自然语言处理的情感分析之TextBlob& SnowNLP
一、 TextBlob 包--英文分析
TextBlob是一个用于处理文本数据的Python库。它为常见的自然语言处理(NLP)任务提供了一个简单的API,例如词性标注,名词短语提取,情感分析,分类,翻译等。GitHub链接:https://github.com/sloria/TextBlob
from textblob import TextBlob
text = "I am happy today. I feel sad today."
blob = TextBlob(text)
#分句
blob = blob.sentences
print(blob)
#第一句的情感分析
first = blob.sentences[0].sentiment
print(first)
#第二句的情感分析
second = blob.sentences[1].sentiment
print(second)
#总的
all= blob.sentiment
print(all)

情感极性0.8,主观性1.0。说明一下,情感极性的变化范围是[-1, 1],-1代表完全负面,1代表完全正面。
第二句result:

总的result:

两句合起来评价后你肯定发现了问题——“sad”这个词表达了强烈的负面情感,为何得分依然是正的?
这是因为SnowNLP和textblob的计分方法不同。SnowNLP的情感分析取值,表达的是“这句话代表正面情感的概率”。也就是说,对“我今天很愤怒”一句,SnowNLP认为,它表达正面情感的概率很低很低。
二、 SnowNLP包--中文分析
SnowNLP是一个python写的类库,可以方便的处理中文文本内容,是受到了TextBlob的启发而写的,由于现在大部分的自然语言处理库基本都是针对英文的,于是写了一个方便处理中文的类库,并且和TextBlob不同的是,这里没有用NLTK,所有的算法都是自己实现的,并且自带了一些训练好的字典。
from snownlp import SnowNLP
s = SnowNLP(u'这个东西真心赞')
s1=SnowNLP(u'还是很 设施也不错但是 和以前 比急剧下滑了 和客房 的服务极差幸好我不是很在乎')
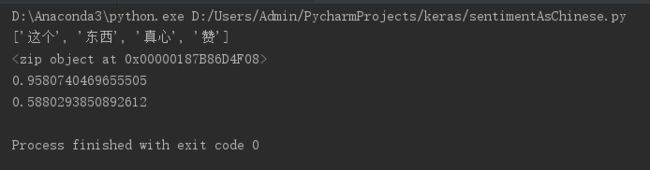
s.words # [u'这个', u'东西', u'真心',
# u'很', u'赞']
print(s.words)
s.tags # [(u'这个', u'r'), (u'东西', u'n'),
# (u'真心', u'd'), (u'很', u'd'),
# (u'赞', u'Vg')]
print(s.tags)
p =s.sentiments # 0.9769663402895832 positive的概率
print(p)
print(s1.sentiments)result:
可以看出第二句的评价是有好有坏的,所以很难分析出这是一句代表正面还是负面的评价,positive的概率也在0.5左右。
SnowNLP用于情感分析方面(现在训练数据主要是买卖东西时的评价,所以对其他的一些可能效果不是很好),而且它的分词能力并没有jieba强大。
三、SnowNLP原理
snownlp情感分析的源码:
1.Sentiment类的代码
class Sentiment(object):
def __init__(self):
self.classifier = Bayes() # 使用的是Bayes的模型
def save(self, fname, iszip=True):
self.classifier.save(fname, iszip) # 保存最终的模型
def load(self, fname=data_path, iszip=True):
self.classifier.load(fname, iszip) # 加载贝叶斯模型
# 分词以及去停用词的操作
def handle(self, doc):
words = seg.seg(doc) # 分词
words = normal.filter_stop(words) # 去停用词
return words # 返回分词后的结果
def train(self, neg_docs, pos_docs):
data = []
# 读入负样本
for sent in neg_docs:
data.append([self.handle(sent), 'neg'])
# 读入正样本
for sent in pos_docs:
data.append([self.handle(sent), 'pos'])
# 调用的是Bayes模型的训练方法
self.classifier.train(data)
def classify(self, sent):
# 1、调用sentiment类中的handle方法
# 2、调用Bayes类中的classify方法
ret, prob = self.classifier.classify(self.handle(sent)) # 调用贝叶斯中的classify方法
if ret == 'pos':
return prob
return 1-probclass Sentiment(object):
def __init__(self):
self.classifier = Bayes() # 使用的是Bayes的模型
def save(self, fname, iszip=True):
self.classifier.save(fname, iszip) # 保存最终的模型
def load(self, fname=data_path, iszip=True):
self.classifier.load(fname, iszip) # 加载贝叶斯模型
# 分词以及去停用词的操作
def handle(self, doc):
words = seg.seg(doc) # 分词
words = normal.filter_stop(words) # 去停用词
return words # 返回分词后的结果
def train(self, neg_docs, pos_docs):
data = []
# 读入负样本
for sent in neg_docs:
data.append([self.handle(sent), 'neg'])
# 读入正样本
for sent in pos_docs:
data.append([self.handle(sent), 'pos'])
# 调用的是Bayes模型的训练方法
self.classifier.train(data)
def classify(self, sent):
# 1、调用sentiment类中的handle方法
# 2、调用Bayes类中的classify方法
ret, prob = self.classifier.classify(self.handle(sent)) # 调用贝叶斯中的classify方法
if ret == 'pos':
return prob
return 1-prob
可以看到classify函数和train函数是两个核心的函数,其中,train函数用于训练一个情感分类器,classify函数用于预测。在这两个函数中,都同时使用到的handle函数,handle函数的主要工作为:1.对输入文本分词 2.去停用词
2.情感分类的基本模型是贝叶斯模型Bayes。
贝叶斯模型的训练和预测:
(1)贝叶斯模型的训练过程实质上是在统计每一个特征出现的频次,其核心代码如下:
def train(self, data):
# data 中既包含正样本,也包含负样本
for d in data: # data中是list
# d[0]:分词的结果,list
# d[1]:正/负样本的标记
c = d[1]
if c not in self.d:
self.d[c] = AddOneProb() # 类的初始化
for word in d[0]: # 分词结果中的每一个词
self.d[c].add(word, 1)
# 返回的是正类和负类之和
self.total = sum(map(lambda x: self.d[x].getsum(), self.d.keys())) # 取得所有的d中的sum之和
(2)贝叶斯模型的使用的就是贝叶斯定理算概率的公式了(其中还涉及到一些公式简化的过程),对应代码如下:
def classify(self, x):
tmp = {}
for k in self.d: # 正类和负类
tmp[k] = log(self.d[k].getsum()) - log(self.total) # 正类/负类的和的log函数-所有之和的log函数
for word in x:
tmp[k] += log(self.d[k].freq(word)) # 词频,不存在就为0
ret, prob = 0, 0
for k in self.d:
now = 0
try:
for otherk in self.d:
now += exp(tmp[otherk]-tmp[k])
now = 1/now
except OverflowError:
now = 0
if now > prob:
ret, prob = k, now
return (ret, prob)