新浪微博丰富化应用下的技术选型之路
本文根据师婷婷在2018年5月12日【第九届中国数据库技术大会】现场演讲内容整理而成。
讲师简介:

师婷婷,新浪微博研发中心高级DBA,曾负责微博支付、微博红包平台主业务,目前是微博核心用户关系服务业务线负责人,同时负责新浪微博数据系统服务平台NoSQL和MySQL运维和平台自动化开发工作,多次亲身参与春晚值班,经历明星出轨等热点事件。
文章摘要:
随着微博业务形态的丰富化,对于后端数据的使用和存储模式也越来越特殊化,比如微博story、二度关系、通讯录等新型业务的上线,需要更高吞吐量、更大的内存、磁盘需求,如果仅仅用传统的队列缓存以及存储势必会带来成本的巨幅提升。在这种背景下,如何才能在节约成本的前提下,不仅选择到合适的组件,而且还能够带来更好的性能提升?微博做了很多尝试,本文将和大家一起来分享微博数据库团队在新组件pika和myrocks以及自主研发的counterservice ssd 的线上运维实战经验。
正文演讲:
大家好,我来自新浪微博研发中心,目前主要负责三方面的工作,第一是负责微博比较核心的用户关系,例如新业务上线的架构选型、老业务的改造以及日常的运维工作;第二是平台的自动化建设;第三是和今天分享主题相关的技术选型,我们技术选型时除了自研,也会选择一些其它优秀的工具。
在技术选型时会有很多工作需要我们去做,例如前期背景调查、需求分析、后期上线的问题排查、推广工作等等。所以,今天的分享将围绕以下几个方面来讲,为什么要去选型,在选型过程中需要做哪些事情,以及如何确定是否选对了。
一.为什么要选型?
众所周知,微博为了提升用户好感度,推广了很多新兴业务,例如通讯录项目。这个项目是指在推荐用户时,我们不再是依照以前的兴趣爱好去推荐,而是去推荐通讯录中的注册用户,而这些用户都是每个人很感兴趣的。

第二是2017年比较流行的两种场景,短视频和答题。短视频化是微博story,用户可以随时随地的把自己的故事分享给大家;春节期间,我们和春晚展开了深层合作——春晚答题王,可以边看春晚边发微博。
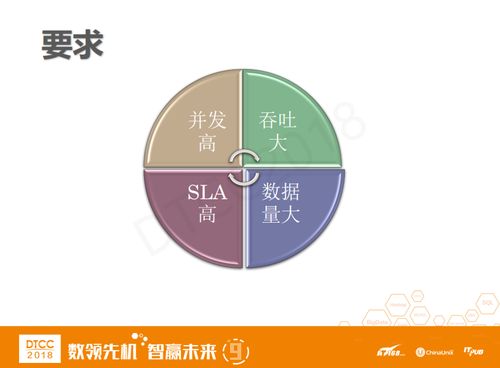
这么多新兴业务的产生势必对我们的要求也越来越高,例如我们的并发量可能到达百万、千万级别,存储数据是TB级,同时响应时间也会相应的要求更高。

我们原有的架构是缓存+DB的模式,缓存可能是用Redis或者Memcrched,DB就是MySQL。这种架构并不是不能满足新型业务,只是有点不太适合。例如,缓存选用Redis就有点问题,要满足业务这么大的访问量和存储量,内存使用的成本就会异常高。
总结一下,我们去做选型主要就是两个原因,一是我们的场景越来越丰富,单一组件已经不能满足需求;二是微博业务变化,量变引起质变,原有的架构需要调整。
二.怎么选型?
上文中提到的场景都是比较虚的大场景,可能不易于理解,下面我们讲一些具体案例。
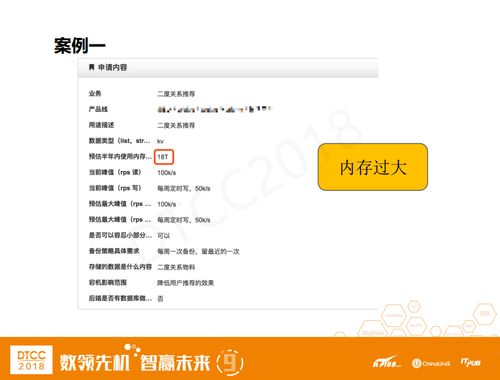
案例一是大家常见的Redis申请提案,这其中我们比较关心的有内存使用量、数据类型、读写QPS等等。值得注意的是,这个人要申请的Redis是18T。大家对18T有什么概念吗?一般来说,大家申请的大多是几十G,最大也就是几百G。Redis单个端口的数据量大概是十个G,如果按18T来计算的话,端口数量可能达到1000多个,单个机器可用内存大约100G,那么机器数量就需要180多台。
这样一看,问题就很明显了,你的内存太大了。

案例二,常玩微博的人都知道上图是用户维度和微博维度的基础计数,关注、粉丝、微博以及阅读数等。无论是用户数据还是微博数据都有一个很明显的特征——冷热分离。随着业务的增长,如果一直把数据存在内存中,肯定会带来非常大的成本压力,所以我们急需一个能够将访问次数较少的冷数据放到磁盘,热点数据放到内存的冷热分离计数类组件。

案例三,这就是刚才提到的通讯录项目。这个业务刚开始的时候,我们申请了15T左右数据的MySQL。如果我们单纯只使用MySQL,那么可能就要经历大量的分库分表和多个端口,而且要维护一个很庞大的MySQL集群。

理清了需求中这三个突出问题之后,接下来就是针对这些问题去选择新的组件。

案例一中的问题是内存过大,所以我的解决方法是尽量把数据存储在磁盘当中,并同时提供一定的响应时间。我们选择了Pika,为什么呢?当时我们参加了360 的Pika分享会,知道了Pika是360开源的,基于Redis,加载到磁盘上的速度非常快,刚好可以解决我们当时想要将数据存在磁盘上的问题。

案例二中的问题是冷热分离。2013年之前,微博是用Redis存储的,但是那时我们预测到随着用户量和微博量的增长,这肯定不能满足我们的需求,所以我们的研发团队自己开发了CounterserviceSSD。
CounterserviceSSD也是基于eRedis,支持多table,定长KV存储,用户可以将阅读量等数据存在table中,当到达某个值之后,数据就会存在磁盘里,这样就保证了这个table的数据是放在内存当中的。

案例三中的问题是数据量大、过度分库分表。最早接触到Myrocks的时候,我们觉得它比较适合于日志类的数据存储,但当时没有线上使用。直到通讯录业务出现,我们才想到要试试Myrocks,它主要是将RocksDB移植到MySQL当中,并且支持很高的压缩比。
试想一下,如果当15T数据全部用MySQL来存的话,那将是一个多么庞大的MySQL集群。而如果选用Myrocks,它的压缩比会给我们带来多大的收益。
需求触发选型,而选型之后我们就要进行压测。虽然不知道大家是如何做压测的,但我们做压测首先要做一个基础技术报告,然后进行性能调用、压缩,完成一份符合微博使用的压缩报告。
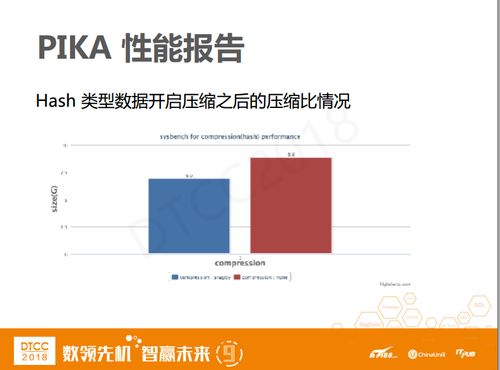
以Pika为例,我们先简单压测,配了性能之后进行压缩。例如针对哈希类型的数据,开启压缩前后的压缩比,后台需要开启多少压缩线程、对于QPS性能的影响有多大。在我们的场景下,Pika的适合机型是Centos7+PCIE,RT对外宣称是50毫秒,但其实实际业务支持在20毫秒以内,读写QPS大概是7万每秒。
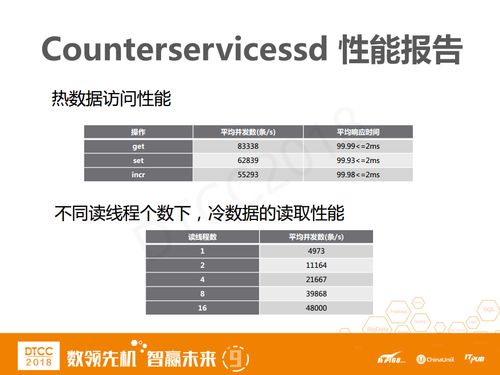
CounterserviceSSD是我们自研的一个数据冷热分离的技术方案,大家肯定会比较关心它的冷数据和热数据的访问性能。热数据,CounterserviceSSD基本可以对标Redis,在6万到8万左右,冷数据可以达到3到4万,响应时间基本在10毫秒以内。
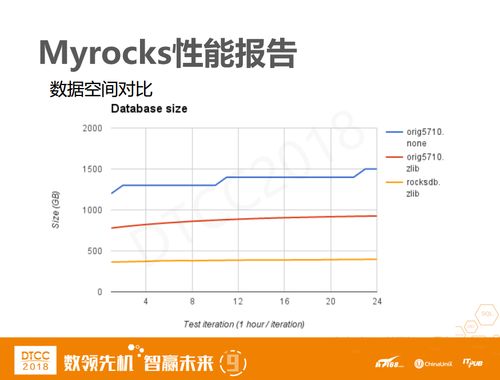
Myrocks比较关心它的压缩比,因为MySQL也有自己的压缩方法,所以我们会把Myrocks和MySQL开启压缩前后做一个对比,结果显示Myrocks基本上可以达到3:1的性能。因为开启压缩肯定会对读写性能有一定的影响,我们看到Myrocks的读写性能基本上维持在3万左右。需要注意的是,这里Myrocks是部署在CentOS 7+PCIE上,这样能够尽量获得一个较高的写入性能和较低的磁盘占用。
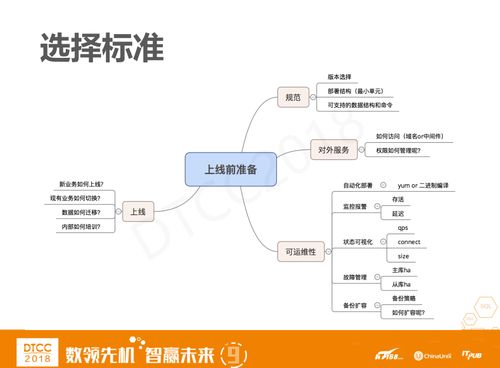
压测并不是简单的我关心哪个点,就针对这个点出一个简单的压测报告。而且一款软件是否能够上线也不一个压测报告就可以决定的,压测报告出来了之后,我们还有很多上线前的准备需要做,例如对外的部署规范,对外提供服务的方式,域名还是VIP,上线之后的高可用、数据备份、监控报警等等,上线过程中,新业务如何去上线,一套软件上线肯定不是只适合某个业务,同时也要适配之前的老业务,那么老业务如何适配呢……只有这些问题都有了答案,我们才会推荐给业务方。
三.选对没有?

接下来,我们要考虑的问题是选型选对了吗?“线上是检验一切的真理!”只有上线了,才能知道这个东西到底是否适合平台使用。产品上线和女生买鞋子很相似,肯定会有一个磨合期,这个期间可能会出现各种各样的线上问题和参数调优的问题。
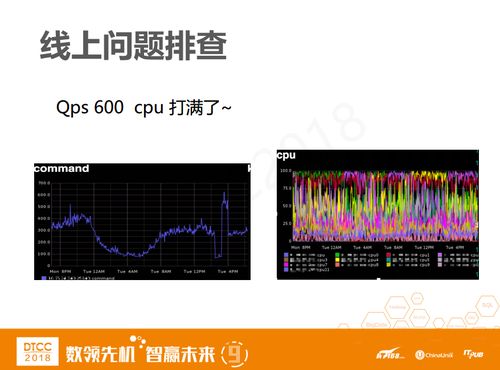
针对这两个问题,我们也有一些基本案例。以Pika为例,上图中command数其实是读+写的command数总和,它只有600QPS,与我的7万压缩数据还差得很远。而且这时它的CPU已经是满存量了。
这种情况业务方肯定是不可能满意的,所以我们在上线之初,肯定就会去分析为什么CPU会这么高。

我们可以看到有一组端口是异常状态,先使用top查看基本信息。

Top查看之后,我肯定就想要知道进程到底在干嘛?所以,肯定会去perf看一下它在调用哪些函数。

如果是刚开始不了解这个软件的时候,我肯定不会知道这个函数到底是干什么的,所以会去翻看相关的函数以及rocksdb相关的日志,结果发现它当时是在level进行compact。

大家肯定会想知道为什么会触发compact,而且是一直不断的在compact?问题排查后发现单个文件的size都大于一个level触发compact的size,因而导致level-1不断的compact。图中红框圈出的有一个比较核心的参数。
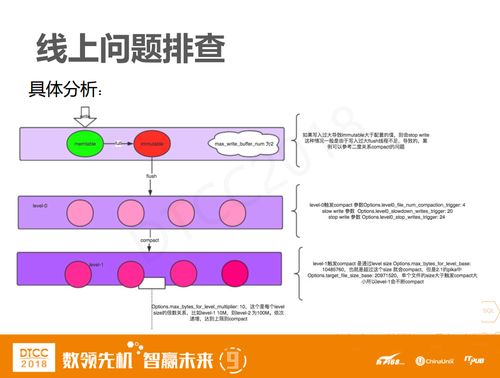
上图是具体分析RocksDB如何触发compact的。Level 0中有一个触发参数,假设compact的触发参数是4,那么当文件数到达4的时候就进行compact,当文件数到达20的时候,就写入减缓,而当达到24时就直接停止写入。
类似于最上面的缓存,write层是根据配置来调的,如果flush线程不及时flush的话,那也会有一个读写的操作。我们之前在二部关系上线的时候,在业务大量灌数据的时候就出现了读写业务直接写不进去的情况。
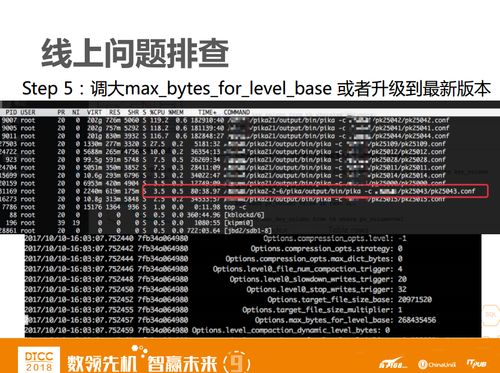
我们看到level-1层的单个文件大小是20M左右,但整一层文件数总和是10M左右,而level-1的配比是根据整一层到底有多大来进行compact,如果你达到10M我就进行compact,这个配置其实是很小的。
定位到问题是level层过小了之后,我们要做的就是把参数调大,重新编译后上线。当然有时也可能是版本问题,因为我们跟进Pika比较早,使用的是2.1版本,而上面出现的这个问题在Pika 2.2.6版本中已经解决了。这也折射出一个问题,在选型时,选择哪个版本去跟进也是一个值得思考的问题。

Myrocks上线时,因为是一个比较新兴的业务,所以库表结构比较简单,之后随着业务功能的丰富,肯定是会增加字段的,但是众所周知Myrocks是不支持在线改表的,我只能临时拿一个从库测试改表操作会带来多大的影响。从图中可以看到,三个小时我都改不完一个表。

其实表并不是很大,为什么三个小时都改不完呢?我也很纳闷,当时的直觉是可能需要调整一些参数,在查看了官网和大牛博客之后,找到了这两种参数,调优之后,从三个小时减少到了24分钟左右,这个值是一个比较合理的值了,我们就和业务方合作把这个表成功的改掉了。
刚才我们提到了压测有多么费力、问题有多么频发……那么从中我们能有什么样的收益?我认为这个收益可以从两个方面来谈,首先是对个人的成长,无论是压测还是线上磨合期,对于大多数人都不会是一个很舒适的经历,问题出的多,要调的参数也很多,但是它带给了我们不一样的成就感,就像在打攻坚战,每攻下一个堡垒,对于新组件的理解就又深入了一层。
第二个收益就是对部门和平台的影响。
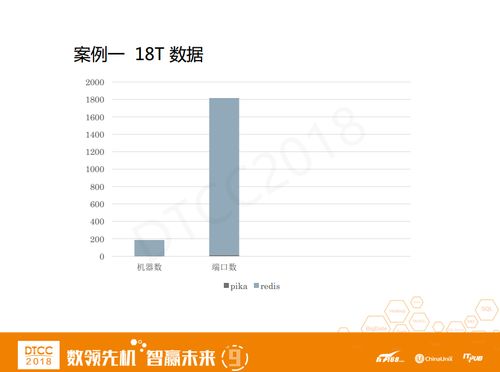
以18T数据为例,如果是用Redis存储的话,可能需要180台机器左右,但是现在我们只用了16个端口和八台机器就把这个问题解决了。对于业务方来说,Pika在我们平台已经大范围推广开来了,例如在用户关系、搜索、手机微博等等,为公司节约的成本也是非常可观的。
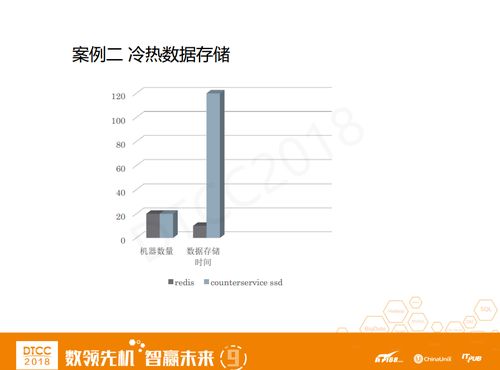
在Counterservice SSD的计数场景中,之前我们使用了20台机器,而且用内存存储的话,只能存储十个月左右的数据。但是改造之后,Counterservice SSD用十台机器加了一点磁盘,就可以存储十年的数据都没有问题。

Myrocks压缩,从通讯录业务来看,压缩比达到3:1是没有问题的,之后我们也会在微博中大范围推广开来,例如在大数据量MySQL的业务、日志类等场景中都可能上线Myrocks。
来自 “ ITPUB博客 ” ,链接:http://blog.itpub.net/31137683/viewspace-2213763/,如需转载,请注明出处,否则将追究法律责任。
转载于:http://blog.itpub.net/31137683/viewspace-2213763/