MapReduce Design Patterns-chapter 5
CHAPTER 5:Join Patterns
A Refresher on Joins
INNER JOIN
With this type of join, records from both A and B that contain identical values for a given foreign key f are brought together, such that all the columns of both A and B now make a new table. Records that contain values of f that are contained in A but not in B, and vice versa, are not represented in the result table of the join operation.
OUTER JOIN
records with a foreign key not present in both tables will be in the final table.
In a left outer join, the unmatched records in the “left” table will be in the final table,with null values in the columns of the right table that did not match on the foreign key. Unmatched records present in the right table will be discarded. A right outer join is the same as a left outer, but the difference is the right table records are kept and the left table values are null where appropriate. A full outer join will contain all unmatched records from both tables, sort of like a combination of both a left and right outer join.
ANTIJOIN
An antijoin is a full outer join minus the inner join
CARTESIAN PRODUCT
A Cartesian product or cross product takes each record from a table and matches it up with every record from another table. If table X contains n records and table Y contains m records, the cross product of X and Y, denoted X × Y, contains n × m records.
Reduce Side Join
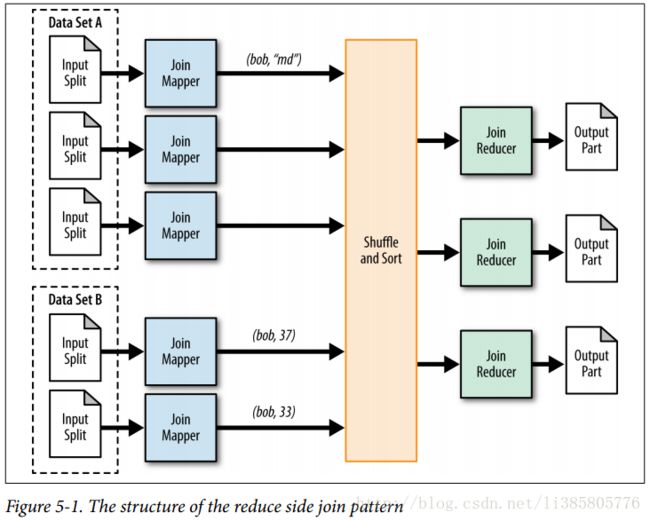
In the following example, two mapper classes are created: one for the user data and one for the comments. Each mapper class outputs the user ID as the foreign key, and the entire record as the value along with a single character to flag which record came from what set. The reducer then copies all values for each group in memory, keeping track of which record came from what data set. The records are then joined together and output.
Problem: Given a set of user information and a list of user’s comments, enrich each comment with the information about the user who created the comment.
Dirve Code
...
// Use MultipleInputs to set which input uses what mapper
// This will keep parsing of each data set separate from a logical standpoint
// The first two elements of the args array are the two inputs
MultipleInputs.addInputPath(job, new Path(args[0]), TextInputFormat.class,
UserJoinMapper.class);
MultipleInputs.addInputPath(job, new Path(args[1]), TextInputFormat.class,
CommentJoinMapper.class);
job.getConfiguration()..set("join.type", args[2]);
...
Map Code
public static class UserJoinMapper extends Mapper {
private Text outkey = new Text();
private Text outvalue = new Text();
public void map(Object key, Text value, Context context)
throws IOException, InterruptedException {
// Parse the input string into a nice map
Map parsed =
MRDPUtils.transformXmlToMap(value.toString());
String userId = parsed.get("Id");
// The foreign join key is the user ID
outkey.set(userId);
// Flag this record for the reducer and then output
outvalue.set("A" + value.toString());
context.write(outkey, outvalue);
}
} public static class CommentJoinMapper extends
Mapperlt;Object, Text, Text, Text> {
private Text outkey = new Text();
private Text outvalue = new Text();
public void map(Object key, Text value, Context context)
throws IOException, InterruptedException {
Map parsed = transformXmlToMap(value.toString());
// The foreign join key is the user ID
outkey.set( parsed.get("UserId"));
// Flag this record for the reducer and then output
outvalue.set("B" + value.toString());
context.write(outkey, outvalue);
}
}
public static class UserJoinReducer extends Reducer {
private static final Text EMPTY_TEXT = Text("");
private Text tmp = new Text();
private ArrayList listA = new ArrayList();
private ArrayList listB = new ArrayList();
private String joinType = null;
public void setup(Context context) {
// Get the type of join from our configuration
joinType = context.getConfiguration().get("join.type");
}
public void reduce(Text key, Iterable values, Context context)
throws IOException, InterruptedException {
// Clear our lists
listA.clear();
listB.clear();
// iterate through all our values, binning each record based on what
// it was tagged with. Make sure to remove the tag!
while (values.hasNext()) {
tmp = values.next();
if (tmp.charAt(0) == 'A') {
listA.add(new Text(tmp.toString().substring(1)));
} else if (tmp.charAt('0') == 'B') {
listB.add(new Text(tmp.toString().substring(1)));
}
}
// Execute our join logic now that the lists are filled
executeJoinLogic(context);
}
private void executeJoinLogic(Context context)
throws IOException, InterruptedException {
...if (joinType.equalsIgnoreCase("inner")) {
// If both lists are not empty, join A with B
if (!listA.isEmpty() && !listB.isEmpty()) {
for (Text A : listA) {
for (Text B : listB) {
context.write(A, B);
}
}
}else if (joinType.equalsIgnoreCase("leftouter")) {
// For each entry in A,
for (Text A : listA) {
// If list B is not empty, join A and B
if (!listB.isEmpty()) {
for (Text B : listB) {
context.write(A, B);
}
} else {
// Else, output A by itself
context.write(A, EMPTY_TEXT);
}
}
}else if (joinType.equalsIgnoreCase("rightouter")) {
// For each entry in B,
for (Text B : listB) {
// If list A is not empty, join A and B
if (!listA.isEmpty()) {
for (Text A : listA) {
context.write(A, B);
}
} else {
// Else, output B by itself
context.write(EMPTY_TEXT, B);
}
}
}else if (joinType.equalsIgnoreCase("fullouter")) {
// If list A is not empty
if (!listA.isEmpty()) {
// For each entry in A
for (Text A : listA) {
// If list B is not empty, join A with B
if (!listB.isEmpty()) {
for (Text B : listB) {
context.write(A, B);
} else {
// Else, output A by itself
context.write(A, EMPTY_TEXT);
}
}
} else {
// If list A is empty, just output B
for (Text B : listB) {
context.write(EMPTY_TEXT, B);
}
}
} else if (joinType.equalsIgnoreCase("anti")) {
// If list A is empty and B is empty or vice versa
if (listA.isEmpty() ^ listB.isEmpty()) {
// Iterate both A and B with null values
// The previous XOR check will make sure exactly one of
// these lists is empty and therefore the list will be skipped
for (Text A : listA) {
context.write(A, EMPTY_TEXT);
}
for (Text B : listB) {
context.write(EMPTY_TEXT, B);
}
}
}
}
Reduce Side Join with Bloom Filter
Saywe are only interested in enriching comments with reputable users, i.e., greater than 1,500 reputation.
在CommentMap中使用Bloom Filter,UserMap中直接保留大于1500
Replicated Join
All the data sets except the very large one are essentially read into memory during the setup phase of each map task, which is limited by the JVM heap. If you can live within this limitation, you get a drastic benefit because there is no reduce phase at all, and therefore no shuffling or sorting. The join is done entirely in the map phase, with the very large data set being the input for the MapReduce job.
The type of join to execute is an inner join or a left outer join, with the large input data set being the “left” part of the operation.All of the data sets, except for the large one, can be fit into main memory of each map task.
The mapper is responsible for reading all files from the distributed cache during the setup phase and storing them into in-memory lookup tables. After this setup phase completes, the mapper processes each record and joins it with all the data stored in-memory.
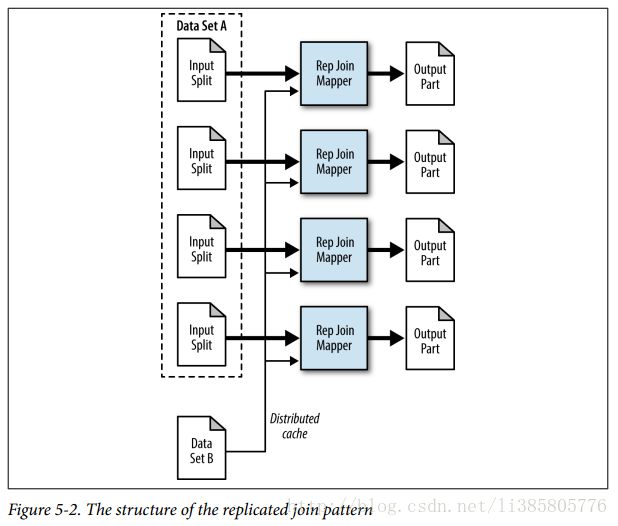
Problem: Given a small set of user information and a large set of comments, enrich the comments with user information data.
public static class ReplicatedJoinMapper extends
Mapper {
private static final Text EMPTY_TEXT = new Text("");
private HashMap userIdToInfo = new HashMap();
private Text outvalue = new Text();
private String joinType = null;
public void setup(Context context) throws IOException,
InterruptedException {
Path[] files =
DistributedCache.getLocalCacheFiles(context.getConfiguration());
// Read all files in the DistributedCache
for (Path p : files) {
BufferedReader rdr = new BufferedReader(
new InputStreamReader(
new GZIPInputStream(new FileInputStream(
new File(p.toString())))));
String line = null;
// For each record in the user file
while ((line = rdr.readLine()) != null) {
// Get the user ID for this record
Map parsed = transformXmlToMap(line);
String userId = parsed.get("Id");
// Map the user ID to the record
userIdToInfo.put(userId, line);
}
}
// Get the join type from the configuration
joinType = context.getConfiguration().get("join.type");
}
public void map(Object key, Text value, Context context)
throws IOException, InterruptedException {
Map parsed = transformXmlToMap(value.toString());
String userId = parsed.get("UserId");
String userInformation = userIdToInfo.get(userId);
// If the user information is not null, then output
if (userInformation != null) {
outvalue.set(userInformation);
context.write(value, outvalue);
} else if (joinType.equalsIgnoreCase("leftouter")) {
// If we are doing a left outer join,
// output the record with an empty value
context.write(value, EMPTY_TEXT);
}
}
} Composite Join
the data sets must first be sorted by foreign key, partitioned by foreign key,and read in a very particular manner in order to use this type of join.
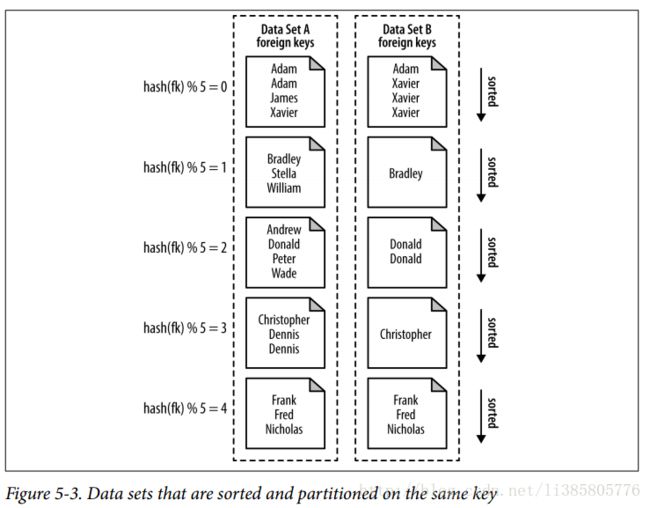
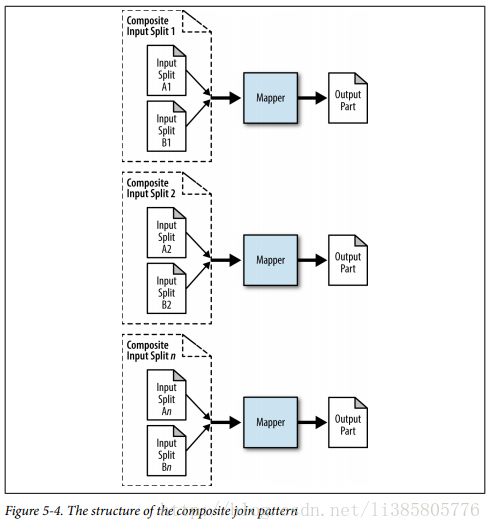
Problem: Given two large formatted data sets of user information and comments, enrich the comments with user information data.
Drive Code
public static void main(String[] args) throws Exception {
Path userPath = new Path(args[0]);
Path commentPath = new Path(args[1]);
Path outputDir = new Path(args[2]);
String joinType = args[3];
JobConf conf = new JobConf("CompositeJoin");
conf.setJarByClass(CompositeJoinDriver.class);
conf.setMapperClass(CompositeMapper.class);
conf.setNumReduceTasks(0);
// Set the input format class to a CompositeInputFormat class.
// The CompositeInputFormat will parse all of our input files and output
// records to our mapper.
conf.setInputFormat(CompositeInputFormat.class);
// The composite input format join expression will set how the records
// are going to be read in, and in what input format.
conf.set("mapred.join.expr", CompositeInputFormat.compose(joinType,
KeyValueTextInputFormat.class, userPath, commentPath));
TextOutputFormat.setOutputPath(conf, outputDir);
conf.setOutputKeyClass(Text.class);
conf.setOutputValueClass(Text.class);
RunningJob job = JobClient.runJob(conf);
while (!job.isComplete()) {
Thread.sleep(1000);
}
System.exit(job.isSuccessful() ? 0 : 1);
}Map Code
public static class CompositeMapper extends MapReduceBase implements
Mapper {
public void map(Text key, TupleWritable value,
OutputCollector output,
Reporter reporter) throws IOException {
// Get the first two elements in the tuple and output them
output.collect((Text) value.get(0), (Text) value.get(1));
}
} Cartesian Product
Most use cases for using a Cartesian product are some sort of similarity analysis on documents or media.
Applicability
Use a Cartesian product when:
• You want to analyze relationships between all pairs of individual records.
• You’ve exhausted all other means to solve this problem.
• You have no time constraints on execution time.
Use a Cartesian product when:
• You want to analyze relationships between all pairs of individual records.
• You’ve exhausted all other means to solve this problem.
• You have no time constraints on execution time.
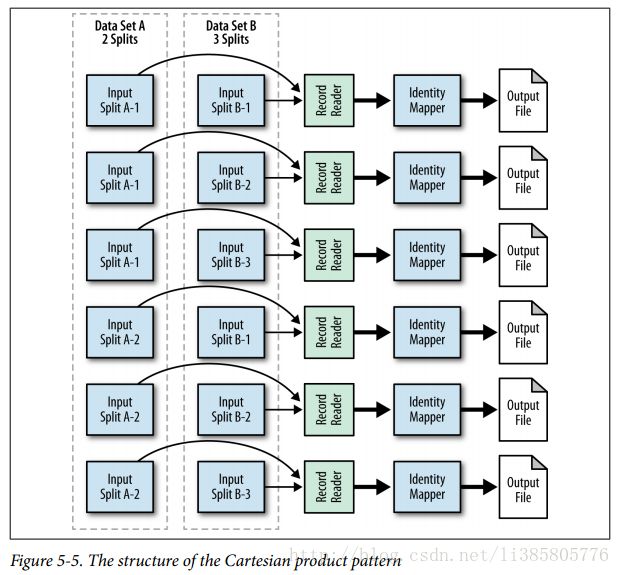
Problem: Given a groomed data set of StackOverflow comments, find pairs of comments that are similar based on the number of like words between each pair.
inputFormat会通过getSplits对数据进行划分,划分后的数据块(byte-oriented view)会转换为一个RecordReader对象(record-oriented view),遍历RecordReader,一条记录调用一个调用map
Input format code:
public static class CartesianInputFormat extends FileInputFormat {
public static final String LEFT_INPUT_FORMAT = "cart.left.inputformat";
public static final String LEFT_INPUT_PATH = "cart.left.path";
public static final String RIGHT_INPUT_FORMAT = "cart.right.inputformat";
public static final String RIGHT_INPUT_PATH = "cart.right.path";
public static void setLeftInputInfo(JobConf job,
Class inputFormat, String inputPath) {
job.set(LEFT_INPUT_FORMAT, inputFormat.getCanonicalName());
job.set(LEFT_INPUT_PATH, inputPath);
}
public static void setRightInputInfo(JobConf job,
Class inputFormat, String inputPath) {
job.set(RIGHT_INPUT_FORMAT, inputFormat.getCanonicalName());
job.set(RIGHT_INPUT_PATH, inputPath);
}
public InputSplit[] getSplits(JobConf conf, int numSplits)
throws IOException {
// Get the input splits from both the left and right data sets by LEFT_INPUT_FORMAT
InputSplit[] leftSplits = getInputSplits(conf,
conf.get(LEFT_INPUT_FORMAT), conf.get(LEFT_INPUT_PATH),
numSplits);
InputSplit[] rightSplits = getInputSplits(conf,
conf.get(RIGHT_INPUT_FORMAT), conf.get(RIGHT_INPUT_PATH),
numSplits);
// Create our CompositeInputSplits, size equal to
// left.length * right.length
CompositeInputSplit[] returnSplits =
new CompositeInputSplit[leftSplits.length *
rightSplits.length];
int i = 0;
// For each of the left input splits
for (InputSplit left : leftSplits) {
// For each of the right input splits
for (InputSplit right : rightSplits) {
// Create a new composite input split composing of the two
returnSplits[i] = new CompositeInputSplit(2);
returnSplits[i].add(left);
returnSplits[i].add(right);
++i;
}
}
// Return the composite splits
LOG.info("Total splits to process: " + returnSplits.length);
return returnSplits;
}
public RecordReader getRecordReader(InputSplit split, JobConf conf,
Reporter reporter) throws IOException {
// Create a new instance of the Cartesian record reader
return new CartesianRecordReader((CompositeInputSplit) split,
conf, reporter);
}
private InputSplit[] getInputSplits(JobConf conf,
String inputFormatClass, String inputPath, int numSplits)
throws ClassNotFoundException, IOException {
// Create a new instance of the input format
FileInputFormat inputFormat = (FileInputFormat) ReflectionUtils
.newInstance(Class.forName(inputFormatClass), conf);
// Set the input path for the left data set
inputFormat.setInputPaths(conf, inputPath);
//按照inputFormat的划分方法,将inputPath的文件划分成numSplits份
return inputFormat.getSplits(conf, numSplits);
}
}Drive Code:
public static void main(String[] args) throws IOException,
InterruptedException, ClassNotFoundException {
// Configure the join type
JobConf conf = new JobConf("Cartesian Product");
conf.setJarByClass(CartesianProduct.class);
conf.setMapperClass(CartesianMapper.class);
conf.setNumReduceTasks(0);
conf.setInputFormat(CartesianInputFormat.class);
// Configure the input format
CartesianInputFormat.setLeftInputInfo(conf, TextInputFormat.class, args[0]);
CartesianInputFormat.setRightInputInfo(conf, TextInputFormat.class, args[0]);
TextOutputFormat.setOutputPath(conf, new Path(args[1]));
conf.setOutputKeyClass(Text.class);
conf.setOutputValueClass(Text.class);
RunningJob job = JobClient.runJob(conf);
while (!job.isComplete()) {
Thread.sleep(1000);
}
System.exit(job.isSuccessful() ? 0 : 1);
}During task setup, getRecordReader is called by the framework to return the CartesianRecordReader. The constructor of this class creates two separate record reader objects, one for each split.
The first call to next reads the first record from the left data set for the mapper input key, and the first record from the right data set as the mapper input value. This key/value pair is then given to the mapper for processing by the framework.
Subsequent calls to next then continue to read all the records from the right record reader, allowing the mapper to process them, until it says it has no more. In this case, a flag is set and the do-while will loop backwards, reading the second record from the left data set. The right record reader is reset, and the process continues.
This process completes until the left record reader returns false, stating there are no more key/value pairs. At this point, the record reader has given the Cartesian product
of both input splits to the map task.
of both input splits to the map task.
public static class CartesianRecordReader implements
RecordReader {
// Record readers to get key value pairs
private RecordReader leftRR = null, rightRR = null;
// Store configuration to re-create the right record reader
private FileInputFormat rightFIF;
private JobConf rightConf;
private InputSplit rightIS;
private Reporter rightReporter;
// Helper variables
private K1 lkey;
private V1 lvalue;
private K2 rkey;
private V2 rvalue;
private boolean goToNextLeft = true, alldone = false;
public CartesianRecordReader(CompositeInputSplit split, JobConf conf,
Reporter reporter) throws IOException {
this.rightConf = conf;
this.rightIS = split.get(1);
this.rightReporter = reporter;
// Create left record reader
FileInputFormat leftFIF = (FileInputFormat) ReflectionUtils
.newInstance(Class.forName(conf
.get(CartesianInputFormat.LEFT_INPUT_FORMAT)), conf);
leftRR = leftFIF.getRecordReader(split.get(0), conf, reporter);
// Create right record reader
rightFIF = (FileInputFormat) ReflectionUtils.newInstance(Class
.forName(conf
.get(CartesianInputFormat.RIGHT_INPUT_FORMAT)), conf);
rightRR = rightFIF.getRecordReader(rightIS, rightConf, rightReporter);
// Create key value pairs for parsing
lkey = (K1) this.leftRR.createKey();
lvalue = (V1) this.leftRR.createValue();
rkey = (K2) this.rightRR.createKey();
rvalue = (V2) this.rightRR.createValue();
}
public boolean next(Text key, Text value) throws IOException {
do {
// If we are to go to the next left key/value pair
if (goToNextLeft) {
// Read the next key value pair, false means no more pairs
if (!leftRR.next(lkey, lvalue)) {
// If no more, then this task is nearly finished
alldone = true;
break;
} else {
// If we aren't done, set the value to the key and set
// our flags
key.set(lvalue.toString());
goToNextLeft = alldone = false;
// Reset the right record reader
this.rightRR = this.rightFIF.getRecordReader(
this.rightIS, this.rightConf,
this.rightReporter);
}
}
// Read the next key value pair from the right data set
if (rightRR.next(rkey, rvalue)) {
// If success, set the value
value.set(rvalue.toString());
} else {
// Otherwise, this right data set is complete
// and we should go to the next left pair
goToNextLeft = true;
}
// This loop will continue if we finished reading key/value
// pairs from the right data set
} while (goToNextLeft);
// Return true if a key/value pair was read, false otherwise
return !alldone;
}
} Map Code:
public static class CartesianMapper extends MapReduceBase implements
Mapper {
private Text outkey = new Text();
public void map(Text key, Text value,
OutputCollector output, Reporter reporter)
throws IOException {
// If the two comments are not equal
if (!key.toString().equals(value.toString())) {
String[] leftTokens = key.toString().split("\\s");
String[] rightTokens = value.toString().split("\\s");
HashSet leftSet = new HashSet(
Arrays.asList(leftTokens));
HashSet rightSet = new HashSet(
Arrays.asList(rightTokens));
int sameWordCount = 0;
StringBuilder words = new StringBuilder();
for (String s : leftSet) {
if (rightSet.contains(s)) {
words.append(s + ",");
++sameWordCount;
}
}
// If there are at least three words, output
if (sameWordCount > 2) {
outkey.set(words + "\t" + key);
output.collect(outkey, value);
}
}
}
}