前言:
由于博主之前没有从事过hadoop相关的开发工作,最近正好遇到一个hadoop相关的项目,于是决定自学研究一下,博主整理的东西绝对是最全最详细的,不要问为什么,
因为博主为了搭建hadoop环境几乎以及把网上所有的教程都看了一遍,很多文章都是缺东少西的,博主几乎是尝遍了所有的方法,最后终结出一篇可行的方案分享给大家,所需的软件都可以在官网下载,找不到的可以私聊我,我会在第一时间把所有的软件包给你。编写不易,转载请注明出处。
Hadoop伪分布式搭建说明
-
如图片与文字不符合,以文字为准。
-
IP地址自行替换本机IP地址。
-
软件准备
操作系统文件:CentOS-6.8-x86_64-bin-DVD1.iso
虚拟机文件:VMware_player_7.0.0_2305329.1420626349
JAVA文件(RPM包):jdk-8u101-linux-x64.rpm
Hadoop文件:hadoop-2.7.3.tar.gz
hadoop-eclipse:hadoop-eclipse-plugin-2.7.3.jar
远程端控制软件:Putty_V0.63.0.0.43510830;Bitvise SSH Client 4.5
-
VMware_player_7.0.0虚拟机安装步骤
1.进入VMware Player安装向导
2.选择:我接受许可协议中的条款

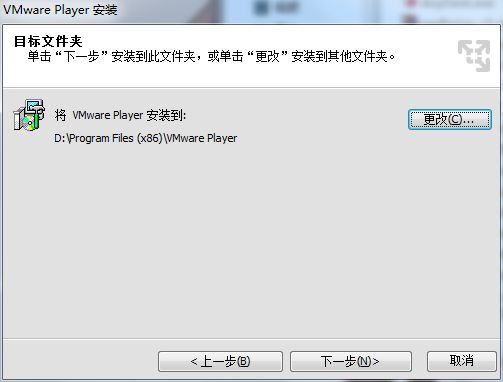
3.更改安装路径,建议不要放在C盘下。
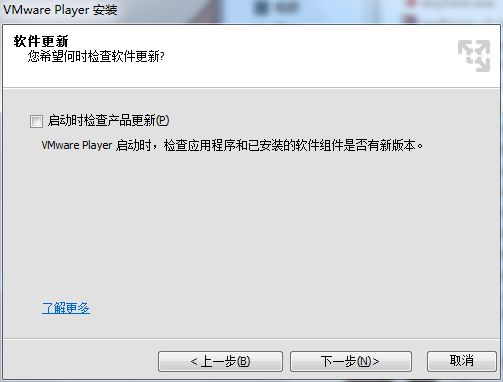
4.取消打勾选项:启动时检查产品更新。
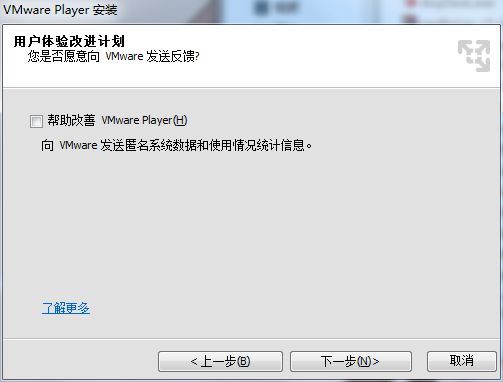
5.取消打勾选项:帮助改善 VMware Player(H)。
6.打勾选项:桌面与开始菜单程序文件夹。
7.选择:继续。

8.等待几分钟安装程序
9.选择:完成。完成安装VMware Player。

-
安装CentOS-6.8-x86_64虚拟机
1.进入VMware Player 7选择:免费将VMware Player 7用于非商业用途。并填写邮箱。
2.选择完成。
3.选择:创建新虚拟机(N),进入新建虚拟机向导。
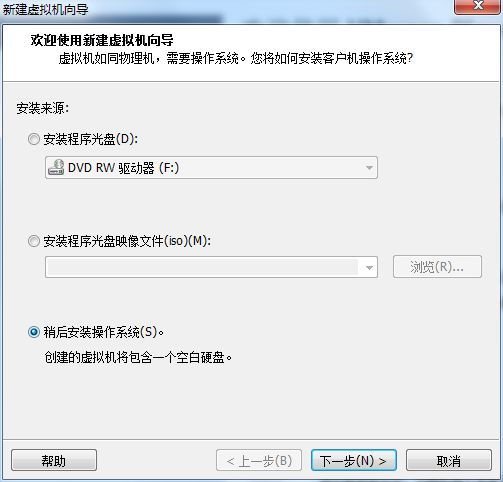
4.选择:稍后安装操作系统(S)。
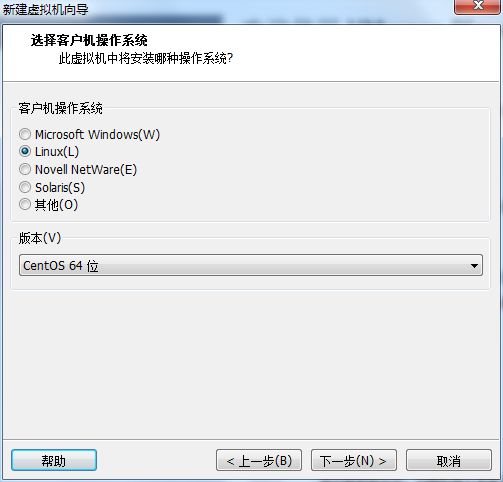
5.客户机操作系统中选择Linux(L),版本(V)选择CentOS 64位。
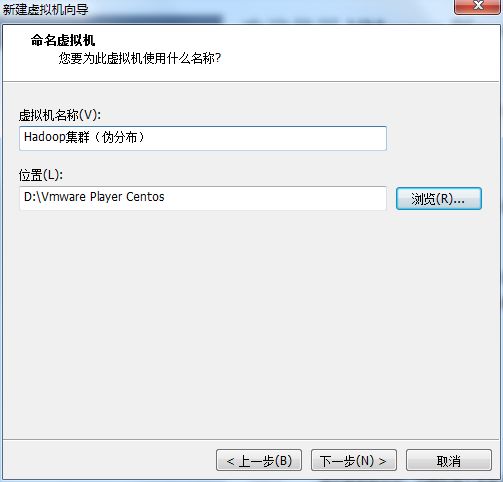
6.修改:虚拟机名称(V):Hadoop集群(伪分布)。位置自定义,建议不要放在C盘。
7.由于是虚拟的测试环境。故最大磁盘大小(GB)(S)选择默认值:20G。
存储文件方式:选择将虚拟磁盘存储为单个文件(O)。
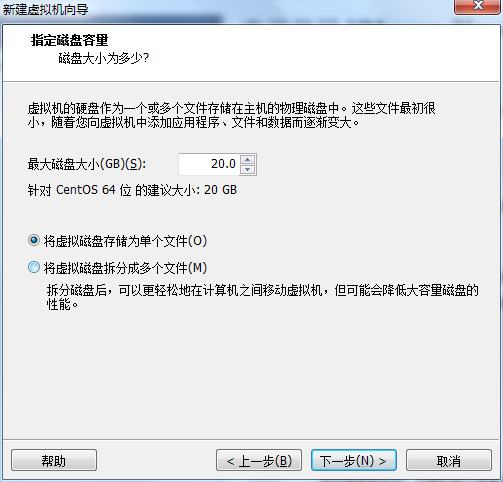
8.选择:自定义硬件。

9.选择硬件选项卡的CD/DVD(IDE),连接选项,点击使用ISO映像文件(M):将CentOS-6.8-x86_64-bin-DVD1.iso添加。最后点击:确定。
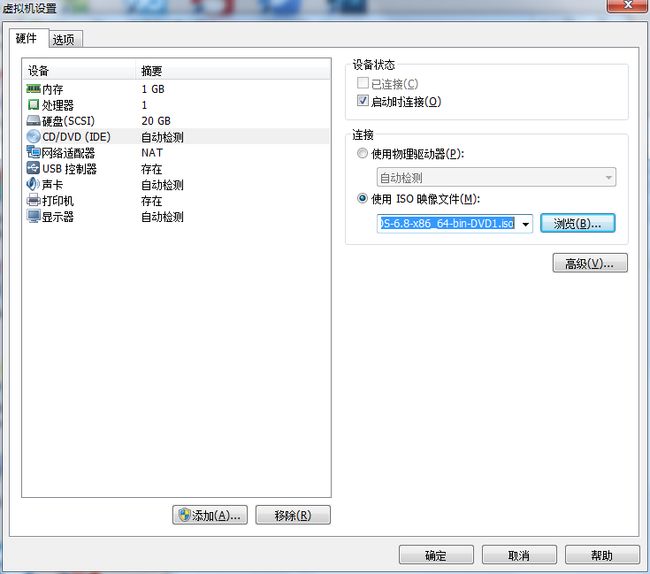
10.点击播放虚拟机(L)。打开新建完成的虚拟机。
11.系统会自动加载ISO文件。出现CentOS-6.8-x86_64的安装界面准备环境。
选择:lnstall or upgrade an existing system。进入正式的操作系统安装。

12.载入安装的图形化界面。
13.跳过检测光盘介质。因为下载的是一个完整的ISO文件。所以不需要检测。
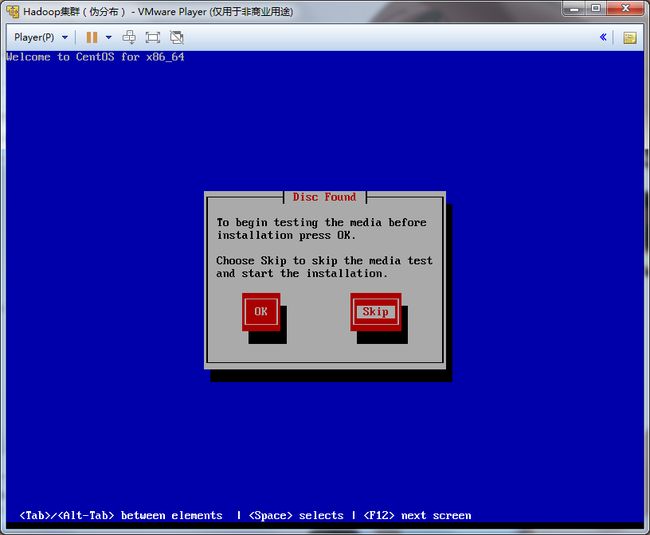
14.正式进入CentOS-6.8-x86_64安装界面。

15.选择安装过程的语言:English(English)。(中文安装可能会有不必要的乱码)

16.选择系统键盘输入语言:U.S.English。(中文输入可能产生不必要的乱码)
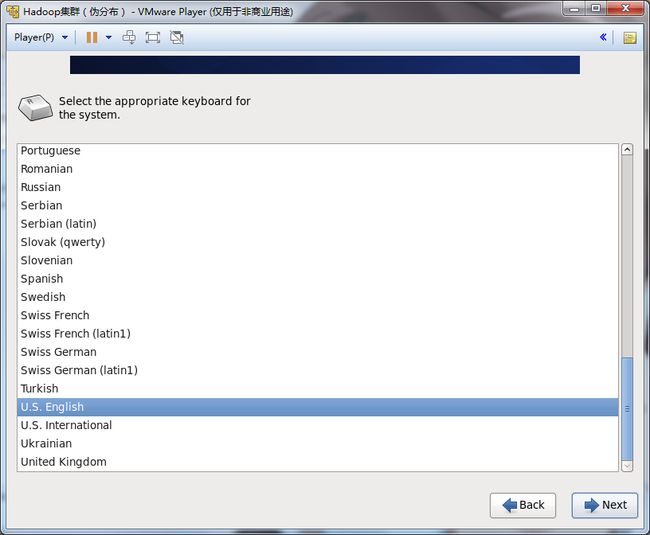
17.选择一种存储设备进行安装。选择:Basic Storage Devices。
Basic Storage Devices(基本存储设备):用于台式机和笔记本等等。
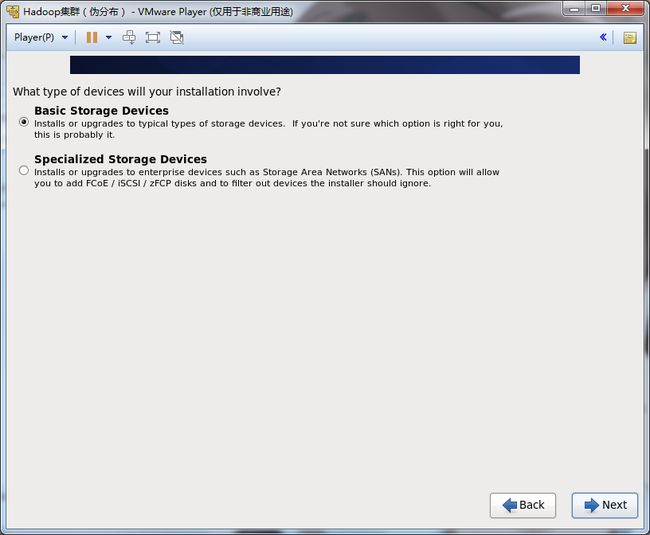
18.这里系统会检测是否有分区,一开始创建的硬盘没有分区。直接选择Yes,discard any data(清除所有数据)。
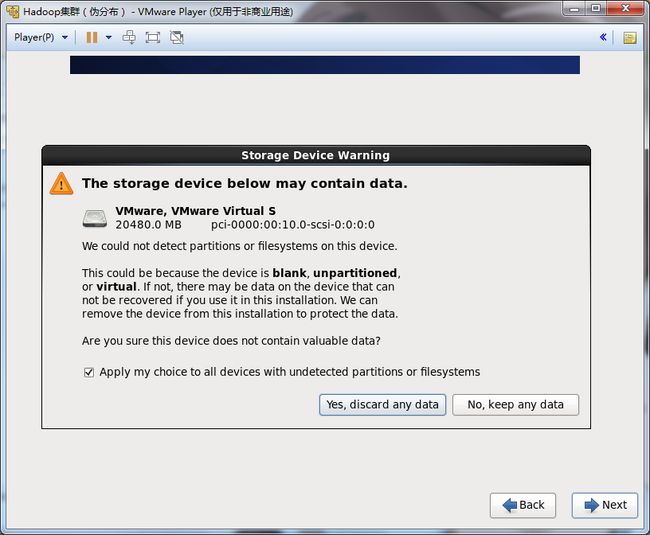
19.填写Hostname:hadoop。
并点击Configure Network,配置网络。
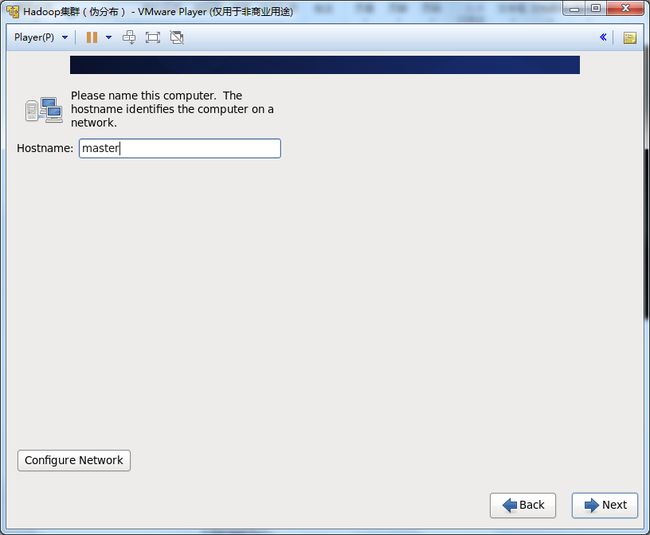
20.选中System eth0,点击Edit网卡。
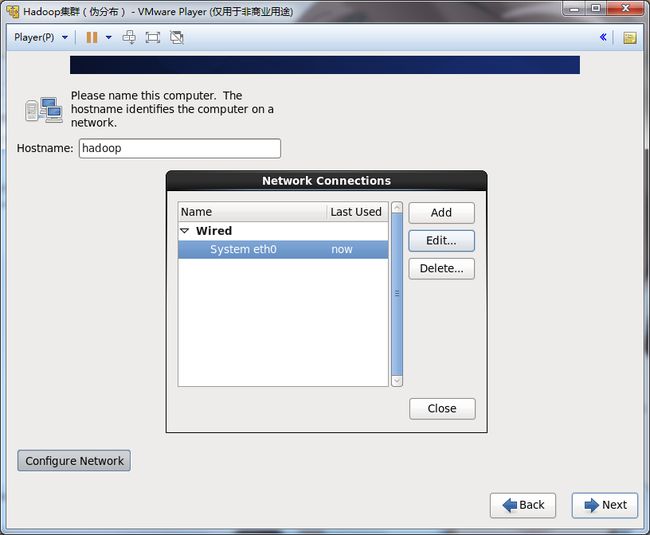
21.将Connect automatically选项打勾。
IPv4 Settings中Method选择:Automatic(DHCP)。
选择Apply,确认修改。
这样开始,系统开始时,会自动连接网卡,并且由DHCP自动分配IP地址。
【注:不同的环境不同的实施方案,这里仅仅讨论此连接方式】
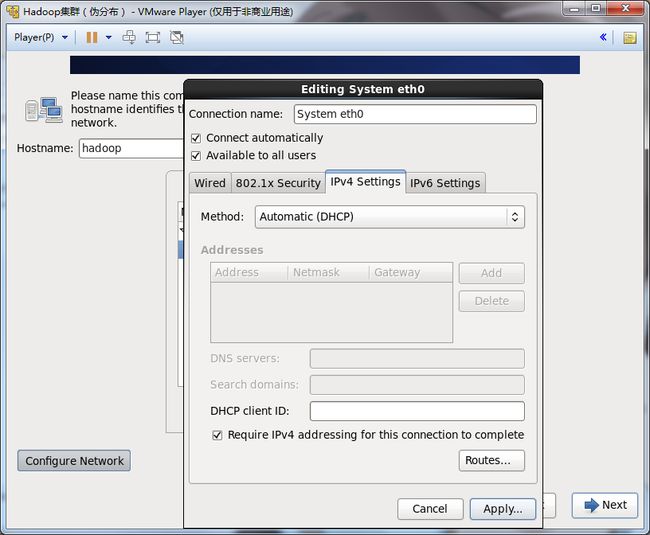
22.选择:Close,关闭。

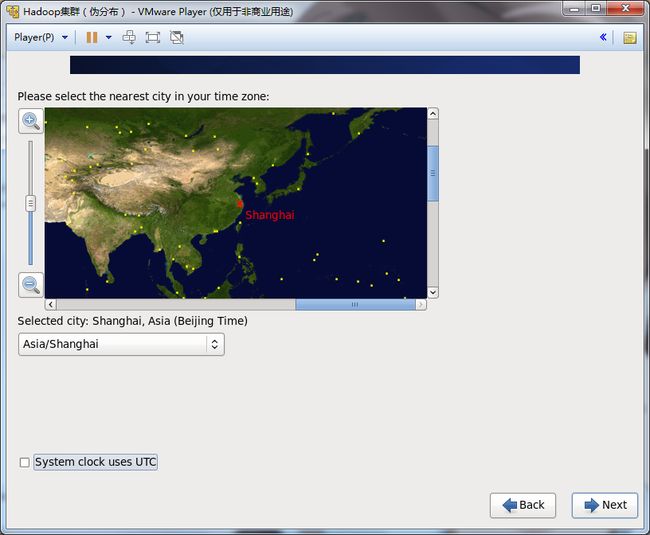
22.选择:Asia/Shanghai时区
将System clock uses UTC打勾项目取消。
23.设置root密码,这里设置为:hadoop。
24.由于hadoop是一个弱口令(在字典中可以找到)。所以系统提示是否使用弱口令。
测试环境无关紧要。生产环境建议使用强口令。
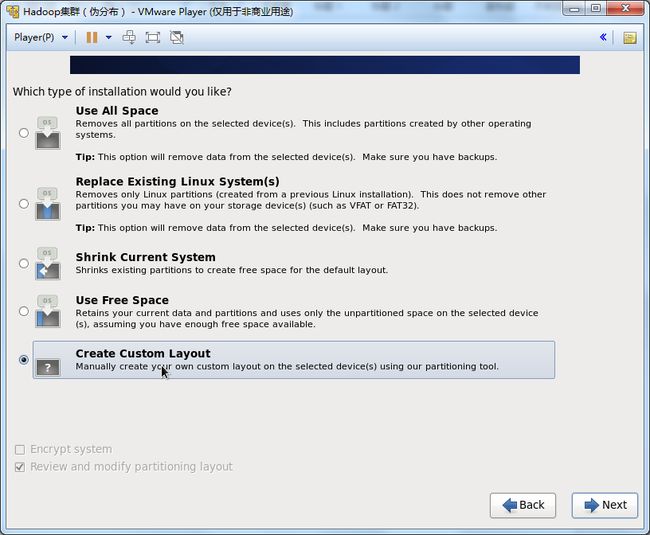
25.虽说是测试环境,但这里参考实际工作,按照实际的要求对硬盘进行分区,合理利用硬盘。
故这里选择:Create Custom Layout,对硬盘进行重新分区。
26.创建/boot,选择1024MB,防止系统扩容。
创建swap,大小是建议是内存的2倍,故为2048MB。
剩下的空间创建/,将剩余空间全部分配/。
【注:此方法是最简单的自定义分区方式。这里就不一一叙述其他分区方式】
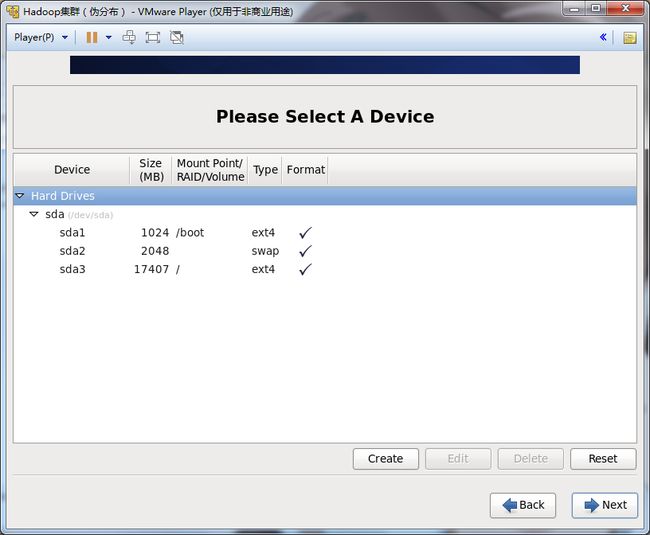
27.选择Format,将分区表格式化。

28.选择Write changes to disk,将分区写入磁盘。
29.此为GRUB引导安装窗口,可采用默认设置,选择next进行下一步安装。
30.选择:Basic Server。
由于hadoop的集群安装不需要桌面。而最小化不适合新手。故选择Basic Server最好。
31.等待安装。

32.安装完成后,选择Reboot进行重启。
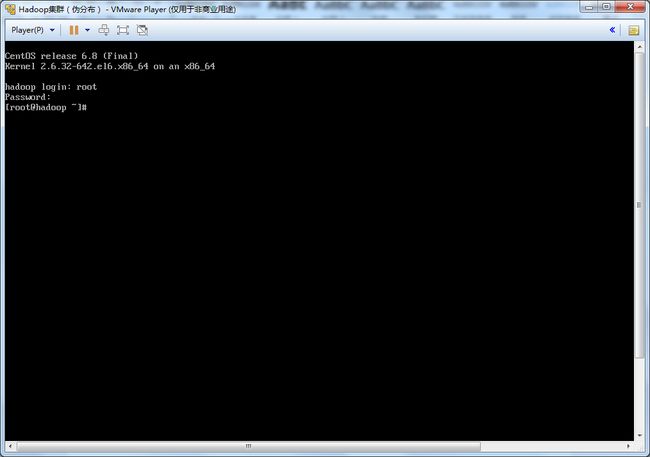
33.安装完成后,输入hadoop login:root;password:hadoop。成功进入操作系统。
3.Hadoop集群搭建(伪分布式)
-
使用Putty登录Centos
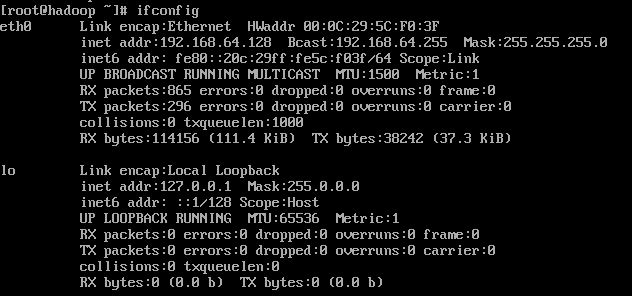
1.通过VMware Player登录到系统,使用ifconfig命令查看eth0的IPv4地址:192.168.64.128.
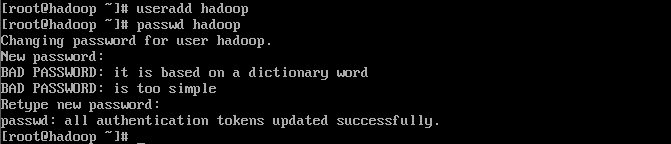
2.使用root帐户,创建hadoop用户,并将该帐户的密码设置为hadoop。
【注:创建hadoop用户是为了更好对服务的管理分配,不建议把应用使用root用户搭建】
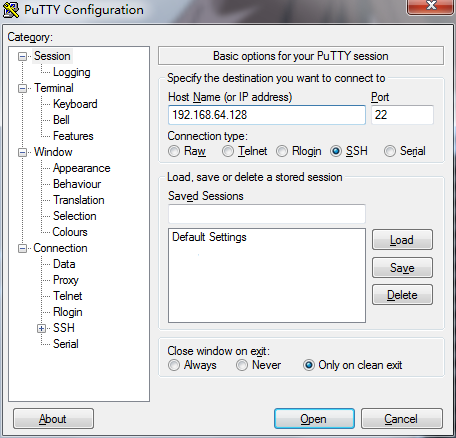
3.配置putty界面:Host Name(or IP address):192.168.64.128
Port:22
Connection type:SSH
4.同意接受服务器密钥的验证。

5.将在VMware Player中创建的hadoop用户及密码通过Putty工具登录系统。
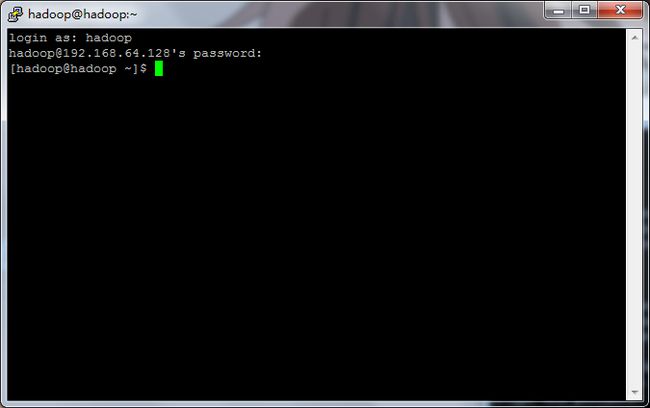
6.使用su root命令进入root用户,这样我们就有了对该系统最大的操作权限。

-
关闭防火墙与SELINUX
1.关闭防火墙服务。
[root@hadoop]#service iptables stop

2.开机自动关闭防火墙
[root@hadoop]#chkconfig iptables off
3.将SELINUX关闭
编辑vi /etc/selinux/config;修改SELINUX=disabled(默认值SELINUX=enforcing),并输入:wq,保存配置文件。
[root@hadoop]#vi /etc/selinux/config
SELINUX=disabled

-
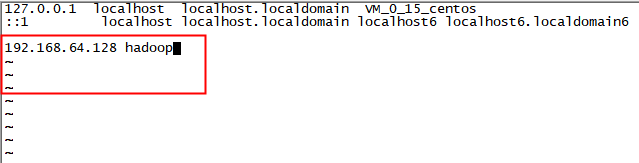
设置主机的hosts
[root@hadoop]#vi /etc/hosts
192.168.64.128 hadoop
-
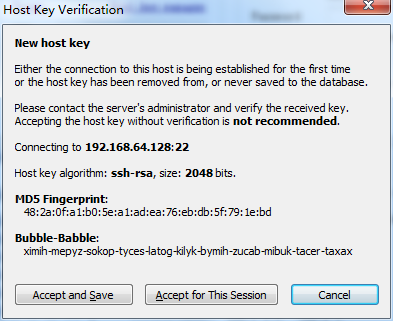
使用Bitvise SSH Client 4.5,将JAVA文件与Hadoop文件上传到Hadoop用户主目录下。
1.填写Host:192.168.64.128
Port:22
Username:hadoop
Password:hadoop

2.同意接受服务器密钥的验证。
3.选择New SFTP window。
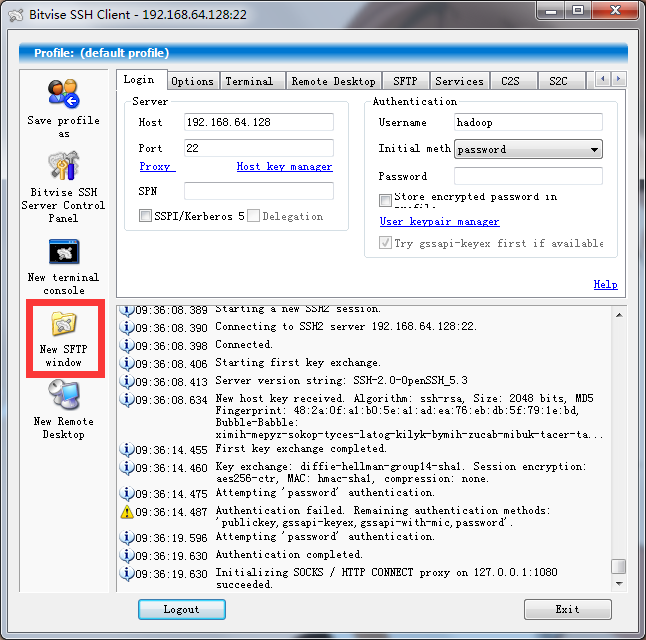
4.将左边的本地文件上传到右边的Centos的hadoop主目录下。
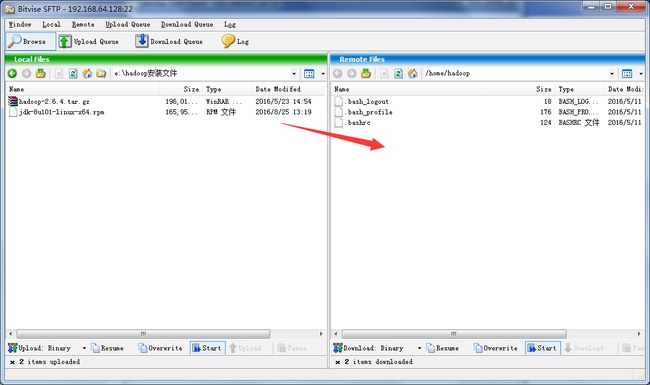
5.正在上传。

6.上传完成后,在hadoop用户下输入ll,查看文件的完整性。

-
进行SSH无密码验证配置
1.由于安装的是基本包,所以:ssh和rsync已经安装了。
[hadoop@hadoop ~]rpm –qa | grep openssh

[hadoop@hadoop ~]rpm –qa | grep rsync

2.输入ssh-keygen –t rsa –P ''生成无密码密码对。
[hadoop@hadoop ~]ssh-keygen –t rsa –P ''
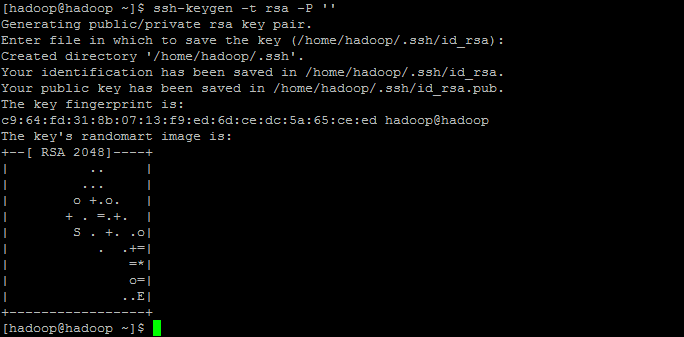
3.生成的密钥对:id_rsa和id_rsa.pub,默认存储在/home/hadoop/.ssh目录下。

4.使用cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys,把id_rsa.pub追加到授权的key里面去。
[hadoop@hadoop ~]cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys

-
验证前需要做两件事。
1.chmod 600 ~/.ssh/authorized_keys 修改文件authorized_keys权限
[hadoop@hadoop ~]chmod 600 ~/.ssh/authorized_keys
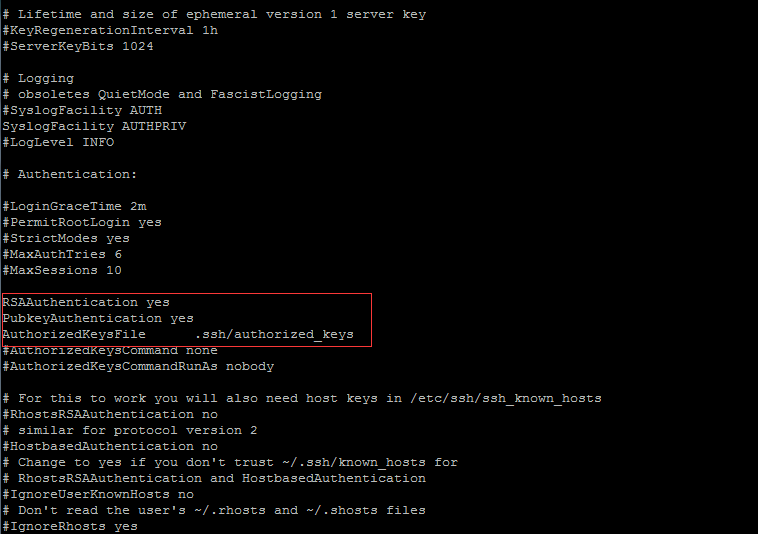
2.用root用户设置/etc/ssh/sshd_config的内容。使其无密码登录有效。用root用户登录服务器修改SSH配置文件/etc/ssh/sshd_config的下列内容。
[root@hadoop ~]vi /etc/ssh/sshd_config

RSAAuthentication yes
PubkeyAuthentication yes
AuthorizedKeysFile .ssh/authorized_keys
3.输入:serveice sshd restart,重启ssh服务。
[root@hadoop ~]serveice sshd restart

4.输入:ssh localhost,验证是否可以不用输入密码登录系统。
[root@hadoop ~]ssh localhost

-
Java安装
登录root用户,输入:yum remove java命令,先将系统自带的低版本JAVA删除。
[root@hadoop ~]yum remove java

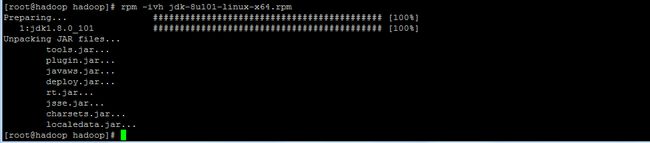
2.输入:rpm -ivh jdk-8u101-linux-x64.rpm,安装java 8u101版本。
[root@hadoop ~]rpm -ivh jdk-8u101-linux-x64.rpm
-
配置JAVA的环境变量
[hadoop@hadoop ~]vi /etc/profile
# set java environment
export JAVA_HOME=/usr/java/jdk1.8.0_101/
export CLASSPATH=.:$CLASSPATH:$JAVA_HOME/lib:$JAVA_HOME/jre/lib
export PATH=$PATH:$JAVA_HOME/bin:$JAVA_HOME/jre/bin
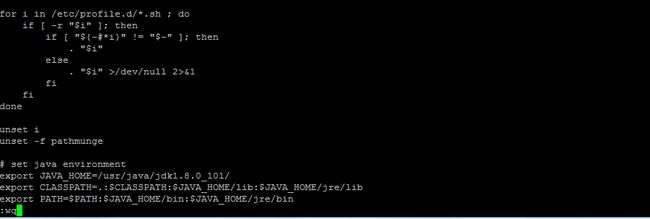
4.执行:source /etc/profile 使配置生效。
[hadoop@hadoop ~]source /etc/profile

使用java –version 查看java版本号:1.8.0_101。
输入:echo $JAVA_HOME出现JAVA路径。
[hadoop@hadoop ~]java –version
[hadoop@hadoop ~]echo $JAVA_HOME
说明配置成功。

-
hadoop安装
1.解压hadoop-2.7.3.tar.gz文件
[hadoop@hadoop ~]tar -zxvf hadoop-2.7.3.tar.gz
使用ll命令查看文件是否解压成功。
[hadoop@hadoop ~]ll
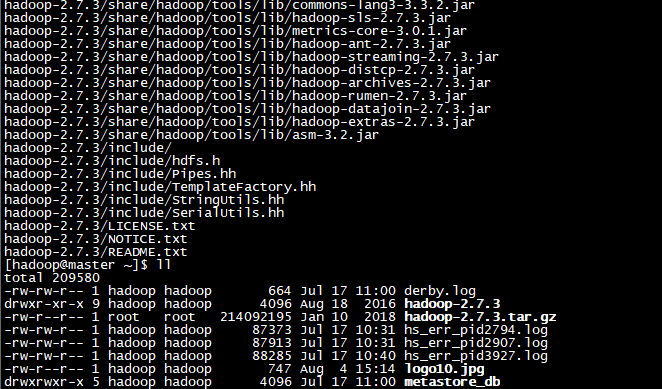
2.修改hadoop文件夹的位置与权限。
登录root用户。
[hadoop@hadoop ~]mv hadoop-2.7.3 hadoop
[hadoop@hadoop ~]mv hadoop /usr/local
[hadoop@hadoop ~]cd /usr/local
[hadoop@hadoop ~]chown –R hadoop:hadoop hadoop
mv hadoop-2.7.3 hadoop #将"hadoop-2.7.3"文件夹重命名"hadoop"
mv hadoop /usr/local #将hadoop文件夹移动到/usr/local
cd /usr/local #进入"/usr/local"目录
chown –R hadoop:hadoop hadoop #将文件夹"hadoop"读权限分配给hadoop用户
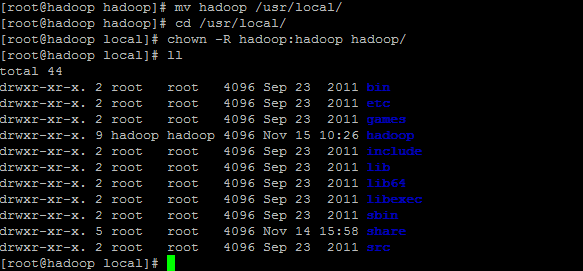
退出root用户
进入hadoop的配置文件:
[hadoop@hadoop ~]cd /usr/local/hadoop/etc/hadoop
3.配置环境变量
[hadoop@hadoop ~]#vi ~/.bashrc
# set hadoop environment
export HADOOP_HOME=/usr/local/hadoop
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
[hadoop@hadoop]#source ~/.bashrc
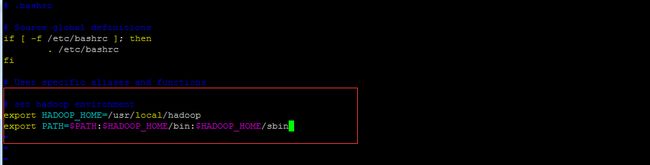
4.Hadoop配置主要有7个文件:
core-site.xml
hadoop-env.sh
hdfs-site.xml
mapred-site.xml.template
slaves
yarn-env.sh
yarn-site.xml
-
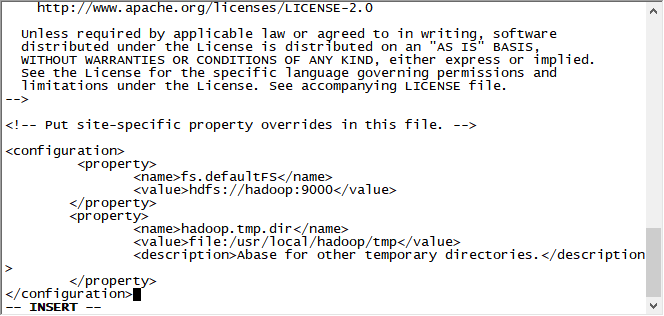
core-site.xml 文件
[hadoop@hadoop ~]vi core-site.xml
--fs.defaultFS:描述集群中NameNode结点的URI(包括协议、主机名称、端口号)。
--hadoop.tmp.dir:是hadoop文件系统依赖的基础配置,很多路径都依赖它。
-
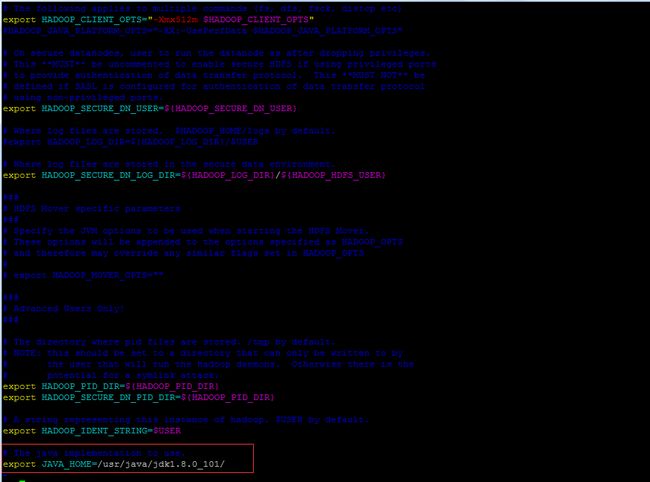
hadoop-env.sh
[hadoop@hadoop ~]vi hadoop-env.sh
# The java implementation to use.
export JAVA_HOME=/usr/java/jdk1.8.0_101/
-
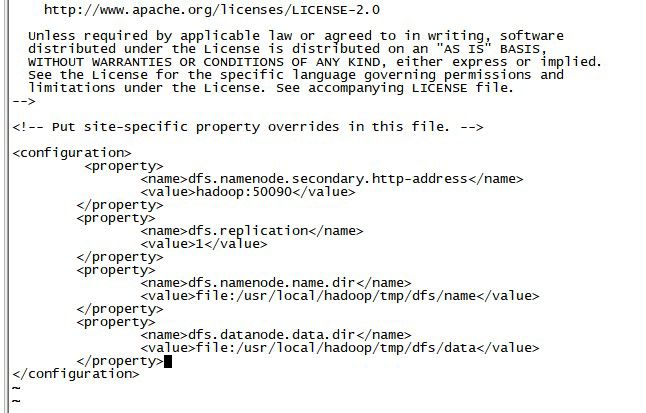
hdfs-site.xml
dfs.namenode.secondary.http-address:定义HDFS对应的HTTP服务器地址和端口。
dfs.replication:它决定着系统里面的文件块的数据备份个数。对于一个实际的应用,它应该被设为3(这个数字并没有上限,但更多的备份可能并没有作用,而且会占用更多的空间)。少于三个的备份,可能会影响到数据的可靠性(系统故障时,也许会造成数据丢失)。
dfs.namenode.name.dir:这是NameNode结点存储hadoop文件系统信息的本地系统路径。这个值只对NameNode有效,DataNode并不需要使用到它。上面对于/temp类型的警告,同样也适用于这里。在实际应用中,它最好被覆盖掉。
dfs.datanode.data.dir:这是DataNode结点被指定要存储数据的本地文件系统路径。DataNode结点上的这个路径没有必要完全相同,因为每台机器的环境很可能是不一样的。但如果每台机器上的这个路径都是统一配置的话,会使工作变得简单一些。默认的情况下,它的值hadoop.tmp.dir,这个路径只能用于测试的目的,因为,它很可能会丢失掉一些数据。所以,这个值最好还是被覆盖。
-
mapred-site.xml.template
[hadoop@hadoop ~]mv mapred-site.xml.template mapred-site.xml
[hadoop@hadoop ~]vi mapred-site.xml
mapreduce.framework.name 取值local、classic或yarn其中之一,如果不是yarn,则不会使用YARN集群来实现资源的分配。
mapreduce.jobhistory.address定义历史服务器的地址和端口,通过历史服务器查看已经运行完的Mapreduce作业记录。
mapreduce.jobhistory.webapp.address定义历史服务器web应用访问的地址和端口。

-
slaves
[hadoop@hadoop ~]vi slaves
hadoop

-
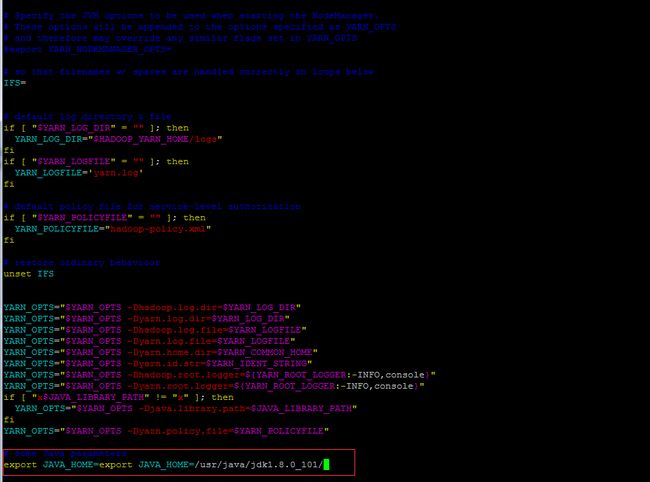
yarn-env.sh
[hadoop@hadoop ~]vi yarn-env.sh
# some Java parameters
export JAVA_HOME=export JAVA_HOME=/usr/java/jdk1.8.0_101/
-
yarn-site.xml
[hadoop@hadoop ~]vi yarn-site.xml
yarn.resourcemanager.hostname:开启一系列yarn应用端口的主机名。
yarn.nodemanager.aux-services:NodeManager上运行的附属服务。需配置成mapreduce_shuffle,才可运行MapReduce程序。
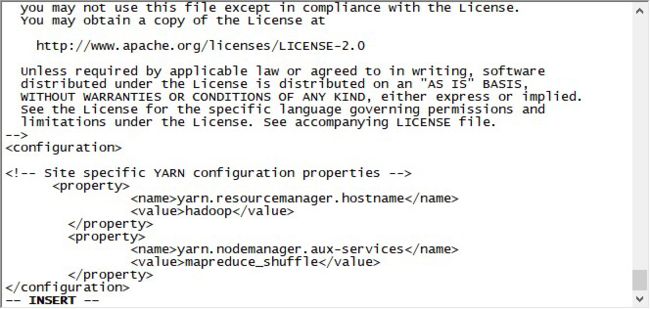
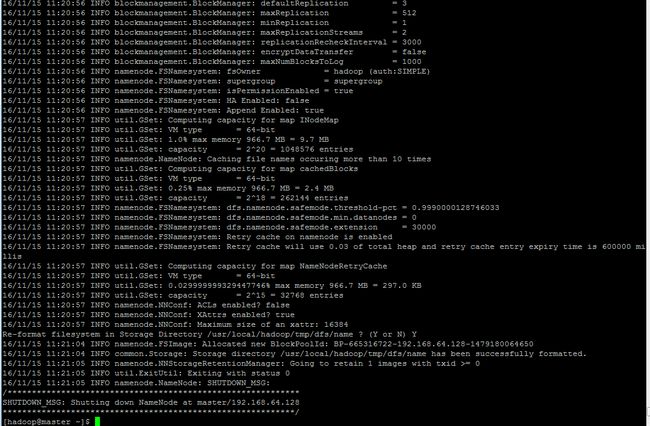
5.上述全部配置完成后,进行初始化
输入命令:hadoop namenode –format进行初始化
[hadoop@hadoop ~]hadoop namenode –format
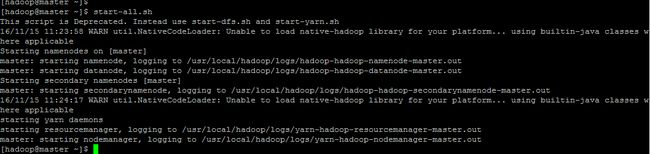
输入:start-all.sh,开启hadoop集群。
[hadoop@hadoop ~]
输入:jps,查看正在运行的服务。
[hadoop@hadoop ~]jps

6.Windows电脑中Chrome网页输入: http://192.168.64.128:50070查看hadoop(hdfs)的概括。
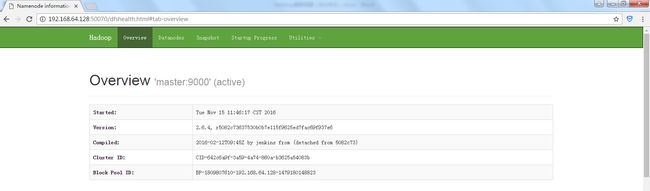

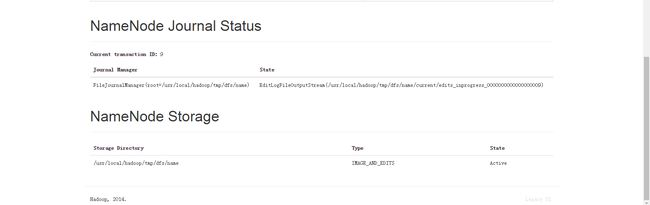
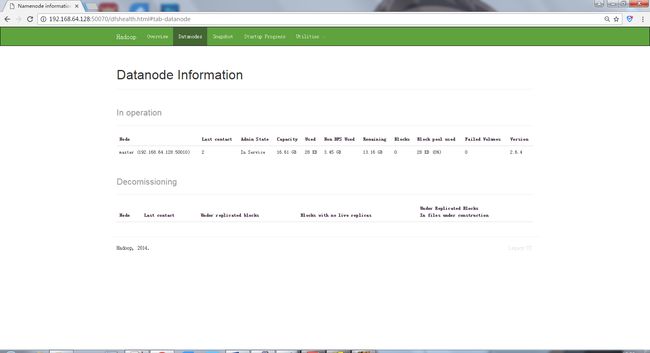
输入: http://192.168.64.128:50075查看datanode节点的概括。
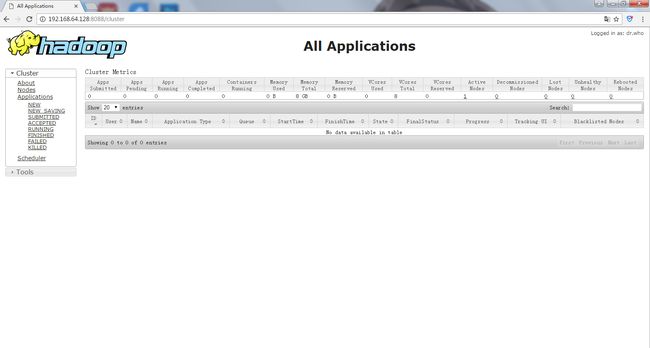
输入: http://192.168.64.128:8088查看MapReduce的运行任务计划。
4.Hadoop的基础操作说明(以文字为准)
※注:默认已经配置好hadoop并且已正常开启。
-
运行demo
1.检查状态
[hadoop@hadoop ~]jps
[hadoop@hadoop ~]hdfs dfsadmin -report

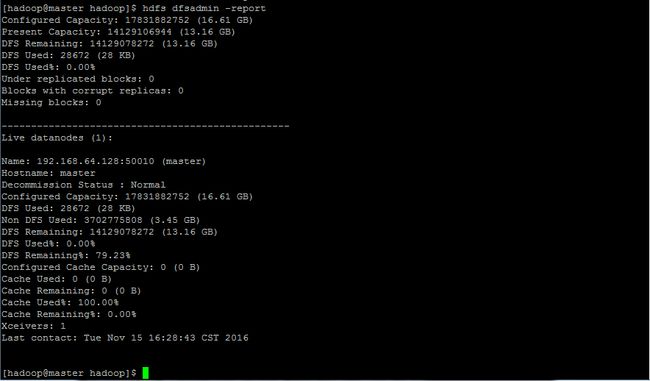
2.执行MapReduce任务
在HDFS创建一个目录,并把一些文件输入,并列出文件:
[hadoop@hadoop ~]#hdfs dfs -mkdir –p /user/hadoop
[hadoop@hadoop ~]#hdfs dfs -mkdir –p /user/hadoop/input
[hadoop@hadoop ~]#hdfs dfs -put /usr/local/hadoop/etc/hadoop/hadoop-env.sh /user/hadoop/input
[hadoop@hadoop ~]#hdfs dfs -ls /user/hadoop/input

运行WordCount:
[hadoop@hadoop ~]#hadoop jar /usr/local/hadoop/share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.3.jar wordcount input output
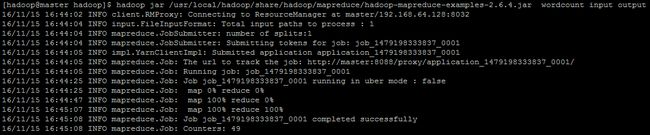


检查 output文件夹:
[hadoop@hadoop ~]#hdfs dfs -cat output/*
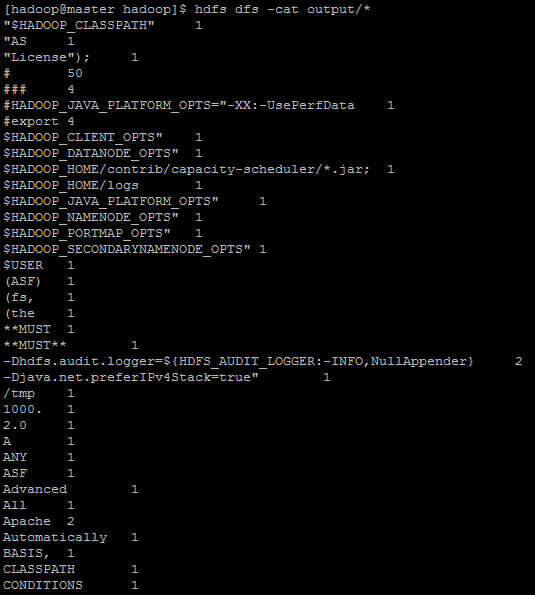
由于结果太多,不一一列举。
删除output文件夹
[hadoop@hadoop ~]#hdfs dfs -rm -f -r output