Faster R-CNN: TowardsReal-Time Object Detection with Region Proposal Networks阅读笔记
Faster R-CNN: TowardsReal-Time Object Detection with Region Proposal Networks
Shaoqing Ren, Kaiming He, Ross Girshick, and Jian Sun
一、摘要
目前最好的目标检测网络都依赖region proposals算法来假设目标位置。比较好的例子,例如SPP-net、Fast R-CNN已经极大地减少了这些检测网络的运行时间,Region proposal的计算便成了整个检测网络的一个瓶颈。这篇论文提出了一种RegionProposal Network(RPN),它能够和检测网络共享整张图像的卷及特征,从而使得region proposal的计算几乎cost-free。RPN是一种全卷积的网络,能够同时预测目标的边界以及对objectness得分。RPN是端到端训练,产生高质量的regionproposals用于Fast R-CNN的检测。作者通过共享卷及特征进一步将RPN和Fast R-CNN合并成一个网络,使用最近神经网络流行的术语——“attention”机制,RPN组件能够告诉网络看向哪里。对于VGG-16模型,检测系统在GPU上的帧率为5帧(包含所有步骤),同时仅用每张图300个proposals取得了PASCAL VOC2007,2012以及MS COCO数据集的最好检测精度。代码已公开。
二、Introduction
1~2节先交代问题背景,目前的网络挺好,点明问题所在——regionproposal算法比较耗时。第3节分析耗时跟region proposal使用CPU有一定关系,但即使用GPU去生成proposal来省时,依旧忽略了网络结构的特征从而错过可以共享计算的机会。
然后4~5节就是引入并介绍本文提出的算法。第4节引入了RPN,可以和目前非常好的目标检测网络共享卷积层,从而省去计算proposal的时间。第5节说明了这个想法的由来:作者发现Fast R-CNN网络结构中的卷积特征图不仅可以用于ROI池化层,另外再加一段卷积层还可以用来产生region proposals,RPN的结构就这样出来了,具体如图1,左边多出来的部分就是RPN结构。所以RPN是实质是一种全卷积层,端到端训练,专门用于产生regionproposals的任务。
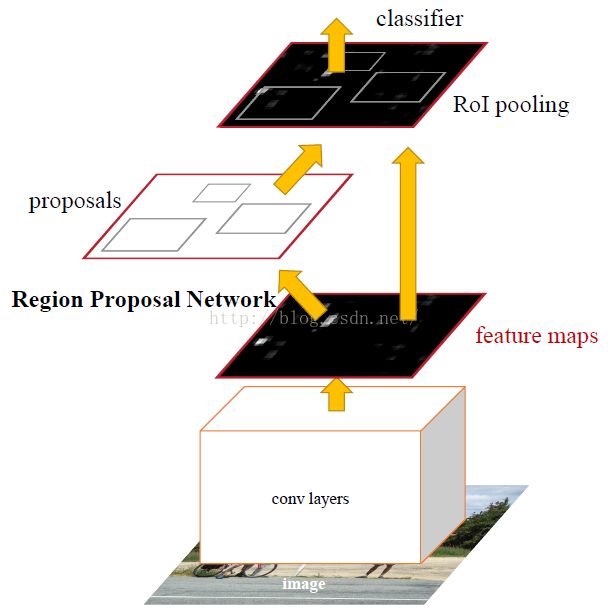
图1. Faster R-CNN的网络结构
6~7节介绍了一下结构细节的内容,也是文章正文核心的内容。RPN用于产生预测具有大范围尺度以及长宽比变化的regionproposals。先前的方法都是通过图像金字塔或者滤波器金字塔的方式来得到Region proposals在尺度以及长宽比上的不同模式,但是本文引入一种称为“anchor”boxes的方法实现,可以视为一种pyramids of regressionreference(回归引用金字塔,意思就是在一个位置同时预测多个不同size的proposal),如图2。这种模式不必去列举不同尺寸和长宽比的图像或者滤波器,训练和测试阶段都仅使用一种size的图像即可。为了统一RPN和Fast R-CNN,作者提出了一种训练模式:在region proposal和目标检测两个任务的fine-tuning之间交替进行。这种模式收敛很快并且产生统一的能够在两个之间共享卷积特征的网络结构。

图2. (a)图像金字塔;(b)滤波器金字塔;(c)回归引用金字塔(字面翻译)。
8~10节介绍了方法的结果以及成绩。在PASCAL VOC上评估,检测精度比Selective Search + FastR-CNN高,同时解决了Selectivesearch在测试阶段的计算负担。在GPU上即使使用复杂的VGG-16模型,帧率依旧能达到5帧(包括所有步骤),就速度和精度而言,已经达到了实际应用的效果。文章同时也展示了在MS COCO上的结果以及利用MS COCO数据对PASCAL VOC检测结果的改善,代码已公开。第9、10节交代之前的版本以及本文的方法还被很多其他方法和商业系统引用。
三、Related Work
1、Object Proposals
最近看的几篇论文都要提一下object proposals。详细内容看《What Makes for EffectiveDetection Proposals》。
2、关于目标检测的深度网络
R-CNN。端到端训练CNN来分类目标,它主要任务是分类,另外加了一个包围盒回归实现预测目标的边界。
OverFeat。训练一个全连接层对假设只有一个目标的定位任务预测盒坐标,然后全连接层接入卷积层用于检测多个具体类别。
MultiBox。从最后一个fc层同时预测多个包围盒的网络中生成区域建议,R-CNN就是用的这个。
另外,卷积的共享计算近来也很热门。主要就是SPPnet, FastR-CNN。
四、Faster R-CNN
本文的目标检测系统主要由两个模块构成:深度全卷积网络(RPN)用于产生region proposals;Fast R-CNN Detector。
4.1 RPN
RPN以一张任意size的图像作为输入,输出的是一系列矩形的object proposals,每个proposal都会有一个object score,本文用一个全卷积网络(n*n的卷积层+两个并列的1*1卷积层)来对这个过程进行建模。
产生proposal的方法(我的理解)是:将卷积特征图(convolutional feature map)划分为W*H个窗口,然后用滑动窗口的方式产生proposals。滑动的时候每次取3*3个窗口作为RPN的输入,先经过一些中间层映射成更低维的特征(通常ZF网络是256维,VGG-16是512维),然后将这个特征转入到两个并列的全连接层(一个回归位置,一个分类)产生proposals。见图3。所以RPN的结构可以看成是一个3*3的卷积层加上两个并列的1*1的全连接层。

图3. RPN的结构。
4.1.1anchors
在每个滑动窗口的位置,同时预测多个region proposals,proposals最大数目设置为k。这样,reg层输出4k个值表示proposal的坐标,cls层输出2k个值评估proposal是否为目标的概率。这k个proposals时关于k个reference boxes参数化的,因此称为anchors。anchor以滑动窗口为中心,对应一种特定尺度以及长宽比,默认选取三中尺度三种长宽比,因此每个滑动位置产生9个anchors。最终总共最多产生W*H*k个anchorss(当然会选取得分高的anchors作为proposals的)。
Translation-Invarlation Anchors
本文方法一个重要的特点就是平移不变性,意思就是对于anchors以及与anchors相关的计算proposals的函数而言,具有平移不变性。举个例子,如果将图像中的目标平移了,依然能计算出对应的平移的proposals,并且在任何位置函数都能预测到它。MultiBox用的是K均值方法产生800个anchors,不具有平移不变性。
平移不变性还能减小模型的尺寸。MultiBox的全连接输出层是(4+1)*800维,本文卷积输出层是(4+2)*9维(k取9),结果就是本文输出层2.8*10^4个参数,而MultiBox有6.1*10个参数,相差两个量级。考虑特征映射层,也会相差一个量级。
Multi-Scale Anchors as Regression References
将本文的多尺度anchors和图像/滤波器金字塔作比较,并举了例子,来说明本文基于anchor的方法实现多尺度有两个好处:一、省时;二、可以仅使用一张一张图像的卷积特征图(事实上还是省时)。
4.1.2loss function
这一部分没有细看,就是RPN训练reg和cls层的loss函数。
4.1.3训练RPNs
训练RPN过程的采样策略以及参数设置。通过反向传播算法以及随机梯度下降算法实现端到端训练,采用的是“Fast R-CNN”的采样策略。每个mini-batch由一张包含多个正负ahchors的单一图像产生,由于优化loss函数的时候会偏向占主导作用的负样本,所以本文采样的mini-batch的正负anchors的比例保持在1:1,随机采样256个anchors来计算损失函数。
新构建的层所有参数一均值0标准差0.01的高斯分布随机采样,其它层用ImageNet分类的参数初始化。ZF的所有层都参与优化,VGG-16从conv3向上的层优化。学习速率一开始的60000minibatches设置0.001,接下来的20000个minibatches设置为0.0001。
4.2 RPN和Fast R-CNN共享特征
上面4.1提到的是如何单独训练RPN,4.2描述怎样训练RPN和Fast R-CNN统一的网络结构。作者讨论了三种训练共享特征的方法:
(1)迭代训练。先训练RPN,然后用训练好的RPN产生的proposals来训练Fast R-CNN。接着由Fast R-CNN微调的结构初始化RPN。以上,交替进行。这也是本文所有实验使用的方法。
(2)和(3),Approximatejoint training和Non-approximatejoint training。因为作者没用,也就没细看了。
4-Step Alternating Training
第一步,训练RPN,用ImageNet预训练模型初始化参数来微调网络;第二步,用前面训练的RPN产生的proposals单独训练一个Fast R-CNN网络;第三步,用检测网络初始化RPN,固定共享的卷积层,只微调RPN单独的部分;第四步,固定共享的卷积层,微调Fast R-CNN独立的部分。以上,训练结束。可以迭代,但是改善很小。
4.3 实现细节
见这个网址:http://blog.csdn.net/liumaolincycle/article/details/48804687
五、实验
5.1 PASCAL VOC
两个数据集:PASCAL VOC 2007,PASCAL VOC2012;两个网络:ZF,VGG-16。
(1)先评估的是平均精度。
下图给出了PASCAL VOC 2007的结果,使用了各种proposal的方法进行比较。

图4. SS表示Selectivesearch; EB表示EdgeBoxes。
关于RPN的不同设置的实验结果。图5。包括是否共享卷积层,proposals的数量,是否添加非极大值抑制,以及是否含有reg和cls层的结果。

图5. 关于RPN的消融实验。
关于VGG-16网络结构在PASCAL 2007上的表现。图6。包括了和SS的比较,是否共享特征以及数据集的变化的结果。
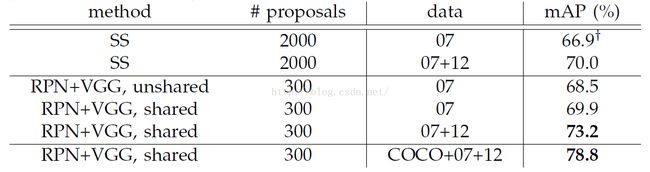
图6. 关于VGG-16的实验(VOC 2007)。
又贴出了VGG-16在PASCAL VOC 2012上的表现。

图7. 关于VGG-16的实验(VOC 2012)。
(2)接着评估了运行时间

图8. SS和RPN的运行时间比较。
(3)比较了不同尺度以及长宽比结果

接着还分级了IoU和召回率的比较结果以及λ对结果影响。图太多,不贴了。
5.2 MS COCO数据库的结果。
[email protected]最好的结果是42.7%,mAP@[.5,.95]是21.9%。
5.3 借用MS COCO数据训练PASCALVOC的结果
VOC2007最好结果是78.8%;VOC 2012最好结果是75.9%。速度没有变化。