初识webmagic之爬取CSDN博客
WebMagic的结构分为Downloader、PageProcessor、Scheduler、Pipeline四大组件,并由Spider将它们彼此组织起来。这四大组件对应爬虫生命周期中的下载、处理、管理和持久化等功能。在这四个组件中我们需要做的就是在PageProcessor中写自己的业务逻辑,比如如何解析当前页面,抽取有用信息,以及发现新的链接。
下面是官方给出的架构图
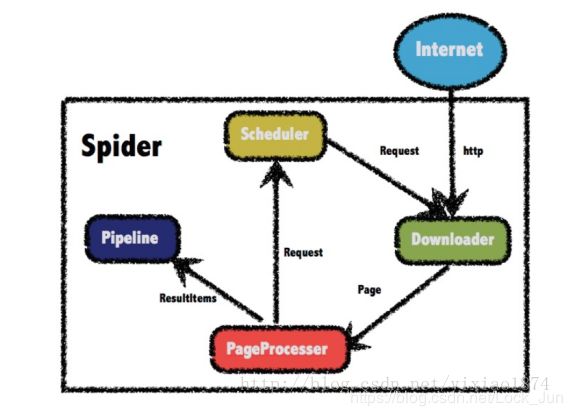
WebMagic的四个组件
1.Downloader
Downloader负责从互联网上下载页面,以便后续处理。WebMagic默认使用了Apache HttpClient作为下载工具。
2.PageProcessor
PageProcessor负责解析页面,抽取有用信息,以及发现新的链接。WebMagic使用Jsoup作为HTML解析工具,并基于其开发了解析XPath的工具Xsoup。
在这四个组件中,PageProcessor对于每个站点每个页面都不一样,是需要使用者定制的部分。
3.Scheduler
Scheduler负责管理待抓取的URL,以及一些去重的工作。WebMagic默认提供了JDK的内存队列来管理URL,并用集合来进行去重。也支持使用Redis进行分布式管理。
除非项目有一些特殊的分布式需求,否则无需自己定制Scheduler。
4.Pipeline
Pipeline负责抽取结果的处理,包括计算、持久化到文件、数据库等。WebMagic默认提供了“输出到控制台”和“保存到文件”两种结果处理方案。
Pipeline定义了结果保存的方式,如果你要保存到指定数据库,则需要编写对应的Pipeline。对于一类需求一般只需编写一个Pipeline。
用于数据流转的对象
- Request
Request是对URL地址的一层封装,一个Request对应一个URL地址。
它是PageProcessor与Downloader交互的载体,也是PageProcessor控制Downloader唯一方式。
除了URL本身外,它还包含一个Key-Value结构的字段extra。你可以在extra中保存一些特殊的属性,然后在其他地方读取,以完成不同的功能。例如附加上一个页面的一些信息等。 - Page
Page代表了从Downloader下载到的一个页面——可能是HTML,也可能是JSON或者其他文本格式的内容。
Page是WebMagic抽取过程的核心对象,它提供一些方法可供抽取、结果保存等。在第四章的例子中,我们会详细介绍它的使用。 - ResultItems
ResultItems相当于一个Map,它保存PageProcessor处理的结果,供Pipeline使用。它的API与Map很类似,值得注意的是它有一个字段skip,若设置为true,则不应被Pipeline处理。
例子:-----------------------------------
webmagic来爬取CSDN上本人博客的文章信息
下面我们通过一个简单的例子来观察webmagic的使用方法以及执行流程。需求:输入作者的用户名,得到该作者文章总数(最简单的办法是直接从首页拿到,我们是爬到一篇文章记录一次),得到所有文章信息(文章名称,发布日期,阅读量,评论数…)
首先加入webmagic依赖,
us.codecraft
webmagic-core
0.7.3
us.codecraft
webmagic-extension
0.7.3
然后写一个Processor就搞定了:修改不同的username可以爬取不同的作者。
public class MyPageProcessor implements PageProcessor {
private static String username = "Lock_Jun";// 设置csdn用户名
private static int size = 0;// 共抓取到的文章数量
// 抓取网站的相关配置,包括:编码、抓取间隔、重试次数等
private Site site = Site.me().setRetryTimes(3).setSleepTime(1000);
public void process(Page page) {
if (!page.getUrl().regex("https://blog.csdn.net/" + username + "/article/details/\\d+").match()) {
//获取当前页码
String number=page.getHtml().regex("currentPage\\s*=\\s*(\\d*)",1).toString();
//String number = page.getHtml().xpath("//li[@class='page-item active']//a[@class='page-link']/text()").toString();
//匹配当前页码+1的页码也就是下一页,加入爬取列表中
String pageSize =page.getHtml().regex("pageSize\\s*=\\s*(\\d*)",1).toString();//每页文章数
String listTotal =page.getHtml().regex("listTotal\\s*=\\s*(\\d*)",1).toString();//用户拥有文章数
double maxPage=Math.ceil(Double.parseDouble(listTotal)/Double.parseDouble(pageSize));
if(maxPage>Double.parseDouble(number)) {
//将下一页访问路径放入爬取队列
page.addTargetRequest("http://blog.csdn.net/"+username+"/article/list/"+(Integer.parseInt(number)+1));
}
List detailUrls = page.getHtml().xpath("//h4//a/@href").all();
for(String list :detailUrls){
System.out.println(list);
}
page.addTargetRequests(detailUrls);
}else {
size++;// 文章数量加1
String path = page.getUrl().get();
int id = Integer.parseInt(path.substring(path.lastIndexOf("/")+1));
String title = page.getHtml().xpath("//h1[@class='title-article']/text()").get();
String date = page.getHtml().xpath("//div[@class='article-bar-top']//span[@class='time']/text()").get();
String copyright = page.getHtml().xpath("//div[@class='article-title-box']//span[@class='article-type type-1 float-left']/text()").get();
int view = Integer.parseInt(page.getHtml().xpath("//div[@class='article-bar-top']//span[@class='read-count']/text()").get().substring(4));
CsdnBlog csdnBlog = new CsdnBlog(id, date, title, "", view, null, copyright);
System.out.println(csdnBlog);
}
}
public Site getSite() {
return site;
}
public static void main(String[] args) {
// 从用户博客首页开始抓,开启5个线程,启动爬虫
Spider.create(new MyPageProcessor())
.addUrl("https://blog.csdn.net/" + username)
.thread(5).run();
System.out.println("文章总数为"+size);
}
}
自定义的实体类,用来保存爬取的数据,至于之后对数据的保存就随你自己的需求了。
public class CsdnBlog {
private Integer id;// 编号
private String title;// 标题
private String date;// 日期
private String category;// 分类
private Integer view;// 阅读人数
private Integer comments;// 评论人数
private String copyright;// 是否原创
public CsdnBlog() {}
public CsdnBlog(Integer id,String date,String title,String category,Integer view,Integer comments,String copyright){
this.id = id;
this.date = date;
this.view = view;
this.category = category;
this.title = title;
this.comments = comments;
this.copyright = copyright;
}
@Override
public String toString() {
return "CsdnBlog{" +
"id=" + id +
", title='" + title + '\'' +
", date='" + date + '\'' +
", category='" + category + '\'' +
", view=" + view +
", comments=" + comments +
", copyright='" + copyright + '\'' +
'}';
}
}
备注:在匹配获取页面信息那个地方(number附近),注意查看网页的document结构是否有变化,对应网页改变即可。
参考链接:https://blog.csdn.net/yixiao1874/article/details/79496825