kafka-概念和内部原理理解
kafka是什么? 是一个分布式的消息系统。(支持分区的(partition)、多副本的(replica),基于zookeeper协调的分布式消息系统)。
主要应用场景是:
日志收集系统: ELK+kafka 可以跟进写一篇ELK的博客
消息系统
主要的概念:
Broker :消息中间件处理节点,一个Kafka节点就是一个broker,一个或者多个Broker可以组成一个Kafka集群
Topic:逻辑上的概念,Kafka根据topic对消息进行归类,发布到Kafka集群的每条消息都需要指定一个topic
Partation: 物理上的概念,一个topic可以分为多个partition,Partation本质是一个目录。内部维护了一些大小均等的segment(段)文件。每个partition内部消息是有序的
Replication:副本。 0.8版本之前,没有这个概念,当broker宕机后,该broker内部所有的partation都不可用,并且没有备份数据,数据可靠性不高。使用Replication可以实现生产者和消费者都连接leader,flow同步leader数据
个人理解,可能会有偏差:

segment: 段 partation内部维护了大小(文件上限)相同的文件,但是每个文件内部数量可能不一致
kafka的核心总控器Controller:
集群中有一个或多个broker,controller可以理解为集群的leader。负责管理整个集群的分区和副本的状态
职责: 1、某个分区的leader副本挂了,controller为该分区选举新的leader
2、当某个分区的isr集合发生变化,由controller通知broker更新
3、当topic增加分区时,由controller重新分配
controller的选举: kakfa启动时,会在zookeeper上创建/controller的临时节点,创建成功的就是controller,会保存对应的节点信息。controller对应的broker宕机后,其他的broker会创建该节点
原理:controller会监听zookeeper的 /broker/ids,监听broker的变化
会监听zookeeper的 /broker/topics变化
会监听zookeeper的 /broker/topics/【topic】/partation 监听topic内部具体的分区变化
Partation怎么选举出副本的leader:
controller会监听所有的分区leader所在的broker,broker挂了以后,会在副本列表中找到第一个,并且存在于ISR内的节点,选举为leader
offest:
kafka中,是消费者自己维护偏移量的。consumer会将自己消费分区的offest,提交给kafka的_consumer_offest 这个topic,这个topickafka默认会分配50个分区,抗高并发。
rebalance:
一个消费组里面,一个分区数据,只会被一个消费者所消费。那么出现这样一个情况,当其中一个消费者挂了,如果不做任何处理,那么部分分区的数据就会出现丢失的情况
rebalance所做的就是挂了后,自动将分区分配给其他消费者消费
哪些情况会触发rebalance:
1、consumer所在服务器重启或者宕机了
2、动态的给topic增加了分区
3、消费组订阅了更多的topic
rebalance的过程:
1、选择组协调器
组协调器GroupCoordinator :用来监听消费者的状态,同步分区规则,并开启rebalance
消费组发送一个findCoordinatorRequest请求,选出对应的组协调器
公式: hash(consumerGroup id )% _consumer_offest数量(默认50) 获取到对应的分区所在的broker
2、加入消费组 JoinGroupRequest
成功找到zu协调器后,消费者会发送命令,加入消费组,并且第一个建立连接的,被选为leaderCoordinator(消费组协调器),这个leader会指定分区方案
3、同步分区方案
leaderCoordinator 消费组协调器 会发送SyncGroupRequest给组协调器,组协调器会将这个分区方案下发给所有的消费者,按照这个方案消费对应分区。
rebalance分区策略:
range : 10个分区(0~10) 3个consumer int n= 10/3 =3 int m = 10%3=1 前m个分区,消费n+1 后(消费者数量-m)个消费n个分区
round-robin:轮着分配
sticky策略就是在rebalance的时候,需要保证如下两个原则
1、分配尽量均匀
2、与上次尽量保持一致

produce发送消息的机制:
1、发送者采用push的模式,将消息发送到broker,
2、具体到哪一个partation,根据分区算法,路由机制如下:
1、指定partation,直接发送到partation
2、指定了key,根据key hash,到指定partation
3、未指定key和partation,采用轮询
流程如下:

HW与LEO详解 :
hw:高水位 取所有分区(ISR)中,最小的LEO。
翻译下:一个topic下有多个存活的partation,HW就是所有节点,里面最低的消息条数(木桶效应里面的最短的那个板)为HW.
LEO(log-end-offset):收到的消息数。
一般情况下,在ack=-1,leader副本收到了消息,但是follower需要从leader同步数据。如果数据没完全同步,那么follower的HW就低于leader,那么消费者就不能消费到这一条记录。只有当所有节点都同步到了这条数据,消费者才能消费该记录
安利一个kafka的管理工具:可以参考这个安装https://www.cnblogs.com/dadonggg/p/8205302.html
原理其实就是连接zk,拿到一些kafka信息,可以安装试试看

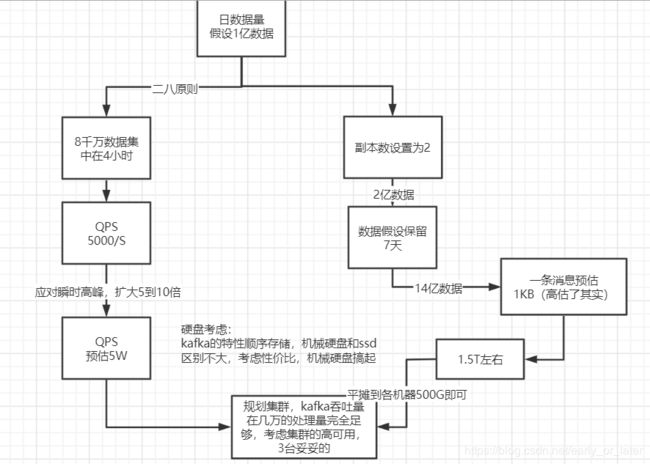
如何规划我们的kafka配置呢?(磁盘、集群个数等)
线上问题
1、消息丢失情况:
生产者: 1、ack=0 表示生产者不需要等待broker的收到消息的回复,直接发送下一条消息,性能高,但容易丢数据
2、ack=1 表示生产者只需要等待leader的回复,不需要等待follower,如果leader收到消息后,还没同步成功, leader就挂了,那么就会出现消息丢失
3、ack=-1 或all 表示生产者需要等待leader和所有备份(min.insync.replicas配置的备份个数)都写入日志,这种策略 数据可靠性高,但是性能低。当min.insync.replicas=1 时,和ack=1一样,会丢失数据
消费者:如果设置自动提交,万一消费到的数据还没处理完,就提交了offest,consumer宕机,那么这条数据就丢了
解决:根据具体业务而定,如果是可以允许少量丢失,其实ack=1 完全满足。毕竟宕机情况偏少
如果是完全不可以丢失,则针对生产者和消费者可能出现的情况,配置ack=-1、设置副本数和 min.insync.replicas,消费者的提交设置为手动提交
2、消息重复消费
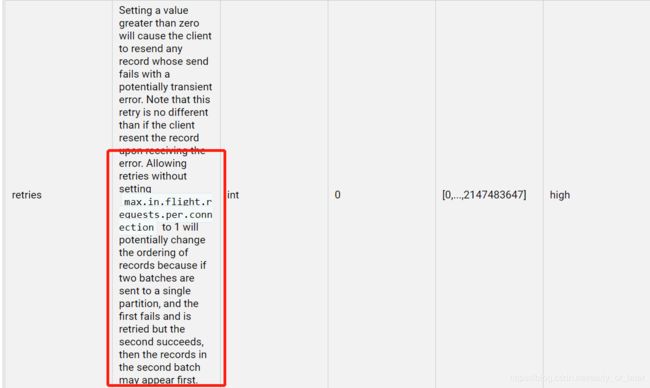
生产者: 配置了重试(retries)机制,由于网络抖动,导致发送超时,重试,但是broker实际上已经收到了消息,重复了!
消费端:消费端设置了自动提交,刚处理部分数据,但是挂了,offest未提交改变,重复消费
处理记录的时间过长或者心跳超时,kafka觉得这个消费者已经挂了,rebalance,导致重复
解决:超时等情况,可修改配置处理,官网其实也给出了方案,配置一把即可

消息做幂等性操作
1、使用唯一标识过滤:
业务场景中可以增加逻辑判断。拿之前项目中的经验。平台有创建支付记录的操作,但是创建支付记录之前,会根据全局唯一的一个paymentId,去先getPaymentInfo() 查询到了直接返回,获取不到,直接调用savePaymentInfo() 其实这里就是做了一把幂等性
2、使用token等,可以放在redis,操作完了直接删除,保证唯一
3、消息乱序
配置了重试的时候,kafka不会等之前的消息完全成功,就发送下提条 123 三条消息 1失败 23成功 1重试成功,顺序就会变成231
解决思路:1、官网其实也提醒我们,需要配置max.in.flight.requests.per.connection (kafka在单个连接上,能够发送的未响应请求的个数)
2、直接配置ack=0 全链路顺序搞定,这个具体看业务而定
3、同步的方式处理
4、消息积压
1、生产者生产速度太高,消费者速度低于生产速度,产生积压
解决:1、增加分区,消费组消费不同分区消息
2、可以做消息转发,构建一个多分区,多消费者的其他topic,缓解积压
2、消费者内部有bug,阻塞了消费
解决:1、解决bug
2、 构建一个死信队列,将失败消息转存过去,后续再分析 (目前项目中的稽核系统,本质就是这个思想)
5、分区数越多吞吐量越高吗
1、设置过大,可能创建的时候直接报错 Too many open files 句柄数过大,文件描述符不足
2、 kafka‐producer‐perf‐test.sh 性能压测一把,可以发现到达一个值以后,性能反而下降