HDFS相关面试问题整理
1. HDFS的写流程
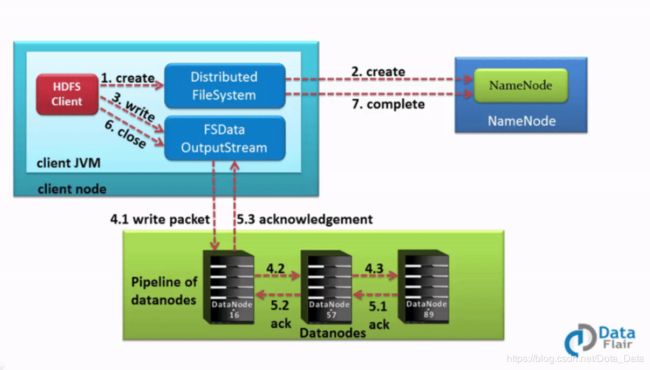
a) hdfs客户端向namenode发送rpc请求.
b) namenode检查文件是否已经存在, 创建者是否有权进行操作, 成功则会为文件创建记录, 反之客户端抛出异常.
c) 客户端将文件切分成多个packets, 并在内部以数据队列形式管理packets. 然后客户端向namenode申请blocks, 通过选择合适的datanode列表来存放副本.
d) 以pipeline的形式将packet写入所有副本中. DataStreamer以流的形式将packet写入第一个datanode, 然后以此类推写至最后一个.
e) 当datanode接收完成, 会给DFSOutputstream一个确认消息, 而DFSOutputStream中有一个确认队列, 一旦收到确认信息, 就会将相应的包从确认队列中删除, 并为其创建副本.
f) 客户端完成数据写入后, 调用流的close()方法, 关闭数据流.
延申—如果传输过程中datanode出现故障怎么办?
如果有某个datanode故障, 当前管道会关闭, 故障的datanode会被从当前管道移除,剩余的block会继续以管道形式传输, 同时namenode会分配一个新的datanode, 保持replicas维持设定的数量.
2. datanode什么情况下不会备份?
设置备份数为1时, 就不会备份了.
延申—Hadoop中在哪里设置备份数, 是哪个字段?
在hdfs-site.xml中的dfs.replication变量.
3. HDFS中大量小文件带来的问题以及解决方法
问题:
hadoop中目录,文件和块都会以对象的形式保存在namenode的内存中, 大概每个对象会占用150bytes. 小文件数量多会大量占用namenode的内存; 使namenode读取元数据速度变慢, 启动时间延长; 还因为占用内存过大, 导致gc时间增加等.
解决办法:
两个角度, 一是从根源解决小文件的产生, 二是解决不了就选择合并.
- 从数据来源入手, 如每小时抽取一次改为每天抽取一次等方法来积累数据量.
- 如果小文件无可避免, 一般就采用合并的方式解决. 可以写一个MR任务读取某个目录下的所有小文件, 并重写为一个大文件.
4. 介绍一下RPC通信的逻辑实现

如上图中,Proxy和Impl是对同一个RPC调用接口的实现类,当Proxy中的接口被调用时,通过Client发送消息到 Server ,Server 会按照标准数据格式进行解析,再调用Server侧的 Impl方法进行执行,并返回结果数据。
5. HDFS的三个核心组件是什么, 有什么作用?
- NameNode. 集群的核心, 是整个文件系统的管理节点. 维护着
a) 文件系统的文件目录结构和元数据信息
b) 文件与数据块列表的对应关系 - DataNode. 存放具体数据块的节点, 主要负责数据的读写, 定期向NameNode发送心跳
- SecondaryNameNode. 辅助节点, 同步NameNode中的元数据信息, 辅助NameNode对fsimage和editsLog进行合并.
6. fsimage和editlogs是做什么用的?
fsimage文件存储的是Hadoop的元数据文件, 如果namenode发生故障, 最近的fsimage文件会被载入到内存中, 用来重构元数据的最近状态, 再从相关点开始向前执行edit logs文件中记录的每个事务.
文件系统客户端执行写操作时, 这些事务会首先记录到日志文件中.
在namenode运行期间, 客户端对hdfs的写操作都保存到edit文件中, 久而久之就会造成edit文件变得很大, 这对namenode的运行没有影响, 但是如果namenode重启, 它会将fsimage中的内容映射到内存中, 然后再一条一条执行edit文件中的操作, 所以日志文件太大会导致重启速度很慢. 所以在namenode运行的时候就要将edit logs和fsimage定期合并.
7. Linux中的块大小为4KB, 为什么HDFS中块大小为64MB或128MB?
块是存储在文件系统中的数据的最小单元. 如果采用4kb的块大小来存放存储在Hadoop中的数据, 就会需要大量的块, 大大增加了寻找块的时间, 降低了读写效率.
并且, 一个map或者一个reduce都是以一个块为单位处理, 如果块很小, mapreduce任务数就会很多, 任务之间的切换开销变大, 效率降低.
8. 并发写入HDFS文件可行吗?
不行, 因为客户端通过namenode接收到在数据块上写入的许可后, 那个块会锁定直到写入操作完成, 所以不能在同一个块上写入.