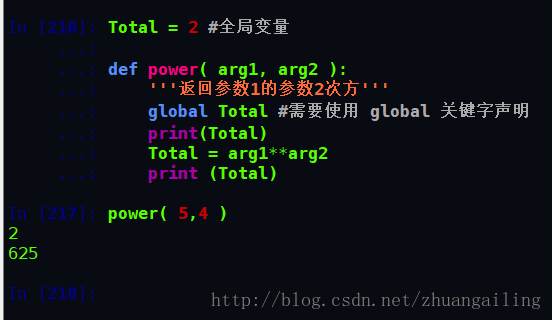 我们看到了Total发生了改变
我们看到了Total发生了改变
如果要修改嵌套作用域(enclosing 作用域,外层非全局作用域)中的变量则需要 nonlocal 关键字
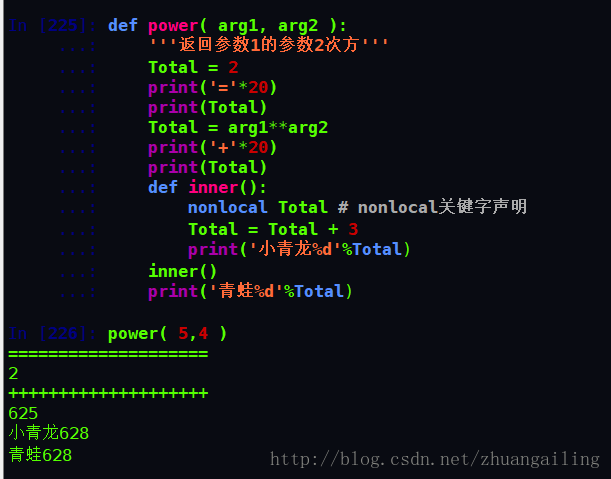
我要是把Total搞成全局变量呢?
File "" , line 11
nonlocal Total # nonlocal关键字声明
^
SyntaxError: no binding for nonlocal 'Total' found一下废了。。。
外有提到的特殊情况
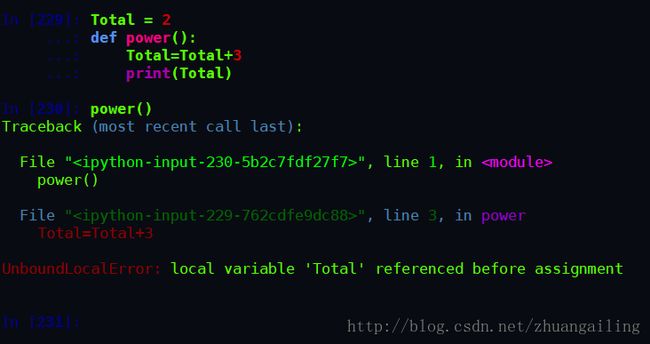
错误信息为局部作用域引用错误,因为power() 函数中的 Total 使用的是局部,未定义,无法修改。而且我在spyder编辑的时候就在给我预警错误了。
参数组合
在Python中定义函数,可以用必选参数、默认参数、可变参数、关键字参数和命名关键字参数,这5种参数都可以组合使用。但是请注意,参数定义的顺序必须是:必选参数、默认参数、可变参数、命名关键字参数和关键字参数。
def f(a,b,c=0,*args,**kw):
print('a:',a,'b:',b,'c:',c,'args:',args,'kw:',kw)
>>>f(1,2)
a: 1 b: 2 c: 0 args: () kw: {}
>>>f(1,2,3,4,5,'oppo','huawei','apple')
a: 1 b: 2 c: 3 args: (4, 5, 'oppo', 'huawei', 'apple') kw: {}
>>>f(0,1,'oppox9','honor8','apple6x',qq='mayun',tengxun='mahuateng',age=30)
a: 0 b: 1 c: oppox9 args: ('honor8', 'apple6x') kw: {'qq': 'mayun', 'tengxun': 'mahuateng', 'age': 30}很容易注意到args和kw分别返回的元组和字典。
其实很容易可以猜到,是否可以通过已有的元组和字典来调用函数呢?答案是肯定的。
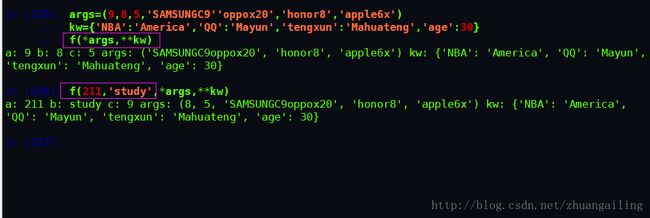
看起来还不错啊,虽然可以组合多达5种参数,但不要同时使用太多的组合,否则函数接口的可理解性很差。
函数注解
函数注解 是关于用户自定义的函数的完全可选的、随意的元数据信息。无论 Python 本身或者标准库中都没有使用函数注解。
注解是以字典形式存储在函数的 __annotations__ 属性中,对函数的其它部分没有任何影响。参数注解(Parameter annotations)是定义在参数名称的冒号后面,紧随着一个用来表示注解的值得表达式。返回注释(Return annotations)是定义在一个->后面,紧随着一个表达式,在冒号:``与-> `之间。
def f(zhuang: 22, like: int = 'Chanel') -> "Nothing to see here":
print("Annotations:", f.__annotations__)
print("Arguments:", zhuang, age)
>>>f('Hello')
Annotations: {'zhuang': 22, 'like': <class 'int'>, 'return': 'Nothing to see here'}
Arguments: Hello Chanel插曲:编码风格
- 使用 4 空格缩进,而非 TAB
- 在小缩进(可以嵌套更深)和大缩进(更易读)之间,4空格是一个很好的折中。TAB 引发了一些混乱,最好弃用
- 折行以确保其不会超过 79 个字符
- 这有助于小显示器用户阅读,也可以让大显示器能并排显示几个代码文件
- 使用空行分隔函数和类,以及函数中的大块代码
- 可能的话,注释独占一行
- 使用文档字符串
- 把空格放到操作符两边,以及逗号后面,但是括号里侧不加空格:
a = f(1, 2) + g(3, 4) - 统一函数和类命名
- 推荐类名用
驼峰命名, 函数和方法名用小写_和_下划线。总是用self作为方法的第一个参数 - 不要使用花哨的编码,如果你的代码的目的是要在国际化环境。Python 的默认情况下,UTF-8,甚至普通的 ASCII 总是工作的最好
- 同样,也不要使用非 ASCII 字符的标识符,除非是不同语种的会阅读或者维护代码。