Python:使用 MitmProxy 自动抓取微信公众号阅读数、点赞和再看数据
前言
本文的文字及图片来源于网络,仅供学习、交流使用,不具有任何商业用途,版权归原作者所有,如有问题请及时联系我们以作处理。
作者:某某白米饭
PS:如有需要Python学习资料的小伙伴可以加点击下方链接自行获取
python学习交流群,点击即可加入本群
某天接到一个需要抓取某某微信公众的所有历史文章的阅读数、点赞和再看数据的需求。
为了解放双手,就用 Python 代码撸一个,选择 MitmProxy 代理作为抓包工具,因为它可以使用 Python 代码监听抓取到的 url,用于自动获取 cookie 等场景。
什么是 MitmProxy
mitmproxy 是一个支持 HTTP 和 HTTPS 的抓包程序,有类似 Fiddler 的功能。
mitmproxy 还有两个关联组件。一个是 mitmdumvp,它是 mitmproxyv 的命令行接口,可以利用 Python 代码监听请求。另一个是 mitmweb,它是一个 Web 程序,可以观察 mitmproxy 抓取的请求。
安装和设置
使用 pip 安装
pip install mitmproxy
安装好之后,将手机端的代理 IP 设置为和 PC 的 IP 地址一样,和代理端口设置为:8080,用下面命令启动
mitmweb
将看到浏览器打开了一个 http://127.0.0.1:8081/#/flows 网页,这个就是 MitmProxy 的 web 控制台

在手机端浏览器输入 mitm.im 获取 PC 证书 和手机端的证书,都安装一下

注意:android 手机在安装证书时需要在[从存储设备安装]界面安装
阅读数、再看、点赞抓取
当安装好证书和设置好手机端 IP 代理后,随便点击一篇微信公众号文章(这里使用本公众)

从图上可以看到,阅读、再看、点赞的 url 为 https://mp .weixin. qq. com/mp/getappmsgext(提示:如果没有这个链接,可以右上角刷新文章),再看下它的 request 请求需要哪些东西
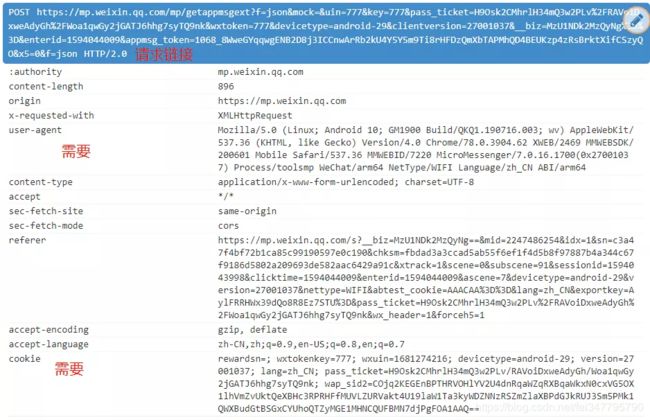
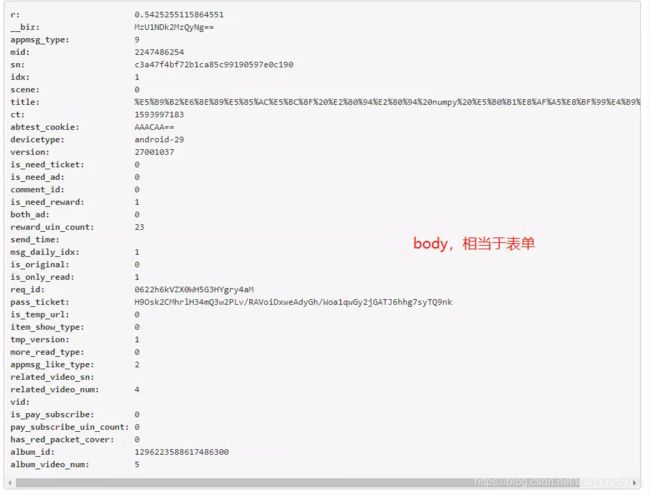
只需要一个文章 url、user-agent、cookie 和 body 这四个基本的数据,别看下面 body 里面有二三十个数据其实都是吓唬人的,只需要其中7个,分别是 __biz, mid, idx,sn 这四个参数是获取公众号文章内容的基石,可以在文章 url 处获得。其他三个参数的数据是固定的分别是 is_only_read = 1,is_temp_url = 0,appmsg_type = 9。getappmsgext 请求中的 appmsg_token 是一个有时效性的参数。
分析完链接后就可以写代码了
import html
import requests
import utils
from urllib.parse import urlsplit
class Articles(object):
"""文章信息"""
def __init__(self, appmsg_token, cookie):
# 具有时效性
self.appmsg_token = appmsg_token
self.headers = {
"User-Agent": "Mozilla/5.0 AppleWebKit/537.36 (KHTML, like Gecko) Version/4.0Chrome/57.0.2987.132 MQQBrowser/6.2 Mobile",
"Cookie": cookie
}
self.data = {
"is_only_read": "1",
"is_temp_url": "0",
"appmsg_type": "9",
}
def read_like_nums(self, article_url):
"""获取数据"""
appmsgstat = self.get_appmsgext(article_url)["appmsgstat"]
return appmsgstat["read_num"], appmsgstat["old_like_num"], appmsgstat["like_num"]
def get_params(self, article_url):
"""
获取到文章url上的请求参数
:param article_url: 文章 url
:return:
"""
# url转义处理
article_url = html.unescape(article_url)
"""获取文章链接的参数"""
url_params = utils.str_to_dict(urlsplit(article_url).query, "&", "=")
return url_params
def get_appmsgext(self, article_url):
"""
请求阅读数
:param article_url: 文章 url
:return:
"""
url_params = self.get_params(article_url)
appmsgext_url = "https://mp. weixin.qq.com/mp/getappmsgext?appmsg_token={}&x5=0".format(self.appmsg_token)
self.data.update(url_params)
appmsgext_json = requests.post(
appmsgext_url, headers=self.headers, data=self.data).json()
if "appmsgstat" not in appmsgext_json.keys():
raise Exception(appmsgext_json)
return appmsgext_json
if __name__ == '__main__':
info = Articles('1068_XQoMoGGBYG8Tf8k23jfdBr2H_LNekAAlDDUe2aG13TN2fer8xOSMyrLV6s-yWESt8qg5I2fJr1r9n5Y5', 'rewardsn=; wxtokenkey=777; wxuin=1681274216; devicetype=android-29; version=27001037; lang=zh_CN; pass_ticket=H9Osk2CMhrlH34mQ3w2PLv/RAVoiDxweAdyGh/Woa1qwGy2jGATJ6hhg7syTQ9nk; wap_sid2=COjq2KEGEnBPTHRVOHlYV2U4dnRqaWZqRXBqaWl3Xy1saXVWYllIVjAzdlM1VkNDNHgxeWpHOG9pckdkREMwTFEwYmNWMl9FZWtRU3pRRnhDS0pyV1BaZUVMWXN1ZWN0WnZ6aHFXdVBnbVhTY21BYnBSUXNCQUFBMLLAjfgFOA1AAQ==')
a, b,c = info.read_like_nums('http://mp. weixin.qq.com/s?__biz=MzU1NDk2MzQyNg==&mid=2247486254&idx=1&sn=c3a47f4bf72b1ca85c99190597e0c190&chksm=fbdad3a3ccad5ab55f6ef1f4d5b8f97887b4a344c67f9186d5802a209693de582aac6429a91c&scene=27#wechat_redirect')
print(a, b, c)
示例结果
# 阅读数 点赞数 再看数
1561 23 18
动态获取 cookie 和 appmsg_token
appmsg_token 是一个具有时效性的参数,和 cookie 一样是需要改变的,当这两个参数过期时就需要从抓包工具(MitmProxy 中)ctrl+C,ctrl+V到代码中,很是麻烦。
MitmProxy 可以使用命令行接口 mitmdumvp 运行 Python 代码监听抓取的链接,如果抓到了 https://mp. weixin.qq.com/mp/getappmsgext 就保存在本地文件并退出抓包
mitmdump 命令
# -s 运行的python脚本, -w 将截取的内容保持到文件
mitmdump -s write_cookie.py -w outfile mp.weixin.qq.com/mp/getappmsgext
监听脚本
import urllib
import sys
from mitmproxy import http
# command: mitmdump -s write_cookie.py -w outfile mp.weixin.qq.com/mp/getappmsgext
class WriterCookie:
"""
mitmproxy的监听脚本,写入cookie和url到文件
"""
def __init__(self, outfile: str) -> None:
self.f = open(outfile, "w")
def response(self, flow: http.HTTPFlow) -> None:
"""
完整的response响应
:param flow: flow实例,
"""
# 获取url
url = urllib.parse.unquote(flow.request.url)
# 将url和cookie写入文件
if "mp. weixin.qq.com/mp/getappmsgext" in url:
self.f.write(url + '\n')
self.f.write(str(flow.request.cookies))
self.f.close()
# 退出
exit()
# 第四个命令中的参数
addons = [WriterCookie(sys.argv[4])]
监听脚本写好之后,再来写启动命令和解析 url,cookie 文件的模块
import re
import os
class ReadCookie(object):
"""
启动write_cookie.py 和 解析cookie文件,
"""
def __init__(self, outfile):
self.outfile = outfile
def parse_cookie(self):
"""
解析cookie
:return: appmsg_token, biz, cookie_str·
"""
f = open(self.outfile)
lines = f.readlines()
appmsg_token_string = re.findall("appmsg_token.+?&", lines[0])
biz_string = re.findall('__biz.+?&', lines[0])
appmsg_token = appmsg_token_string[0].split("=")[1][:-1]
biz = biz_string[0].split("__biz=")[1][:-1]
cookie_str = '; '.join(lines[1][15:-2].split('], [')).replace('\'','').replace(', ', '=')
return appmsg_token, biz, cookie_str
def write_cookie(self):
"""
启动 write_cookie。py
:return:
"""
#当前文件路径
path = os.path.split(os.path.realpath(__file__))[0]
# mitmdump -s 执行脚本 -w 保存到文件 本命令
command = "mitmdump -s {}/write_cookie.py -w {} mp.weixin.qq.com/mp/getappmsgext".format(
path, self.outfile)
os.system(command)
if __name__ == '__main__':
rc = ReadCookie('cookie.txt')
rc.write_cookie()
appmsg_token, biz, cookie_str = rc.parse_cookie()
print("appmsg_token:" + appmsg_token , "\nbiz:" + biz, "\ncookie:"+cookie_str)
示例结果

cookie.txt 文件内容解析后
appmsg_token:1068_av3JWyDn2XCS2fwFj3ICCnwArRb2kU4Y5Y5m9Z9NkWoCOszl3a-YHFfBkAguUlYQJi2dWo83AQT4FsNK
biz:MzU1NDk2MzQyNg==
cookie:rewardsn=; wxtokenkey=777; wxuin=1681274216; devicetype=android-29; version=27001037; lang=zh_CN; pass_ticket=H9Osk2CMhrlH34mQ3w2PLv/RAVoiDxweAdyGh/Woa1qwGy2jGATJ6hhg7syTQ9nk; wap_sid2=COjq2KEGEnBPTHRVOHlYV2U4dnRqaWZqRXBqaWktTHpUSEJnTTdhU0hVZTEtZXpZZEY4a3lNY29zc0VZeEFvLS01YmJRRnQ5eFRmR2dOY29nUWdKSTRVWG13WE1obGs1blhQcVh0V18tRnBSRnVlc1VhOHNCQUFBMPeIjfgFOA1AAQ==
ReadCookie 模块可以自动获取到 appmsg_token 和 cookie,将它们当作参数一样传递到 Articles 模块中,就能解放双手再也不要复制黏贴 appmsg_token 和 cookie 了,只要在 appmsg_token 过期时刷新一下公众号文章就可以了,省心又省时
批量抓取
在公众号历史消息界面将屏幕向上滑动,每次都可以加载 10 条历史消息,盲猜这个翻页就是批量抓取的请求链接,用 MitmProxy 的 WEBUI 界面在 Response 面板查找一下,找到一个是 https://mp. weixin.qq.com/mp/profile_ext?action=getmsg&__biz=MzU1NDk2MzQyNg==&f=json&offset=10&count=10… 的链接,它的响应返回值中有多个文章标题,再看这个链接上有 offset=10&count=10 参数,一看就是翻页偏移量和每页显示的条数,就它了

在链接中比较重要的参数有:__biz、offset、pass_ticket、appmsg_token ,这些数据都可以在 cookie 和 appmsg_token 中得到。
# utils.py
# 工具模块,将字符串变成字典
def str_to_dict(s, join_symbol="\n", split_symbol=":"):
s_list = s.split(join_symbol)
data = dict()
for item in s_list:
item = item.strip()
if item:
k, v = item.split(split_symbol, 1)
data[k] = v.strip()
return data
import os
import requests
import json
import urllib3
import utils
class WxCrawler(object):
"""翻页内容抓取"""
urllib3.disable_warnings()
def __init__(self, appmsg_token, biz, cookie, begin_page_index = 0, end_page_index = 100):
# 起始页数
self.begin_page_index = begin_page_index
# 结束页数
self.end_page_index = end_page_index
# 抓了多少条了
self.num = 1
self.appmsg_token = appmsg_token
self.biz = biz
self.headers = {
"User-Agent": "Mozilla/5.0 AppleWebKit/537.36 (KHTML, like Gecko) Version/4.0Chrome/57.0.2987.132 MQQBrowser/6.2 Mobile",
"Cookie": cookie
}
self.cookie = cookie
def article_list(self, context):
articles = json.loads(context).get('general_msg_list')
return json.loads(articles)
def run(self):
# 翻页地址
page_url = "https://mp. weixin.qq.com/mp/profile_ext?action=getmsg&__biz={}&f=json&offset={}&count=10&is_ok=1&scene=&uin=777&key=777&pass_ticket={}&wxtoken=&appmsg_token=" + self.appmsg_token + "&x5=0f=json"
# 将 cookie 字典化
wx_dict = utils.str_to_dict(self.cookie, join_symbol='; ', split_symbol='=')
# 请求地址
response = requests.get(page_url.format(self.biz, self.begin_page_index * 10, wx_dict['pass_ticket']), headers=self.headers, verify=False)
# 将文章列表字典化
articles = self.article_list(response.text)
for a in articles['list']:
# 公众号中主条
if 'app_msg_ext_info' in a.keys() and '' != a.get('app_msg_ext_info').get('content_url', ''):
print(str(self.num) + "条", a.get('app_msg_ext_info').get('title'), a.get('app_msg_ext_info').get('content_url'))
# 公众号中副条
if 'app_msg_ext_info' in a.keys():
for m in a.get('app_msg_ext_info').get('multi_app_msg_item_list', []):
print(str(self.num) + "条", m.get('title'), a.get('content_url'))
self.num = self.num + 1
self.is_exit_or_continue()
# 递归调用
self.run()
def is_exit_or_continue(self):
self.begin_page_index = self.begin_page_index + 1
if self.begin_page_index > self.end_page_index:
os.exit()
最后用自动化cookie启动程序后刷新公众号文章
from read_cookie import ReadCookie
from wxCrawler import WxCrawler
"""程序启动类"""ss
if __name__ == '__main__':
cookie = ReadCookie('E:/python/cookie.txt')
cookie.write_cookie()
appmsg_token, biz, cookie_str = cookie.parse_cookie()
wx = WxCrawler(appmsg_token, biz, cookie_str)
wx.run()
示例结果

总结
虽然本文可能有那么一点点一点点的标题党,并没有完全的自动抓取数据,还需要人为的刷新一下公众号文章。希望小伙伴们不要介意哈。