Python中的scikit-learn机器学习功能库
在真格量化提供的多个机器学习库中包括scikit-learn,其也简称 sklearn, 是机器学习领域当中最知名的 Python库之一。

在介绍scikit-learn之前,我们将介绍一些机器学习的基本概念。
机器学习:问题设置
一般来说,一个学习问题通常会考虑已知的一系列的 n 个 样本(比如一个品种的历史价格数据) 数据,然后尝试预测未知数据的属性。如果每个样本是多个属性的数据 (比如说是一个多维记录),就说它有许多“属性”,或称 features(特征) 。
我们可以将学习问题分为几大类:
监督学习 , 其中数据带有一个附加属性,即我们想要预测的结果值。这个问题可以是:
分类 : 样本属于两个或更多个类,我们想从已经标记的数据中学习如何预测未标记数据的类别。分类问题的一个简单例子是手写数字识别,其目的是将每个输入向量分配给有限数目的离散类别之一。我们通常把分类视作监督学习的一个离散形式(区别于连续形式),从有限的类别中,给每个样本贴上正确的标签。
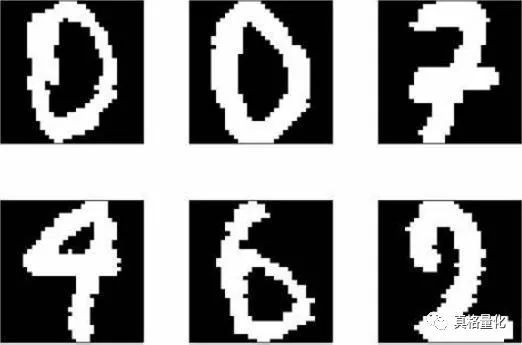
回归 : 如果期望的输出由一个或多个连续变量组成,则该任务称为“回归” 。回归问题的一个简单例子是预测贵金属价格和央行利率的关系的函数形式。

无监督学习, 其中训练数据由没有任何相应目标值的一组输入向量x组成。这种问题的目标可能是在数据中发现彼此类似的示例所聚成的组,这种问题称为 “聚类” , 或者,确定输入空间内的数据分布,称为 “密度估计” ,又或从高维数据投影数据空间缩小到二维或三维以进行 可视化 。
训练集和测试集
机器学习是从数据的属性中学习,并将它们应用到新数据的过程。这就是为什么机器学习中评估算法的普遍实践是把数据分割成 训练集 (我们从中学习数据的属性)和 测试集 (我们测试这些性质)。
下边介绍一些sklearn的基本功能:
1.1 估计器(Estimator)
估计器,很多时候可以直接理解成分类器,主要包含两个函数:
-
fit():训练算法,设置内部参数。接收训练集和类别两个参数。
-
predict():预测测试集类别,参数为测试集。
大多数scikit-learn估计器接收和输出的数据格式均为numpy数组或类似格式。
1.2 转换器(Transformer)
转换器用于数据预处理和数据转换,主要是三个方法:
-
fit():训练算法,设置内部参数。
-
transform():数据转换。
-
fit_transform():合并fit和transform两个方法。
1.3 流水线(Pipeline)
sklearn.pipeline包流水线的功能:
-
跟踪记录各步骤的操作(以方便地重现实验结果)
-
对各步骤进行一个封装
-
确保代码的复杂程度不至于超出掌控范围
基本使用方法
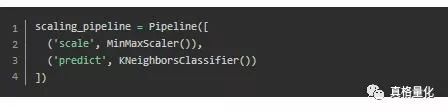
流水线的输入为一连串的数据挖掘步骤,其中最后一步必须是估计器,前几步是转换器。输入的数据集经过转换器的处理后,输出的结果作为下一步的输入。最后,用位于流水线最后一步的估计器对数据进行分类。
每一步都用元组( ‘名称’,步骤)来表示。现在来创建流水线。
1.4 预处理
主要在sklearn.preprcessing包下。
规范化:
-
MinMaxScaler :最大最小值规范化
-
Normalizer :使每条数据各特征值的和为1
-
StandardScaler :为使各特征的均值为0,方差为1
编码:
-
LabelEncoder :把字符串类型的数据转化为整型
-
OneHotEncoder :特征用一个二进制数字来表示
-
Binarizer :为将数值型特征的二值化
-
MultiLabelBinarizer:多标签二值化
1.5 特征
1.5.1 特征抽取
包:sklearn.feature_extraction
特征抽取是数据挖掘任务最为重要的一个环节,一般而言,它对最终结果的影响要高过数据挖掘算法本身。只有先把现实用特征表示出来,才能借助数据挖掘的力量找到问题的答案。特征选择的另一个优点在于:降低真实世界的复杂度,模型比现实更容易操纵。
一般最常使用的特征抽取技术都是高度针对具体领域的,对于特定的领域,如图像处理,文本分析等,在过去一段时间已经开发了各种特征抽取的技术,但这些技术直接用到其他领域的效果就非常有限。
特征选择的原因如下:
(1)降低复杂度
(2)降低噪音
(3)增加模型可读性
-
DictVectorizer:将dict类型的list数据,转换成numpy array
-
FeatureHasher :特征哈希,相当于一种降维技巧
-
image:图像相关的特征抽取
-
text:文本相关的特征抽取
-
text.CountVectorizer:将文本转换为每个词出现的个数的向量
-
text.TfidfVectorizer:将文本转换为tfidf值的向量
-
text.HashingVectorizer:文本的特征哈希
1.5.2 特征选择
包:sklearn.feature_selection
特征选择的原因如下:
(1)降低复杂度
(2)降低噪音
(3)增加模型可读性

-
VarianceThreshold:删除特征值的方差达不到最低标准的特征
-
SelectKBest:返回k个最佳特征
-
SelectPercentile:返回表现最佳的前r%个特征
单个特征和某一类别之间相关性的计算方法有很多。最常用的有卡方检验(χ2)。其他方法还有互信息和信息熵。
chi2:卡方检验(χ2)
1.6 降维
包:sklearn.decomposition
主成分分析算法(Principal Component Analysis, PCA)的目的是找到能用较少信息描述数据集的特征组合。它意在发现彼此之间没有相关性、能够描述数据集的特征,确切说这些特征的方差跟整体方差没有多大差距,这样的特征也被称为主成分。这也就意味着,借助这种方法,就能通过更少的特征捕获到数据集的大部分信息。
1.7 组合
包:sklearn.ensemble
组合技术即通过聚集多个分类器的预测来提高分类准确率。
常用的组合分类器方法:
(1)通过处理训练数据集。即通过某种抽样分布,对原始数据进行再抽样,得到多个训练集。常用的方法有装袋(bagging)和提升(boosting)。
(2)通过处理输入特征。即通过选择输入特征的子集形成每个训练集。适用于有大量冗余特征的数据集。随机森林(Random forest)就是一种处理输入特征的组合方法。
(3)通过处理类标号。适用于多分类的情况,将类标号随机划分成两个不相交的子集,再把问题变为二分类问题,重复构建多次模型,进行分类投票。
-
BaggingClassifier:Bagging分类器组合
-
BaggingRegressor:Bagging回归器组合
-
AdaBoostClassifier:AdaBoost分类器组合
-
AdaBoostRegressor:AdaBoost回归器组合
-
GradientBoostingClassifier:GradientBoosting分类器组合
-
GradientBoostingRegressor:GradientBoosting回归器组合
-
ExtraTreeClassifier:ExtraTree分类器组合
-
ExtraTreeRegressor:ExtraTree回归器组合
-
RandomTreeClassifier:随机森林分类器组合
-
RandomTreeRegressor:随机森林回归器组合
例子:

解释
装袋(bagging):根据均匀概率分布从数据集中重复抽样(有放回),每个自助样本集和原数据集一样大,每个自助样本集含有原数据集大约63%的数据。训练k个分类器,测试样本被指派到得票最高的类。
提升(boosting):通过给样本设置不同的权值,每轮迭代调整权值。不同的提升算法之间的差别,一般是(1)如何更新样本的权值,(2)如何组合每个分类器的预测。其中Adaboost中,样本权值是增加那些被错误分类的样本的权值,分类器C_i的重要性依赖于它的错误率。Boosting主要关注降低偏差,因此Boosting能基于泛化性能相当弱的学习器构建出很强的集成;Bagging主要关注降低方差,因此它在不剪枝的决策树、神经网络等学习器上效用更为明显。偏差指的是算法的期望预测与真实预测之间的偏差程度,反应了模型本身的拟合能力;方差度量了同等大小的训练集的变动导致学习性能的变化,刻画了数据扰动所导致的影响。
1.8 模型评估(度量)
包:sklearn.metrics
sklearn.metrics包含评分方法、性能度量、成对度量和距离计算。
分类结果度量
参数大多是y_true和y_pred。
-
accuracy_score:分类准确度
-
condusion_matrix :分类混淆矩阵
-
classification_report:分类报告
-
precision_recall_fscore_support:计算精确度、召回率、f、支持率
-
jaccard_similarity_score:计算jcaard相似度
-
hamming_loss:计算汉明损失
-
zero_one_loss:0-1损失
-
hinge_loss:计算hinge损失
-
log_loss:计算log损失
其中,F1是以每个类别为基础进行定义的,包括两个概念:准确率(precision)和召回率(recall)。准确率是指预测结果属于某一类的个体,实际属于该类的比例。召回率是被正确预测为某类的个体,与数据集中该类个体总数的比例。F1是准确率和召回率的调和平均数。
回归结果度量
explained_varicance_score:可解释方差的回归评分函数
mean_absolute_error:平均绝对误差
mean_squared_error:平均平方误差
多标签的度量
coverage_error:涵盖误差
label_ranking_average_precision_score:计算基于排名的平均误差Label ranking average precision (LRAP)
聚类的度量
adjusted_mutual_info_score:调整的互信息评分
silhouette_score:所有样本的轮廓系数的平均值
silhouette_sample:所有样本的轮廓系数
scikit-learn更多的功能,用户可以参照其文档继续探索。
— — — — — — E N D — — — — — —
真格量化可访问:
https://quant.pobo.net.cn

真格量化微信公众号,长按关注:

遇到了技术问题?欢迎加入真格量化Python技术交流QQ群 726895887

往期文章:
Numpy处理tick级别数据技巧
真正赚钱的期权策略曲线是这样的
多品种历史波动率计算
如何实现全市场自动盯盘
AI是怎样看懂研报的
真格量化策略debug秘籍
真格量化对接实盘交易
常见高频交易策略简介
如何用撤单函数改进套利成交
Deque提高处理队列效率
策略编程选Python还是C++
如何用Python继承机制节约代码量
十大机器学习算法
如何调用策略附件数据
如何使用智能单
如何扫描全市场跨月价差
如何筛选策略最适合的品种
活用订单类型规避频繁撤单风险
真格量化回测撮合机制简介
如何调用外部数据
如何处理回测与实盘差别
如何利用趋势必然终结获利
常见量化策略介绍
期权交易“七宗罪”
波动率交易介绍
推高波动率的因素
波动率的预测之道
趋势交易面临挑战
如何构建知识图谱
机器学习就是现代统计学
AI技术在金融行业的应用
如何避免模型过拟合
低延迟交易介绍
架构设计中的编程范式
交易所视角下的套利指令撮合
距离概念与特征识别
气象风险与天气衍生品
设计量化策略的七个“大坑”
云计算在金融行业的应用
机器学习模型评估方法
真格量化制作期权HV-IV价差
另类数据介绍
TensorFlow中的Tensor是什么?
机器学习的经验之谈
用yfinance调用雅虎财经数据
容器技术如何改进交易系统
Python调用C++
如何选择数据库代理
统计套利揭秘
一个Call搅动市场?让我们温习一下波动率策略
如何用真格量化设计持仓排名跟踪策略
还不理解真格量化API设计?我们不妨参考一下CTP平台
理解同步、异步、阻塞与非阻塞
隐波相关系数和偏度——高维风险的守望者
Delta中性还不够?——看看如何设计Gamma中性期权策略
Python的多线程和多进程——从一个爬虫任务谈起
线程与进程的区别
皮尔逊相关系数与历史K线匹配
Python2和Python3的兼容写法
Python代码优化技巧
理解Python的上下文管理器
如何写出更好的Python代码?这是Python软件基金会的建议
评估程序化模型时我们容易忽视的指标
看看如何定位Python程序性能瓶颈
什么是Python的GIL
投资研究中的大数据分析趋势及应用
理解CTP中的回调函数
如何围绕隐含波动率设计期权交易策略
看看如何用Python进行英文文本的情感分析
算法交易的分类
Python编码的最佳实践总结
什么是波动率锥?如何用波动率锥设计期权策略?
期权的波动率策略与时间价值收集策略对比
期权用于套期保值和无风险套利
隐含波动率对期权策略的影响
卖出期权交易的风险管理原则和技巧
期权交易中的“大头针”风险
期权做市商策略简介
精细化您的交易——交易成本评估与交易执行策略
海外市场交易执行策略的实践
设计期权套期保值方案时应注意的问题
美式期权、欧式期权比较分析——定价与风险管理
构建您的AI时代武器库——常用的机器学习相关Python库
期权波动率“微笑曲线”之谜
运算任务愈发繁重,如何加速Python程序运行?
证券市场微观结构理论模型是什么
是瞬间成交还是漫长等待?——如何衡量市场流动性
波动率指数及其衍生品介绍
Python的异常处理技巧
Python中的阻塞、异步与协程
"香草"之外的更多选择——几种常见的路径依赖奇异期权
什么是CTP?——了解上期所CTP快速交易系统
了解季节性——以谷物和油籽为例
是前因还是后果?——在真格量化中进行格兰杰因果检验
Python导入模块的技巧
Python程序员常犯的十个错误
搜索数据泄露天机?——舆情指数与期货行情关联性分析思路
机器学习常见算法分类汇总
如何使用Data Pipeline 自动化数据处理工作?
CTP API的委托介绍和在真格量化中的订单流控制
高频交易对市场的影响
期货行情及其组织形式——以上期所为例
理解并行与并发
郑商所和大商所套利指令及在真格量化的实现
机器学习用于金融市场预测面临的挑战
高频交易中风险控制的常用措施
查询结果偏离预期?来了解CTP的报单函数及委托状态查询
Python中的ftplib模块
理解真格量化的Python编程范式
需要处理大量市场数据?来了解一下MySQL、HBase、ES的特点和应用场景
NumPy中的ndarray与Pandas的Series和DataFrame之间的区别与转换