Numpy教程
前言
参见:What is Numpy
Numpy是Python科学计算的基本包,它提供一个多维数组对象及各种派生对象(如屏蔽的数组和矩阵)以及一系列用于数组快速操作的例程,包括数学、逻辑、形状操作、排序、选择、I/O,离散傅里叶变换、线性代数、基本统计操作、随机模拟等等。
Numpy融合了C语言的高效性和Python的简单性:
- 像C一样快:逐个元素操作是numpy的默认模式,由预编译的C代码完成;
- 比Python更简单:Numpy的惯用语法比Python内置语法更简洁;
Numpy的以下两大特性,是它大部分功能的基础:
- 矢量化:在代码中没有任何显式循环、索引等。这些仅发生在优化的、预编译的C代码“幕后”,矢量化意味着代码更简洁、更不易犯错、更接近于数学符号、更高效;
- 广播:隐式的逐个元素操作。Numpy中所有操作都以这种隐式的逐个元素的方式进行,a和b甚至可以是具有不同形状的两个数组,较小的数组“可扩展为”较大的数组;
Numpy 有两种基本对象:
- ndarray (N-dimensional array object)多维数组:存储单一数据类型的多维数组
- ufunc (universal function object)通用函数:能够对数组进行处理的函数对象,大部分能够作用于数组的数学函数如三角函数等,都是 ufunc 对象
其他说明:
- numpy大多数时候都在处理一维和二维数组,多维数组可以由二维数组推而广之
- Numpy支持面向对象和面向过程两种编程方式,ndarray拥有众多属性和方法,它的许多方法都有对应的numpy函数,你可以选择你喜欢的方式来使用
# numpy的导入惯例
import numpy as npndarray对象
Numpy的核心是ndarray对象,它封装了同质数据类型的n维数组,与python序列有以下区别:
- ndarray在创建时有固定大小:不同于python中的列表,更改ndarray的大小将创建一个新的数组并删除原始数据
- ndarray中的元素有相同的数据类型
- ndarray便于对大量数据进行高级数学操作:通常会比python内置序列更高效也更简单
- 越来越多的基于python的科学和数学软件使用ndarray数组:只知道python的内置序列类型是不够的,还需要知道如何使用ndaray数组
ndarray数据类型
Numpy支持比Python更多种类的数值类型,参见:数据类型
| numpy数据类型 | python类型 | 描述 |
|---|---|---|
| bool_ | bool | 布尔(True或False),存储为一个字节 |
| int_ | int | 默认整数类型(与C long相同;通常为int64或int32) |
| intc | 与C int(通常为int32或int64)相同 | |
| intp | 用于索引的整数(与C ssize_t相同;通常为int32或int64) | |
| int8 | 字节(-128到127) | |
| int16 | 整数(-32768到32767) | |
| int32 | 整数(-2147483648至2147483647) | |
| int64 | 整数(-9223372036854775808至9223372036854775807) | |
| uint8 | 无符号整数(0到255) | |
| uint16 | 无符号整数(0到65535) | |
| uint32 | 无符号整数(0至4294967295) | |
| uint64 | 无符号整数(0至18446744073709551615) | |
| float_ | float | float64的简写。 |
| float16 | 半精度浮点:符号位,5位指数,10位尾数 | |
| float32 | 单精度浮点:符号位,8位指数,23位尾数 | |
| float64 | 双精度浮点:符号位,11位指数,52位尾数 | |
| complex_ | complex | complex128的简写。 |
| complex64 | 复数,由两个32位浮点(实数和虚数分量) | |
| complex128 | 复数,由两个64位浮点(实数和虚数分量) |
# 作为类型名称设置数组中元素的类型,为了向后兼容,也可以使用float或字符串'float'
x = np.array([1,2,3],dtype=np.float)
print x
# 查看数据类型
print x.dtype
# 作为单值类型转化函数
print np.int32(1.3)
# 转换数组的类型,会产生新的副本
print x.astype(np.int)结果:
[ 1. 2. 3.]
float64
1
[1 2 3]
创建数组ndarray
参见:创建数组
创建数组的机制:
- 从Python结构(例如,列表,元组)转换
- 从numpy原生数组创建(例如,arange、ones、zeros等)
- 使用特殊库函数(例如,random)
从Python列表/元组转换
np.array([1,2,3])结果:
array([1, 2, 3])
np.array((1,2,3))结果:
array([1, 2, 3])
np.array([[i,i+1,i+2] for i in range(3)])结果:
array([[0, 1, 2],
[1, 2, 3],
[2, 3, 4]])
从numpy原生数组创建
# 递增数组
print np.arange(start = 1,stop= 10,step=2,dtype = int)
print np.arange(10)[1 3 5 7 9]
[0 1 2 3 4 5 6 7 8 9]
# 指定元素数量的均匀递增数组
np.linspace(1.,10.,10)array([ 1., 2., 3., 4., 5., 6., 7., 8., 9., 10.])
np.indices((2,2))array([[[0, 0],
[1, 1]],
[[0, 1],
[0, 1]]])
# 全0矩阵
np.zeros(shape=(3,4),dtype=float)array([[ 0., 0., 0., 0.],
[ 0., 0., 0., 0.],
[ 0., 0., 0., 0.]])
# 返回具有与给定数组相同的形状和类型的零数组
np.zeros_like(a)array([[0, 0, 0, 0],
[0, 0, 0, 0],
[0, 0, 0, 0]])
# 全1矩阵
np.ones(shape=(3,4),dtype=float)array([[ 1., 1., 1., 1.],
[ 1., 1., 1., 1.],
[ 1., 1., 1., 1.]])
# 返回具有与给定数组相同的形状和类型的1数组
np.ones_like(a)array([[1, 1, 1, 1],
[1, 1, 1, 1],
[1, 1, 1, 1]])
# 返回具有与给定数组相同的形状和类型的新随机数组
np.empty_like(a)array([[-9223372036854775808, -9223372036854775808, 4564058118,
4563870896],
[ 4563410384, 4564092920, 0,
0],
[ 4538597360, -6917520233813358918, -9223372036854775808,
1688849860263936]])
# 对角矩阵
np.diag([1,2,3])array([[1, 0, 0],
[0, 2, 0],
[0, 0, 3]])
# 获取矩阵对角元素
np.diag([[1,2,3],
[4,5,6],
[7,8,9]])array([1, 5, 9])
# 获取矩阵偏移对角元素
np.diag([[1,2,3],
[4,5,6],
[7,8,9]],1)array([2, 6])
# 幂零矩阵
np.eye(3)array([[ 1., 0., 0.],
[ 0., 1., 0.],
[ 0., 0., 1.]])
np.eye(3,2)array([[ 1., 0.],
[ 0., 1.],
[ 0., 0.]])
np.eye(3,k=1)array([[ 0., 1., 0.],
[ 0., 0., 1.],
[ 0., 0., 0.]])
从随机函数创建
随机生成数组需要考虑的因素:
- 数据范围:区间,整数、小数
- 数据分布:均匀分布、正态分布、指定分布
- 数据形状:size
常用的随机函数
| 函数 | 解释 |
|---|---|
| rand(d0,d1,…) | [0,1]均匀分布 |
| randint(low,high,size) | [low,high)整数均匀分布 |
| choice(a,size,replace,p) | 指定数组指定概率分布 |
| randn(d0,d1,…) | 标准正态分布 |
[0,1]均匀分布
np.random.rand(3,4)array([[ 0.19806286, 0.76053071, 0.16911084, 0.08833981],
[ 0.68535982, 0.95339335, 0.00394827, 0.51219226],
[ 0.81262096, 0.61252607, 0.72175532, 0.29187607]])
[a,b)整数均匀分布
np.random.randint(2,size=(3,4))array([[1, 0, 0, 1],
[0, 0, 0, 1],
[1, 0, 0, 0]])
np.random.randint(0,2,(3,4))array([[1, 0, 1, 1],
[0, 1, 1, 0],
[1, 0, 0, 0]])
指定数组指定概率分布
np.random.choice([1,2,3,4],size=(3,4),replace=True,p=[0.1,0.2,0.3,0.4])array([[4, 3, 1, 3],
[2, 1, 2, 4],
[2, 2, 3, 2]])
np.random.choice(2,size=(3,4),replace=True,p=[0.3,0.7])array([[0, 1, 0, 1],
[1, 1, 0, 1],
[1, 1, 1, 0]])
N(0,1)标准正态分布
np.random.randn(3,4)array([[ 0.22863013, 0.44513761, -1.13660221, 0.13513688],
[ 1.484537 , -1.07980489, -1.97772828, -1.7433723 ],
[ 0.26607016, 2.38496733, 1.12369125, 1.67262221]])
设置随机数种子
# 设置随机种子数,复现随机过程
np.random.seed(10)
print np.random.rand(3)
print np.random.rand(3)
np.random.seed(10)
print np.random.rand(3)
print np.random.rand(3)[ 0.77132064 0.02075195 0.63364823]
[ 0.74880388 0.49850701 0.22479665]
[ 0.77132064 0.02075195 0.63364823]
[ 0.74880388 0.49850701 0.22479665]
ndarray的属性和方法
a = np.random.randint(3,size=(3,4))
aarray([[2, 1, 1, 0],
[2, 2, 1, 0],
[0, 0, 2, 2]])
ndarray属性
# 数据类型
a.dtypedtype('int64')
# 维数
a.ndim2
# 形状
a.shape(3, 4)
# 元素总数
a.size12
# 每个元素字节大小
a.itemsize8
ndarray方法
# 更改数据类型,返回新数组
a.astype(float)array([[ 2., 2., 2., 0.],
[ 0., 2., 2., 1.],
[ 2., 1., 2., 1.]])
# 更改形状,返回新数组
print a.reshape((2,6))
# 如果在reshape操作中将维度指定为-1,则会自动计算其他维度:
print a.reshape((3,-1))
# 原地修改原数组的形状
print a.resize((2,6))
[[0 4 6 3 5 9]
[3 8 3 0 9 6]]
[[0 4 6 3]
[5 9 3 8]
[3 0 9 6]]
None
# 阵列展开为向量 'C', 'F', 'A', or 'K'
print a.ravel('A')
print a.ravel('C')
print a.ravel('F')
print a.ravel('K')[2 1 1 0 2 2 1 0 0 0 2 2]
[2 1 1 0 2 2 1 0 0 0 2 2]
[2 2 0 1 2 0 1 1 2 0 0 2]
[2 1 1 0 2 2 1 0 0 0 2 2]
ndarray索引
索引是指使用方括号([])对数组值进行索引,有很多选项来索引,这使numpy索引很强大,但功能上的强大也带来一些复杂性和潜在的混乱,参见:索引。
索引的一般格式如下:
a[i,[j,k,l],[True,False,…],m:n:s]
索引的规则如下:
- 数组不同轴的索引以”,”隔开,当某轴省略时表示保留该轴上的所有元素:
- 后面的轴可以省略,等价于:,但前面的轴不可省略,但可用:保留该轴所有元素
...表示省略剩余所有连续的轴,只能用一次(多次会出现歧义)
- 单轴索引可有四种形式:
- 单索引
a[i]:选取数组a中索引为i的元素
- 结果会降一维
- 规则同python列表索引(可为负,但不能超出数组范围)
- 数组索引
a[np.array([j, k, l])]:选取数组a中索引为j, k, l的元素组成的数组
- 结果中元素按数组索引排布,维数增加=数组索引维数-1
- j,k,l可重复使用,但均是同一元素的引用
- python列表可自动转化为数组,所以一般使用
a[[j,k,l]]简化版; - python元组不能自动转化为数组,
a[(j,k,l)]等价于a[j,k,l]; - 每个索引规则同python列表索引,数组索引是numpy特有的,python列表无对应索引方法
- 布尔索引
a[[True,False,...]]:布尔索引实质是一种按条件筛选的特殊数组索引
- 结果维度不变
- 布尔索引长度必须等于该轴长度,等价于保留True所对应的索引的简单数组索引
- 切片
a[m:n:s]:选取数组a中以m开始,步长为s,n之前的元素组成的数组
- 结果维数不变
- 规则同python列表切片
- 单索引
- 多轴索引可转化为分步单轴索引:
a[i,?]等价于a[:,?][i]:可看做是一个截面与其他轴截面的交点所组成的数组,每个索引轴都会导致结果维度降1a[[i,j],[k,l]]等价于[a[i,k],a[j,l]]:不同轴的数组索引必须等长,会通过zip()配对,配对导致结果维数降1a[m:n,?]等价于a[:,?][m:n]:多截面与多截面交点组成的新数组,维数不变- 布尔索引:布尔索引不仅可用于作为单轴的数组索引,还可以与数组有相同形状,返回Ture所在的所有元素,结果为一维数组
说明:单个索引和索引序列配对的结果会发生降维,每个单索引都会使结果降1维,所有索引序列配整体上对会使结果降一维;
a = np.random.randint(3,size=(3,4))
aarray([[1, 1, 2, 1],
[0, 2, 0, 1],
[2, 0, 0, 0]])
一维
单索引
# 索引,降1维
print a[1],'\n'
# 负数索引
print a[-2],'\n'[0 2 0 1]
[0 2 0 1]
数组索引
# 数组索引,不降维
print a[np.array([1,2])],'\n'
# list会自动转化为数组
print a[[1,2]],'\n'
# tuple不会转化为数组
print a[(1,2)],'\n'
# 允许索引重复
print a[np.array([1,1,2])],'\n'
# 结果按数组索引形状
a[np.array([[1,1],[2,2]])][[0 2 0 1]
[2 0 0 0]]
[[0 2 0 1]
[2 0 0 0]]
0
[[0 2 0 1]
[0 2 0 1]
[2 0 0 0]]
array([[[0, 2, 0, 1],
[0, 2, 0, 1]],
[[2, 0, 0, 0],
[2, 0, 0, 0]]])
布尔索引
# 布尔索引
a[[True,False,False]]array([[1, 1, 2, 1]])
切片
# 切片
a[:-1]array([[1, 1, 2, 1],
[0, 2, 0, 1]])
二维
aarray([[1, 1, 2, 1],
[0, 2, 0, 1],
[2, 0, 0, 0]])
单索引与其他
# 索引与其他
# 虽然结果上等价于a[0][1],但是这种方式会产生临时数组,更加低效
a[0,1]1
a[0,[0,1]]array([1, 1])
a[0,[True,False,False,True]]array([1, 1])
a[0,:]array([1, 1, 2, 1])
数组索引配对
# 数组索引的配对
print a[[1,2],[1,2]],'\n'
print a[np.array([[1,2],[1,2]]),
np.array([[0,1],[0,1]])][2 0]
[[0 0]
[0 0]]
a[[1,2],[False,True,True,False]]array([2, 0])
切片与切片/数组索引
# 切片与切片/序列索引
a[[1,2],1:]array([[2, 0, 1],
[0, 0, 0]])
a[1:,a[1]>0]array([[2, 1],
[0, 0]])
z = np.arange(81).reshape(3,3,3,3)
z[1,...,2]array([[29, 32, 35],
[38, 41, 44],
[47, 50, 53]])
整体布尔索引
# 整体布尔索引
z[z>70]array([71, 72, 73, 74, 75, 76, 77, 78, 79, 80])
结构化索引工具
可以在数组索引中使用np.newaxis对象来添加大小为1的新维
x=np.arange(3)
print x,x.shape
# 等价于x.reshap(-1,1)
y = x[:,np.newaxis]
print y,y.shape[0 1 2] (3,)
[[0]
[1]
[2]] (3, 1)
索引变量
当你想要写一个可以处理不同维度参数的函数时,可以使向数组索引传递一个元组。
a = np.arange(12).reshape(3,4)
indices = (1,slice(0,2))
print a[indices],'\n'[4 5]
索引赋值
与python列表类似,将一个数组赋值给一个变量只是使该变量引用了该数组;而对数组的索引进行赋值,则是对该数组进行原地修改。
- 索引赋值的前提——可广播:等号右侧的数组能够广播到等号左侧被赋值的索引数组;
- 索引赋值的过程——原地修改:等号右侧的数组首先广播到等号左侧被复制的数组,然后原地覆盖索引数组中的数据;
- 重复数组索引的赋值——最后一次生效:重复数组索引中重复元素引用的是同一元素,对带元素的多次赋值只有最后一次会覆盖掉前面的赋值;
- 注意——视图/副本:切片只是产生原数组的新视图,不会复制原数组中的数据;而索引、数组索引、布尔索引则会产生原数组的新副本;如果有另外的变量引用了索引结果,只有该变量引用的是切片的时候,对该变量的原地修改会影响到原数组,否则修改的只是新副本,不会影响到原数组
切片产生视图,索引产生副本
x = np.arange(12).reshape(3,4)
xarray([[ 0, 1, 2, 3],
[ 4, 5, 6, 7],
[ 8, 9, 10, 11]])
# 索引产生副本
y = x[0,[0,1,2,3]]
y[[0,1,2]] = 99
xarray([[ 0, 1, 2, 3],
[ 4, 5, 6, 7],
[ 8, 9, 10, 11]])
# 切片产生视图
y = x[0,:]
y[[0,1,2]] = 99
xarray([[99, 99, 99, 3],
[ 4, 5, 6, 7],
[ 8, 9, 10, 11]])
索引赋值为原地修改
x = np.arange(12).reshape(3,4)
x[[0,1],[True,False,True,False]] = 99
xarray([[99, 1, 2, 3],
[ 4, 5, 99, 7],
[ 8, 9, 10, 11]])
赋值数组可广播到索引数组
x[:]=np.array([9,9,9,9])
xarray([[9, 9, 9, 9],
[9, 9, 9, 9],
[9, 9, 9, 9]])
重复数组索引的赋值
x = np.array([1,2,3,4])
xarray([1, 2, 3, 4])
y = x[np.array([[1,1],[2,2]])]
yarray([[2, 2],
[3, 3]])
y[0]=111
xarray([1, 2, 3, 4])
# 最后一次赋值生效
x[np.array([[1,1],[2,2]])] = np.array([[10,20],[30,40]])
xarray([ 1, 20, 40, 4])
# 最后一次赋值生效
x[[1,1,3,1]] +=1
xarray([ 1, 21, 40, 5])
数组堆叠
几个数组可以沿不同的轴堆叠在一起:
# 列向拼接
a = np.floor(10*np.random.random((2,2)))
b = np.floor(10*np.random.random((2,2)))
np.hstack((a,b))array([[ 7., 4., 3., 0.],
[ 4., 1., 7., 0.]])
# 行向拼接
np.vstack((a,b))array([[ 7., 4.],
[ 4., 1.],
[ 3., 0.],
[ 7., 0.]])
# 沿其水平轴拆分数组,通过指定要返回的均匀划分的数组数量,或通过指定要在其后进行划分的列
np.hsplit(a,2)[array([[ 7.],
[ 4.]]), array([[ 4.],
[ 1.]])]
ufunc对象
参见:速入门教程
大部分能够作用于数组的数学函数如数组的基本运算、三角函数等,都是 ufunc 对象。
numpy函数
all, any, apply_along_axis, argmax, argmin, argsort, average, bincount, ceil, clip, conj, corrcoef, cov, cross, cumprod, cumsum, diff, dot, floor, inner, inv, lexsort, max, maximum, mean, median, min, minimum, nonzero, outer, prod, re, round, sort, std, sum, trace, transpose, var, vdot, vectorize, where
| 函数 | 说明 | 用法 |
|---|---|---|
| all | 测试沿给定轴的所有数组元素是否为True | np.all(a,axis=1) |
| any | 测试沿给定轴的任何数组元素是否为True | np.any(a,axis=1) |
| apply_along_axis | 沿着给定轴向1-D切片应用函数 | np.apply_along_axis(func,axis,arr) |
| argmax | 返回最大数的索引 | numpy.argmax(a, axis=None, out=None) |
| argsort | 返回排序后的索引 | argsort(a, axis=-1, kind=’quicksort’, order=None)[source] |
| average | 计算加权平均 | average(a, axis=None, weights=None, returned=False) |
| bincount | 计算非负整数数组中每个值出现的次数 | bincount(x, weights=None, minlength=None) |
| ceil | 元素向上取整 | ceil(x[, out]) = |
a = np.random.randint(10,size=(3,4))
aarray([[0, 4, 6, 3],
[5, 9, 3, 8],
[3, 0, 9, 6]])
# 是否所有都为True
np.all(a,axis=0)array([False, False, True, True], dtype=bool)
# 是否含True
np.any(a)True
# 沿着某轴应用函数
np.apply_along_axis(lambda x: sum(x),axis=0,arr=a)array([ 8, 13, 18, 17])
# 返回最大值的索引
print np.argmax(a)
print np.argmin(a)
print np.argmax(a,axis=1)5
0
[2 1 2]
# 向上取整
np.ceil(a)array([[ 0., 4., 6., 3.],
[ 5., 9., 3., 8.],
[ 3., 0., 9., 6.]])
# 向下取整
np.floor(a)array([[ 0., 4., 6., 3.],
[ 5., 9., 3., 8.],
[ 3., 0., 9., 6.]])
# 限制数组中的值
np.clip(a,[3,4,5,6],8)array([[3, 4, 6, 6],
[5, 8, 5, 8],
[3, 4, 8, 6]])
# 如果给定x和y且输入数组是1-D,where等效于:
# [xv if c else yv for (c,xv,yv) in zip(condition,x,y)]
np.where([[True, False],
[True, True]],
[[1, 2],
[3, 4]],
[[9, 8],
[7, 6]])array([[1, 8],
[3, 4]])
运算
参考:ufunc运算
Numpy操作(包括算术、比较、逻辑、位运算等,这些运算都是通过Numpy提供的标准ufunc函数实现的)通常由成对的阵列(可广播的)完成,阵列间逐个元素对元素地执行运算,结果阵列的尺寸为广播后的尺寸。
算术运算

比较运算
使用“==”、“>”等比较运算符比较两个数组,将返回一个布尔数组,它的每个元素的值是两个数组对应元素比较的结果。

逻辑运算
由于Python的布尔运算使用and,or和Not等关键字,无法被重载,因此数组的布尔运算智能通过ufunc对应的函数来操作,这些函数以logical_开头,如下:
| 逻辑函数 | 逻辑 |
|---|---|
| logic_and | 与 |
| logic_or | 或 |
| logic_xor | 异或 |
| logic_not | 否 |
位运算
以bitwise_开头的函数是比特运算函数,包括bitwise_and、bitwise_not、bitwise_or和bitwise_xor等,也可以使用&、~、|、^等操作符来计算。
广播机制(Broadcasting)
参考:Python库numpy中的Broadcasting机制解析
广播用以描述numpy中对两个形状不同的阵列进行数学计算的处理机制:较小的阵列“广播”到较大阵列相同的形状尺度上,使它们对等以可以进行数学计算。广播提供了一种向量化阵列的操作方式,因此Python不需要像C一样循环。广播操作不需要数据复制,通常执行效率非常高。然而,有时广播是个坏主意,可能会导致内存浪费以致计算减慢。
Numpy操作通常由成对的阵列完成,阵列间逐个元素对元素地执行,最简单情形是两个阵列有相同的形状,Numpy的广播机制放宽了对阵列形状的限制:
- 广播前提:当对两个阵列进行操作时,Numpy会从后向前逐维地比较二者在该维上的长度,当两个阵列在每个维度上均满足以下条件时,二者是兼容的,否则将会抛出异常
frames are not aligned exception:
- 它们的长度相等
- 其中一个长度1(为空则默认视作1)
广播过程:尺寸为1的维度会自动“复制”该维度上的值以扩展到与另一个维度匹配。(实际上,复制仅是概念上的,Numpy并不需要真的复制原始数据,所以广播计算在内存和效率上都很高效)
广播结果:结果阵列的各维尺寸与输入阵列的各维度最大尺寸相同
最简单的情形是一个阵列和一个值进行运算
A (2d array): 5 x 4
B (1d array): 1
Result (2d array): 5 x 4
A (2d array): 5 x 4
B (1d array): 4
Result (2d array): 5 x 4
A (4d array): 8 x 1 x 6 x 1
B (3d array): 7 x 1 x 5
Result (4d array): 8 x 7 x 6 x 5
A (3d array): 15 x 3 x 5
B (3d array): 15 x 1 x 5
Result (3d array): 15 x 3 x 5
A (3d array): 15 x 3 x 5
B (2d array): 3 x 5
Result (3d array): 15 x 3 x 5
A (3d array): 15 x 3 x 5
B (2d array): 3 x 1
Result (3d array): 15 x 3 x 5
如果你有一个256x256x3的RGB阵列,你想要对每一种颜色加一个权重,你就可以乘以一个拥有3个元素的一维阵列
Image (3d array): 256 x 256 x 3
Scale (1d array): 3
Result (3d array): 256 x 256 x 3# 广播提供了一种计算外积(或者任何外部运算)的便捷的方式
a = np.array([0.0, 10.0, 20.0, 30.0]).reshape(-1,1)
b = np.array([1.0, 2.0, 3.0])
print a.shape,b.shape
a + b (4, 1) (3,)
array([[ 1., 2., 3.],
[ 11., 12., 13.],
[ 21., 22., 23.],
[ 31., 32., 33.]])
ufunc对象的方法
dir(np.add)['__call__',
'__class__',
'__delattr__',
'__doc__',
'__format__',
'__getattribute__',
'__hash__',
'__init__',
'__name__',
'__new__',
'__reduce__',
'__reduce_ex__',
'__repr__',
'__setattr__',
'__sizeof__',
'__str__',
'__subclasshook__',
'accumulate',
'at',
'identity',
'nargs',
'nin',
'nout',
'ntypes',
'outer',
'reduce',
'reduceat',
'signature',
'types']
特别地,对于二元操作符所对应的 ufunc 对象,支持以下方法:
reduce方法
op.reduce(a):沿着某个轴应用op,使得数组 a 的维数降低一维
x = np.array([[1,2,3],[4,5,6]])
np.add.reduce(x,1)array([ 6, 15])
a = np.array(['ab', 'cd', 'ef'], np.object)
np.add.reduce(a)'abcdef'
a = np.array([1,1,0,1])
np.logical_and.reduce(a)False
accumulate 方法
op.accumulate(a):accumulate 可以看成保存 reduce 每一步的结果所形成的数组
a = np.array(['ab', 'cd', 'ef'], np.object)
np.add.accumulate(a)array(['ab', 'abcd', 'abcdef'], dtype=object)
reduceat 方法
op.reduceat(a, indices):reduceat 方法将操作符运用到指定的下标上,返回一个与 indices 大小相同的数组
a = np.array([10, 10, 20, 30, 40, 50])
indices = np.array([1,4])
# indices 为 [1, 4],所以 60 表示从下标1(包括)加到下标4(不包括)的结果,90 表示从下标4(包括)加到结尾的结果
np.add.reduceat(a, indices)array([60, 90])
outer方法
op.outer(a, b):对于 a 中每个元素,将 op 运用到它和 b 的每一个元素上所得到的结果
a = np.array([0,1])
b = np.array([1,2,3])
np.add.outer(a, b)array([[1, 2, 3],
[2, 3, 4]])
自定义ufunc函数
参考:ufunc运算
ufunc是universal function的缩写,它是一种能对数组中每个元素进行操作的函数。Numpy内置的许多ufunc函数都是C语言实现的,计算速度非常快。
通过Numpy提供的标准ufunc函数可以满足大多要求,但有些特殊情况需要自定义函数来实现。这时,可以采用python函数来实现,然后使用frompyfunc( )函数将一个计算单个元素的函数转换为ufunc函数
frompyfunc(func,nin,nout)
原型:frompyfunc(func,nin,nout)
参数:
- func:计算单个元素的函数
- nin:输入参数的个数
- nout:func返回值的个数
返回:自定义ufunc函数
实例
例如,用一个分段函数来描述三角波,它的样子如图所示:
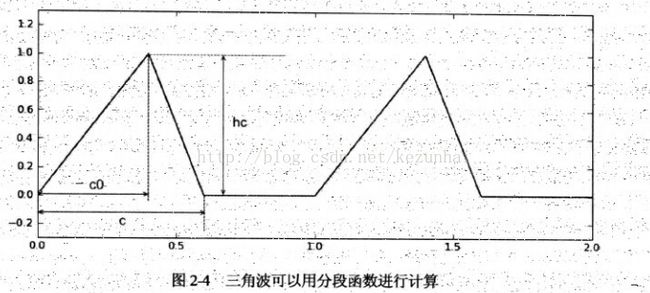
def triangle_wave(x,c,c0,hc):
x = x - int(x) #周期为1,取小数部分计算
if x>=c:
r = 0.0
elif xelse:
r = (c-x)/(c-c0)*hc
return r
triangle_wave_ufunc = np.frompyfunc(triangle_wave,4,1)
x = np.arange(10)/10.
y2 = triangle_wave_ufunc(x,0.6,0.4,1.0)
# 自定义的ufunc返回数组的元素类型是object,因此还需要调用类型转换函数
y2.astype(float) array([ 0. , 0.25, 0.5 , 0.75, 1. , 0.5 , 0. , 0. , 0. , 0. ])
y2.dtypedtype('O')
导入导出
a = np.loadtxt('./test_io.csv',
dtype=float,delimiter=',',comments='#',
skiprows=1,usecols=[0,1],converters = {0: lambda x:int(x)})
aarray([[ 1., 2.],
[ 4., 5.],
[ 5., 5.]])
a = np.loadtxt('./test_io.txt',
dtype=float,delimiter=',',comments='#',
skiprows=1,usecols=[0,1],converters = {0: lambda x:int(x)})
aarray([[ 5., 6.],
[ 9., 10.]])
def myfunc(a,b):
if (a>b): return a
else: return b
vecfunc = np.vectorize(myfunc)
result=vecfunc([[1,2,3],[5,6,9]],[7,4,5])
print(result)[[7 4 5]
[7 6 9]]