1_1 初始网页的构成
1.1.1学习笔记:
初步认识网页组成:
HTML 标签
/ 图像/ 各种资源内容
照着视频的讲解,建立了第一个我的网页文件。
乱码了,百度一下我就知道: 添加
那么问题就来了: 怎么像WORD 排版一样把某些文字定义居中,设置字体,特定地方显示一个图片?答案:CSS 样式。具体不详。大概就知道它是负责排版的吧。把老师给的图片和CSS 样式的文件夹下载下来,对应添加上去。
总算能看了 ╮(╯▽╰)╭。最后对照参考答案,搞清楚哪一项应该对应哪个class。终于才完成了。心好累。
1.1.2 源代码
The blah
The Beach
stretching from Solta to Mljet, and this unique cycling trip captures the highlights with an ideal
balance of activity, culture and relaxation. Experience the beautiful island of Korcula with its picturesque old town,
the untouched beauty of Vis, and trendy Hvar with its Venetian architecture. In the company of a cycling guide,
this stimulating journey explores towns and landscapes, many of which are on UNESCO's world heritage list.
Aboard the comfortably appointed wooden motor yacht,
there is ample time between cycles to swim in the azure waters and soak up the ambience of seaside towns.
1.1.3 执行结果
原来是对应的class和标签没有对上号。
1.1.4总结
虽然算是完成了,但还感觉很不知其所以然。有必要了解一下HTML的各种标签。
于是买了一本《HTML5权威指南》,很贵,很厚,看评论也很权威,最重要的是,很无聊,完全看不下去……
作罢…… 还是先看视频学爬虫吧,等用到了再说。
1_2 爬取一个本地网页文件的商品信息
1.2.1 学习笔记
打开文件------ witn open() as data
解析网页------soup = BeautifuleSoup()
获取信息------标题= soup.select(),图片 = soup.select()
筛选信息------ 最终要的标题文本=标题[index].text.
最终要的图片链接 = 图片[index].get(‘src’)
1.2.2 源代码
from bs4 import BeautifulSoup
with open('F:\\FileRecv\\课程源码及作业参考答案\\Plan-for-combating-master\\第一周课程\\1.2解析网页中的元素\\1.2练习题答案\\练习题所需网页\\index.html','r') as total_data:
Soup = BeautifulSoup(total_data, 'lxml') # 解析网页内容
titles = Soup.select('body > div > div > div.col-md-9 > div:nth-of-type(2) > div > div > div.caption > h4:nth-of-type(2) > a')
prices = Soup.select('body > div > div > div.col-md-9 > div:nth-of-type(2) > div > div > div.caption > h4.pull-right')
imgs = Soup.select('body > div > div > div.col-md-9 > div:nth-of-type(2) > div > div > img')
visitors = Soup.select('body > div > div > div.col-md-9 > div:nth-of-type(2) > div > div > div.ratings > p.pull-right')
cates = Soup.select('body > div > div > div.col-md-9 > div:nth-of-type(2) > div > div > div.ratings > p:nth-of-type(2)')
#print(cates)
# 打印出来了... 对于星星有些特别,打印出的是5个东西,满星的是
1.2.3 执行结果
1.2.4 总结
1.打开一个本地文件 ___________ with open (‘文件绝对路径名’,’r’) as data:
2.用BeautifuleSoup工具来解析网页 ____________soup =BeatifulSoup(data.text, ‘lxml’)
3.使用Chrome浏览器的监视器,查看某一元素对应的位置 右键->检查->copy (Xpath或者CSS selector)
4.从soup中已经获取的一大堆数据里提出自己单独要的。 —————— soup.select(‘具体位置’)
5.soup.select(‘参数’) __________ CSS selector。或者 标签.类名 > 下一标签, 属性[‘我的属性名’=’我是属性值’。
6 soup.select().find_all(), soup.select().find()。
7 疑问:
soup.select()
的返回对象到底是什么类型的列表呢,它会因为select()
函数里参数给的不同而不同吗。
附上帮助文档,有时间了继续看。
1_3 爬取一个真实网页上的信息
1.3.1 学习笔记/解体思路
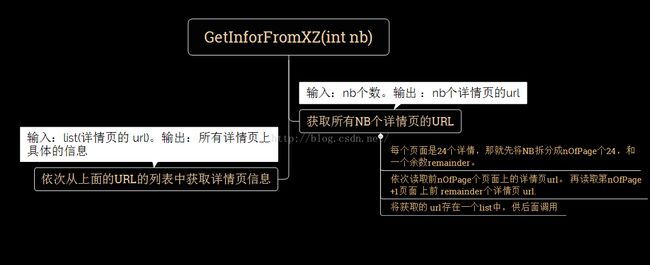
观察每个页面有24个,那么爬取300个,就是要抓取前10页的所有详情页,再爬第12页的所有详情页,加第13页的前12个。
拆分一下步骤:
后来想了一下,这样太不通用了,爬到最后一页只有10页怎么办,中间夹了几条无效链接所以爬取了23或者22页怎么办。所以,应该按顺序爬下去应该更合适。修改一下想法:
1.3.2 源代码
import time
import requests
from bs4 import BeautifulSoup
url = 'http://bj.xiaozhu.com/search-duanzufang-p1-0/'
header = {
'Content-type': 'text/html;charset=UTF-8',
'Referer': 'http://bj.58.com/pbdn/?PGTID=0d409654-01aa-6b90-f89c-4860fd7f9294&ClickID=1',
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/49.0.2623.112 Safari/537.36',
}
#计数的变量
icount = [0];
#获取一个大页面上的详情页地址,并且 判断 当前所抓取的所有url个数是否大于了nbOfUrl
def GetOnePageUrl(url,icount,nbOfUrl):
url_list = []
web_data = requests.get(url,headers=header) # 正常情况下是 Responce[200]
print('请检查当前网络是否正常',web_data.status_code)
soup = BeautifulSoup(web_data.text,'lxml')
urlOnDetail = soup.select('#page_list > ul > li > a ')
#把一个这个页面下的所有详情页的URL装进一个列表里
for urlOnDetail_1 in urlOnDetail:
url_list.append(urlOnDetail_1.get('href'))
#从 urlOnDetail_1里获取数据,装进对象里。或者
icount[0] += 1
if(icount[0] >= nbOfUrl):
break
print('读取URL条数 :',icount[0])
return url_list
#当前页面翻页到下一页
def gotoNextPage(url):
nPage = int(url[-4]) #是否需要添加异常处理.. 如果这个不是数字呢,返回的是什么
a = int(nPage);a += 1
url_s = 'http://bj.xiaozhu.com/search-duanzufang-p{}-0/'.format(a)
return url_s
#按详情个数去爬,比如爬300条 urls = GetNumberDetail(300) def GetPageUrl_ForPage(nb):
def GetPageUrl_ForPage(nb):
url_ToChange = url
urllist = []
while(icount[0] nb):
break
time.sleep(2)
return urllist
#给定大页面个数,按大页面去爬,不管每一页包含有多少详情页
def GetNBPageDetail(nPage):
urllist = []
for i in range(1,nPage):
url_ToChange = 'http://bj.xiaozhu.com/search-duanzufang-p{}-0/'.format(i)
urllist.extend(GetOnePageUrl(url_ToChange, icount,1000000)) #本意是不让这个函数因为到达了nb而跳出,那就把nb设很大
time.sleep(2)
return urllist
#根据传进来的参数来判断性别 #男的是member_ico,保保存的member_icol
def GetSuxual(strList):
try:
if(len(strList[0])==10):
return '男'
elif(len(strList[0])==11):
return '女'
else:
print('检查一下,性别好像没抓对哦')
return None
except(IndexError):
print('检查一下,性别好像没抓到哦')
return None
#获取一个详情页上的所有信息,并返回一个字典()
def GetOneDetailInfor(url):
#需要获取的数据有: title ,district, price, hostPicSrc,hostSexual,
web_data = requests.get(url,headers=header)
soup = BeautifulSoup(web_data.text,'lxml')
titles = soup.select('body > div.wrap.clearfix.con_bg > div.con_l > div.pho_info > h4 > em')
imgs = soup.select('#curBigImage ')
districts = soup.select('body > div.wrap.clearfix.con_bg > div.con_l > div.pho_info > p > span.pr5') #它应该返回的是一个列表
prices = soup.select('#pricePart > div.day_l > span')
hostNames = soup.select('#floatRightBox > div.js_box.clearfix > div.w_240 > h6 > a')
hostPicSrcs = soup.select('#floatRightBox > div.js_box.clearfix > div.member_pic > a > img')
hostSexuals = soup.select('#floatRightBox > div.js_box.clearfix > div.member_pic > div') #它根据字符数目来判断
# print(hostSexuals)
#爬下来后,先打印着看一下
for title,district,img,price,hostName,hostPicSrc,hostSexual in zip(titles,districts,imgs,prices,hostNames,hostPicSrcs,hostSexuals):
data={
'title =':title.get_text(),
'district=':district.get_text().strip(),
'price=': price.get_text(),
'hostName=': hostName.get_text(),
'hostPicSrc=': hostPicSrc.get('src'),
'hostSexual=': GetSuxual(hostSexual.get('class')),
'img=': img.get('src'),
}
print(data)
urls = GetPageUrl_ForPage(300)
#urls = GetNBPageDetail(4) #如果调用这个函数,就是获取前3页的所有详情页url了。
for i,url in zip(range(1,len(urls)+1),urls):
print(i,url)
GetOneDetailInfor(url)
1.3.3 执行结果
哗哗哗跑到300个,感觉很棒哟,有些页面上没有写性别。
.1.3.4总结
1获取列表/字典/字符串的长度 len(列表)
2 如果抓失败了,XX.select()返回的是空的,那么这时候去给下标索引,编译器会报错。所以了解了一下PYTHON 中捕获下标溢出的异常 。
try: .... exception(IndexErro)。后来发现有些确实是没有房东性别的,不知道还会不会有其他的在某些网页里是没有的。所以其实应该每个都判断一下?
3 函数参数选择列表类型,函数结束了之后它也被修改了。实现了实参的传递。
4 学习了列表的几个函数 appen().extend()
5 字符串函数 strip(),去掉多余的,不想要的字符。
6 要在requests.get(url,headers)中添加headers,仿造是我们自己手动打开的网页,而不是爬虫。
7.一次解决一个问题。这样脑子不会乱成一锅粥,出问题了也好排查?所以我下载了XMIND,来学着画思维导图流程图(WORD画起来有点慢,就是这个付费版好贵哟 0..0)。
8.
待解决:
PYTHON 传递实参还有其他方法吗。
异常还要多看看手册描述。
如果要爬很多很多条,可以在获取了url_list以后写到本地文件中?这样就不会轻易丢失了。
看了参考答案,原来可以写的那么简洁啊,一样的问题我这罗里吧嗦的……大可不必弄个实参计数啊。/(ㄒoㄒ)/~~ 多练多练。
1_4 获取某个真实网站上的图片地址,并将其下载到本地
1.4.1 学习笔记
urllib
模块提供的
urlretrieve()
函数。
urlretrieve()
方法直接将远程数据下载到本地。
1.4.2 源代码
#爬取照片并保存
from bs4 import BeautifulSoup
import requests
import time
import urllib.request
import urllib
import os
header = {
'Content-type': 'text/html;charset=UTF-8',
'Referer': 'http: // weheartit.com / inspirations / taylorswift',
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/49.0.2623.112 Safari/537.36',
}
# 先写爬取一页上面的东西,把地址传进去,获取它上面的图片地址
def GetPicSrc(url):
wb_data = requests.get(url)
soup = BeautifulSoup(wb_data.text,'lxml')
#img = soup.get('div.js-ckick0-out > img')
img = soup.get('#main-container > div > div.grid-thumb.grid-responsive > div:nth-child > div > div > div > a')
print(img)
def callBack(a,b,c):
'''回调函数
@a:已经下载的数据块
@b:数据块的带下
@c:远程文件的带下
'''
per = 100.0 * a * b / c
if(per>100):
per = 100.0
print(per)
def GetOnePageData(url):
data=[]
dataID=[]
wb_data = requests.get(url,headers=header)
soup = BeautifulSoup(wb_data.text, 'lxml')
img_addresses =soup.select('#main-container > div > div.grid-thumb.grid-responsive > div > div > div > a ')
inter = 1
path = 'E:\\Python-TEST\\'
for img_address in img_addresses:
dataID = img_address.get('href')
print("http://weheartit.com/"+dataID) #打印的是详情页的URL
dataID_NB = dataID.split('/')[2]
print(dataID_NB)
src_img ='http://data.whicdn.com/images/'+dataID_NB+'/large.jpg' #这是照片url
print(src_img)
urllib.request.urlretrieve(src_img, path+dataID_NB+'/large.jpg',callBack)
time.sleep(2)
print('Done')
return data
GetOnePageData('http://weheartit.com/inspirations/taylorswift')
1.4.3 执行结果
然而我失败了 =..= 能打印正确的图片地址,但是使用了urlretrieve函数后,会报错。
听说是对方服务器的问题。那先放着,改天换个网站试试。
1.4.4 总结
2. 一个新的库 import
1_5 实战大作业
1.5.1 学习笔记
1. 观察网页 http://bj.58.com/pbdn/0/pn1/ =http://bj.58.com/pbdn/0/
第二页: http://bj.58.com/pbdn/0/pn2/
推测: 第N页 http://bj.58.com/pbdn/0/pnN/
1. 获取第一页的所有详情页URL,保存在一个url_list中
2. 根据url_list提供的地址,获取该页面上的值。
1.5.2 源代码
#coding=utf-8
from bs4 import BeautifulSoup
import time
import requests
#获取地址为url网页上的浏览量的信息
header = {
'Content-type': 'text/html;charset=UTF-8',
'Referer': 'http://bj.58.com/pbdn/0/pn1/?pts=1463556777417',
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/49.0.2623.112 Safari/537.36',
}
def get_views_from(url):
id = url.split('/')[-1].strip('x.shtml')
api = 'http://jst1.58.com/counter?infoid={}'.format(id)
# 这个是找到了58的查询接口,不了解接口可以参照一下新浪微博接口的介绍
js = requests.get(api,headers=header)
# print('从这里获取访问量',api)
views = js.text.split('=')[-1]
return views
#获取一个详情页的信息
def EmptyMessageShow(mylist):
if(mylist==[]):
print('没抓到')
def GetCategory(cates):
cate = []
n = len(list(cates.find_all('a')))
for i in list(cates.find_all('a')):
cate.append(i.get_text())
return cate
import time
def GetOneDetailData(url):
# time.sleep(2)
data = {}
print('进入页面: ',url)
wb_data = requests.get(url,headers=header)
soup = BeautifulSoup(wb_data.text,'lxml')
cates = soup.select('#header > div.breadCrumb.f12')
# header > div.breadCrumb.f12 > span > a
titles=soup.select('#content > div.person_add_top.no_ident_top > div.per_ad_left > div.col_sub.mainTitle > h1')
times = soup.select('#index_show > ul.mtit_con_left.fl > li.time')
prices = soup.select('#content > div.person_add_top.no_ident_top > div.per_ad_left > div.col_sub.sumary > ul > li > div.su_con > span')
oldOrNews = soup.select('#content > div.person_add_top.no_ident_top > div.per_ad_left > div.col_sub.sumary > ul > li > div.su_con > span')
if (len(soup.select('#content > div.person_add_top.no_ident_top > div.per_ad_left > div.col_sub.sumary > ul > li > div.su_con > span > a'))==0):
districts=['未填']
else:
districts = soup.select('#content > div.person_add_top.no_ident_top > div.per_ad_left > div.col_sub.sumary > ul > li:nth-of-type(3) > div.su_con > span ')
visitors = list(get_views_from(url)) #为了和其他变量一起打包到zip中
for cate,title,mytime,price,oldOrNew,district,visitor in zip(cates,titles,times,prices,oldOrNews,districts,visitors):
data ={
'title=': title.get_text(),
'cate = ': cate, #GetCategory(cate),
'time = ': mytime.text,
'price =' : price.get_text(),
'oldOrNow = ': oldOrNew.get_text() ,
'district=': list(district.stripped_strings) if(district!='未填') else district,
'visitior': visitor
}
if(data == {}):
print('没爬到信息哦 ')
print(data)
return data
#获取一个页面上的所有详情页url,去掉推广商品,去掉转转
def GetOnePageURL(url):
href = []
wb_data = requests.get(url)
soup = BeautifulSoup(wb_data.text, 'lxml')
singlehref = soup.select('td.t a.t')
for data in singlehref:
ifzhuanzhuan = data.get('href')[:26] =='http://m.zhuanzhuan.58.com' #这是转转商品地址的也正
ifTuiGuang = data.get('href')[:11] =='http://jump' #这是推广商品的特征
if ifzhuanzhuan or ifTuiGuang:
# href.append(data.get('href'))#好长的名字啊,老师说问号之后的不要了 ..
print('跳过')
else:
# href.append(data.get('href').split('?')[0]) 可是用了这个,第一个竟然不一样了
href.append(data.get('href'))
print('这一页有',len(href),'个商品信息')
return href
# 还要加一层 ...可能有多页
def get_links_from(numPages):
urls = []
for iPage in range(1,numPages+1):
list_view = 'http://bj.58.com/pbdn/0/pn{}/'.format(str(iPage))
# wb_data = requests.get(list_view)
# soup = BeautifulSoup(wb_data.text,'lxml')
# for link in soup.select('td.t a.t'):
urls.append(list_view)
return urls
# 要调用的函数,就成了一下的:
def run(numPages=1):
urls = get_links_from(numPages) #获得好几个页面.
print(urls)
for url in urls:
urlPage = GetOnePageURL(url)
# print(urlPage)
for urlOnePage in urlPage:
GetOneDetailData(urlOnePage)
time.sleep(2)
run(1) #就爬第一页
1.5.3 执行结果
1.5.4总结
1.没有爬到访问量,老师给了参考答案,再消化一下,执行成功了后修改。
2. 学习到了 soup.select()[0].stripped_strings
疑问:
什么样的类型可以强制转换成列表呢。
路漫漫兮 ~~~~