从前面的介绍Url编码文章中,我们了解了浏览器发起请求的字符处理过程。现在开始介绍tomcat服务器接收处理请求的过程。
httpClient模拟浏览器
在说tomcat服务器如何接收处理请求之前,我想先尝试用httpClient工具来模拟浏览器发起请求的处理过程。其实这样可以更加深刻理解浏览器。
演示:
1) 如果没有url编码就发送出去,那么服务器无法识别,于是报错。
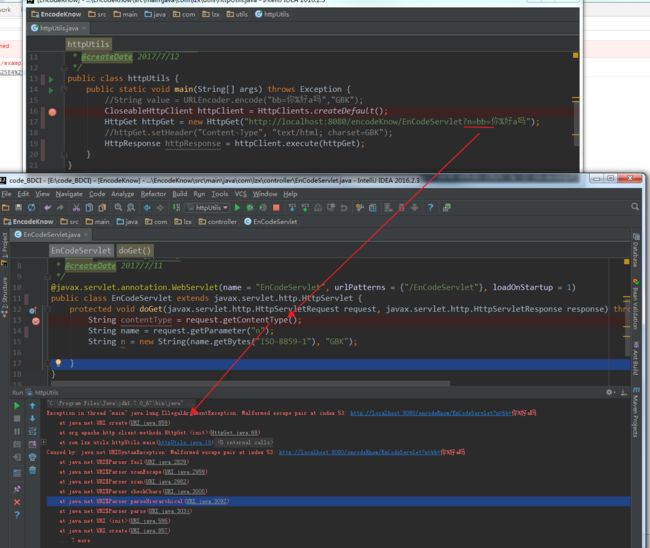
2) 如果先将请求中的参数值(value)进行Urlencode后,这其实在模拟浏览器Get请求,服务器就正常识别了:
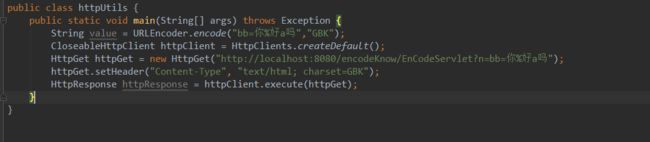
POST请求类似,不多演示。
tomcat处理请求值过程
Get和Post过来的键值对,在我们调用request.getParameter("key")时,tomcat会对value进行转码。
我们知道键值对是经过Url编码的,这是client和server之间的行业约定。因此tomcat的处理也是会遵循此约定来处理。然而,Get和Post过来的数据,tomcat虽然在value值编码过程一样,可是编码的根据却是不同点的。
Get请求:主要看tomcat的server.xml文件中的两个参数配置:
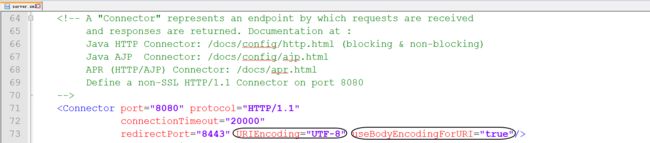
URIEncoding :意思是,传递过来的value是UTF-8格式化得到的,因此tomcat会将utf-8字节转化成unicode,进而转化为Utf-16内码。
useBodyEncodingForURI: 在默认情况下,该参数为false。单词中文意思大概是“按照request body字符的格式对待uri”。我们知道,常规情况下,get请求是没有request body的。可是我们不排除Post请求中URI也是带有键值对的,当这种少数情况出现,tomcat就会根据request body 中的格式对待Uri键值对了。其实它的意思应该是按照request请求头中contentType指定的格式来对待uri键值对。一般情况下Request中我们都不会特地设置contentType,因为我们本来已经知道客户端发送过来的内容会是什么格式的(因为前一个Response头中我们已经指定了)。如果没有contentType指定,则tomcat会默认 value是 ISO8859-1格式的。
不过,这里有个细节:URIEncoding 其实是受 useBodyEncodingForURI 牵制的。当useBodyEncodingForURI = true ,则URIEncoding无效、tomcat只会根据Request头中的ContentType对待键值对。当=false,tomcat则只能根据URIEncoding来对待键值对。
例如:如果URIEncoding="gbk" useBodyEncodingForURI="true"都设置了,那么URIEncoding="gbk"不起作用。
如果我们没有显式指定URIEncoding 和 useBodyEncodingForURI,那么tomcat默认键值对中的value是ISO8859-1格式的。
POST请求:tomcat只会根据request.setCharacterEncoding("CharsetName") 对待请求体(注意这里仅仅是针对请求体,而不是针对Post请求中的URI键值对)。即,tomcat会认为请求体字节是客户端根据“CharsetName”格式化得来的,那么tomcat就会这样转码:CharsetName --> Unicode -->Utf-16内码。
tomcat并不会根据request.setCharacterEncoding("CharsetName")处理Get请求,也不会根据URIEncode和useBodyEncodingForURI处理Post请求中的请求体。
tips1:上面说的结论,大家可以自己逐一测试,在此就不演示了。
综上,tomcat对待Get、Post请求的处理是很分明的。既然那么分明,那么我们也得分明地设置好。一般地,我们会在Filter中request.setCharacterEncoding("CharsetName") 来独立对待Post请求。
tips2:
其实上述的结论,我们可以直接从tomcat源码中看出:org.apache.catalina.connector.Request#parseParameters()
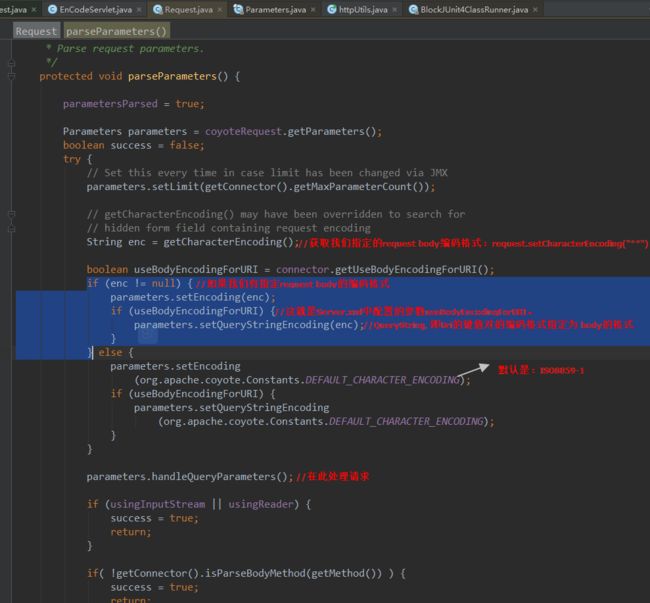
注意:转码失败容易丢失字节
假设客户端通过sender=URLEncoder.encode("中文","GBK")对参数进行编码 再GET提交过来。如果server.xml中设置URIEncoding="utf-8", 没有设置useBodyEncodingForURI="true" , 那么,会使用utf-8对16进制的参数进行解码,这时候 request.getParameter()获得乱码的中文参数值,并且通过new String(sender.getBytes(" utf-8 "), "gbk")也会乱码,可能丢失字节;原因我猜测如下:
按照GBK字符编码,"中文" 是 四个字节的:"D6D0CEC4"。当tomcat接收到数据后,以 utf-8来接收并解码,会出现无法解析,
由上,我们在规划转码配置时要谨慎。
响应指定编码
响应体中指定编码其实非常好理解。JVM中字符内码是UTF-16,当需要输出给client时,我们会提前设置:response.setCharacterEncoding("CharsetName"),tomcat输出前会将字符这样转码:Utf-16内码--> Unicode -->"CharsetName",并且tomcat底层会帮我们设置响应头ContentType指定编码为CharsetName。如此client就知道如何解析这字节流了。