hadoop 2.x 集群搭建
集群简介
HADOOP集群具体来说包含两个集群:HDFS集群和YARN集群,两者逻辑上分离,但物理上常在一起
HDFS集群:
负责海量数据的存储,集群中的角色主要有NameNode / DataNode(还有SecondaryNameNode)
YARN集群:
负责海量数据运算时的资源调度,集群中的角色主要有 ResourceManager /NodeManager
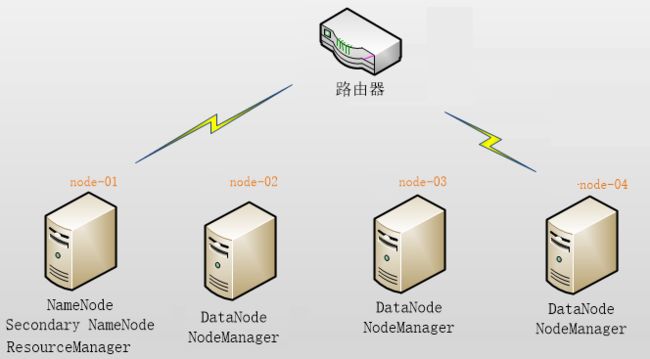
使用4个节点打架,角色分配如下:
| node1 | NameNode 、SecondaryNameNode、ResourceManager |
| node2 | DataNode、NodeManager |
| node3 | DataNode、NodeManager |
| node4 | DataNode、NodeManager |
服务器准备
使用虚拟机服务器来搭建HADOOP集群,所用软件及版本:
Vmware 11.0
Centos 6.7 64bit
网络环境准备
采用NAT方式联网
网关地址:192.168.66.2
4个服务器节点IP地址:192.168.66.3、192.168.66.4、192.168.66.5、192.168.66.6
子网掩码:255.255.255.0
服务器系统设置
添加HADOOP用户
为HADOOP用户分配sudoer权限
同步时间
设置主机名
node-01
node-02
node-03
node-04
配置内网域名映射:
192.168.66.3 node-01
192.168.66.4 node-02
192.168.66.5 node-03
192.168.66.6 node-04
配置ssh免密登陆
配置防火墙(关闭防火墙 serviceiptables stop 开启不自动启动防火墙chkconfig iptables off)
HADOOP安装部署
上传HADOOP安装包
规划安装目录 /home/hadoop/apps/hadoop-2.6.4
解压安装包
修改配置文件 $HADOOP_HOME/etc/hadoop/
最简化配置如下:
(需要将JAVA_HOME 改为安装路径,不使用$JAVA_HOME获取)
Ø vi hadoop-env.sh (因为是远程启动,所以系统配置变量不可见)
| # The java implementation to use. export JAVA_HOME=/home/hadoop/apps/jdk1.7.0_51 |
以下的配置可以都配置在任意一个文件中,但是为了方便管理所以分开配置最好。
Ø vi core-site.xml (核心配置也可作为公共的配置)
| |
Ø vi hdfs-site.xml
|
|
Ø vi mapred-site.xml
| |
Ø vi yarn-site.xml
| |
配置hadoop的环境变量
sudo vi +/etc/profile
export HADOOP_HOME=/home/hadoop/apps/hadoop-2.6.4
export PATH=$JAVA_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$PATH
然后source /etc/profile
这样就可以在任何地方使用hadoop的命令了
格式化namenode目录
hadoop namenode –format
如果出现如下信息表示格式化成功。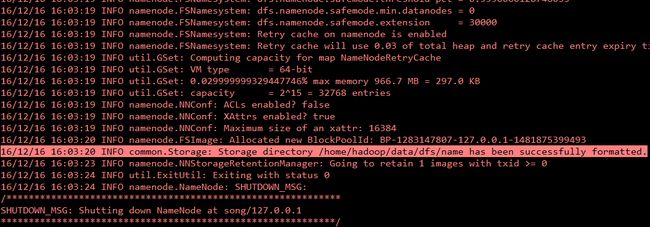
如果格式化出现如下错误,说明hosts里面的localhost 在/etc/sysconfig/network中找不到,说明主机名更改了,但没有修改hosts文件,所有找不到本机ip对应的localhost
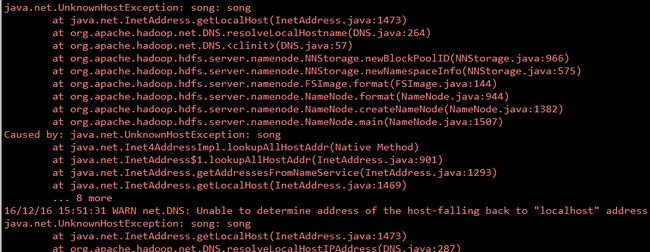
解决办法:
修改host中ip和主机名的映射关系
sudo vi/etc/hosts
127.0.0.1 song
启动集群:
分别启动的方式:
使用hadoop-daemon.shstart namenode 启动namenode
使用jps 查看是否启动成功,如果出现如下信息说明安装成功
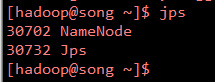
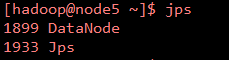
使用hadoop-daemon.shstart datanode 启动datanode
使用jps 查看是否启动成功,如果出现如下信息说明安装成功
集群很大机器很多,不可能一台一台的去敲命令来启动,所以使用该脚本启动
使用该脚本首先要配置该机器和集群中其他机器的免密登录
为什么要设置免密登录,因为脚本帮我们启动机器的原理就是:ssh 到其他机器上执行启动命令,这时候我们启动的时候要输入其他机器的密码才能ssh到这台机器上,所以当集群很大的时候,很不方便,所以需要免密登录,来直接启动,而不需要在启动的时候输入密码。
进入hadoop的配置文件的路径
cd /home/hadoop/apps/hadoop-2.6.4/etc/hadoop
编辑slaves 文件里面配置datanode
在里面加入datanode的ip或者主机名,多个ip以换行分隔
vi slaves
node2
node3
node4
然后在nanmenode主机上start-dfs.sh 启动HDFS集群 stop-dfs.sh 停止HDFS集群
再使用start-yarn.sh 启动yarn集群 stop-yarn.sh 停止yarn集群
上面的脚步可以在任意的机器上执行,前提是配置了该机器和其他机器的免密登录,不然需要输密码
还可以使用start-all.sh 启动hdfs和yarn 集群(This script isDeprecated. Instead use start-dfs.sh and start-yarn.sh 此脚本已弃用。而是使用start-dfs.sh和start-yarn.sh)
官方建议使用start-dfs.sh+ start-yarn.sh 来启动,