基于canal的实时数据同步架构
技术背景
数据同步作为数仓建设和数据分析的基础环节,其重要性不言而喻。目前业界最常用的做法是离线按天备份,通过批处理的方式直连业务库,将数据全量导入到数仓。这种方式简单直接,不会担心数据丢失等问题。然而因为是离线操作,每一次导入都是对过去一天的数据镜像,对于实时应用场景,无法及时同步新增数据,而且频繁的读取业务库很容易对业务库造成压力。对于我们的特殊场景:从阿里云跨云同步到AWS,这种大批量的数据同步耗费流量不说,数据同步耗时和网络抖动造成的连接中断、延时等问题更是不可忽视。此外对于大量的分库分表的同步,如果处理不好,还会带来新的问题比如上层业务的分表合并等,那有没有一种更好的方式呢?当然有!我们知道基于binlog的mysql实时主从同步技术已经相当成熟,同样binlog也可以用来做异构数据源之间的数据同步。canal就是这样的系统,用于mysql数据同步到mysql、mq,elasticsearch、mongodb、hbase等系统。在详细介绍基于canal的数据同步系统架构之前,先简单回顾下canal的基本原理。
canal原理
binlog介绍
binlog是Mysql sever层维护的一种二进制日志,与innodb引擎中的redo/undo log是完全不同的日志;其主要是用来记录对mysql数据更新或潜在发生更新的SQL语句,并以"事务"的形式保存在磁盘中;Mysql binlog日志有ROW,Statement,MiXED三种格式:
Row: 仅保存记录被修改细节,不记录sql语句上下文相关信息优点:能非常清晰的记录下每行数据的修改细节,不需要记录上下文相关信息。由于所有的执行的语句在日志中都将以每行记录的修改细节来记录,因此,可能会产生大量的日志内容。
Statement: 每一条会修改数据的sql都会记录在binlog中优点:只需要记录执行语句的细节和上下文环境,避免了记录每一行的变化。但是存在某些函数和存储过程不一定能够保证在slave上和master上执行结果一致。
Mixed:以上两种格式的结合。不过,新版本的MySQL对row level模式也被做了优化,并不是所有的修改都会以row level来记录,像遇到表结构变更的时候就会以statement模式来记录,如果sql语句确实就是update或者delete等修改数据的语句,那么还是会记录所有行的变更;因此,现在一般使用row level即可。
通过变量binlog_format查看当前binlog格式:
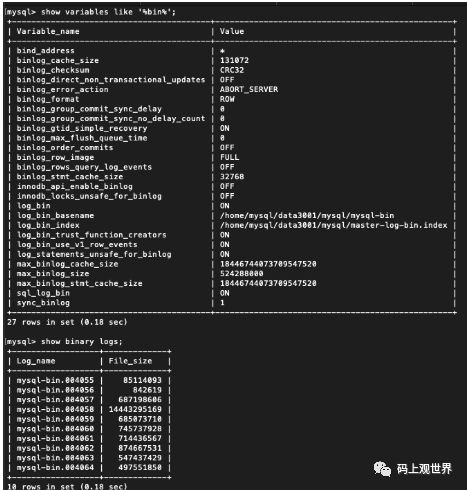
binlog的位置由文件和文件的相对位置唯一确定,我们可以通过命令行查询binlog的内容:

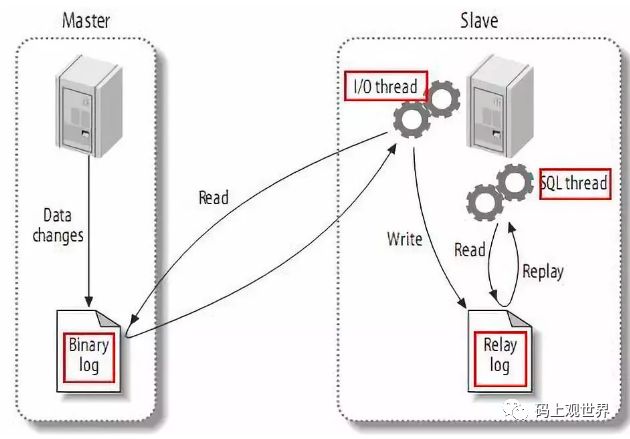
数据库的主从复制是binlog的用途之一,其原理为:
MySQL master 将数据变更写入二进制日志
MySQL slave 将 master 的 binary log events 拷贝到它的中继日志(relay log)
MySQL slave 重放 relay log 中事件,将数据变更反映它自己的数据
canal简介
作为阿里巴巴的一个开源项目,canal 不仅在公司内部经受了跨集群、跨国同步的考验,而且已经在很多大型的互联网公司比如美团等都有广泛的应用。
canal是通过模拟成为mysql 的slave的方式,监听mysql 的binlog日志来获取数据并转存到不同的目的地(destination)。
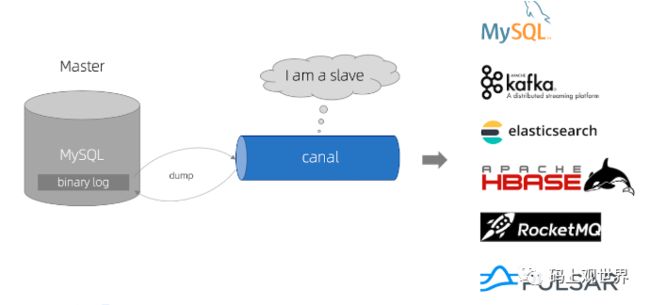
canal架构
canal server是canal的基本部署实例,在实现上一个canal server 部署实例由多个binlog数据通道实例组成的。canal server就是一个jvm运行实例,
binlog数据通道实例由Parser、Sink和store模块组成,完成binlog的解析、过滤和存储一整条链路功能。跟binlog数据通道的关系为:
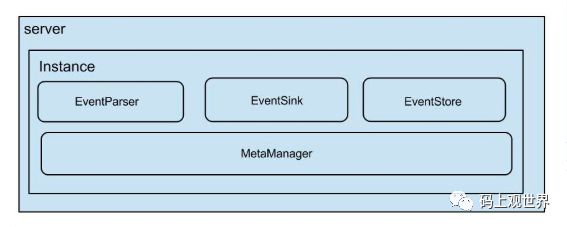
其中数据通道实例的逻辑拓扑结构可表示为:
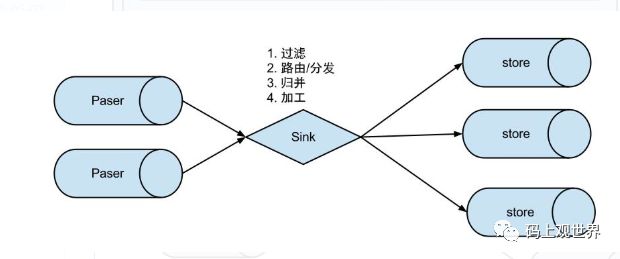
canal部署
数据通道实例默认跟数据库实例一一对应,每个通道实例在部署上有自己独立的属性配置目录,目录里面维护两类配置文件:
canal.properties:作为所有数据通道的公共部分,用于配置全局性的信息,如mq地址、zk地址以及cannal server运行时参数等
canal server负责本实例上的所有数据通道的可用性,采用pull的消费模型供canal客户端读取消息。在部署上面,可以单独部署,在生产环境上,建议采用HA高可用部署方案:
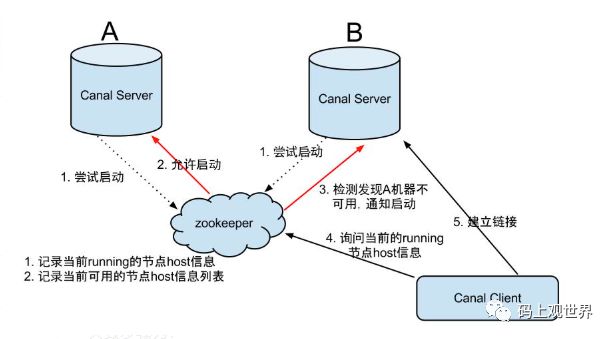
大致步骤为:
1. canal server要启动某个canal instance时都先向zookeeper进行一次尝试启动判断 (实现:创建EPHEMERAL节点,谁创建成功就允许谁启动)
2. 创建zookeeper节点成功后,对应的canal server就启动对应的canal instance,没有创建成功的canal instance就会处于standby状态
3. 一旦zookeeper发现canal server A创建的节点消失后,立即通知其他的canal server再次进行步骤1的操作,重新选出一个canal server启动instance.
4. canal client每次进行connect时,会首先向zookeeper询问当前是谁启动了canal instance,然后和其建立链接,一旦链接不可用,会重新尝试connect.
通过合理配置数据通道的备份数量,可以实现canal server集群的高可用和部分负载均衡功能,canal在zk集群的注册信息结构为:
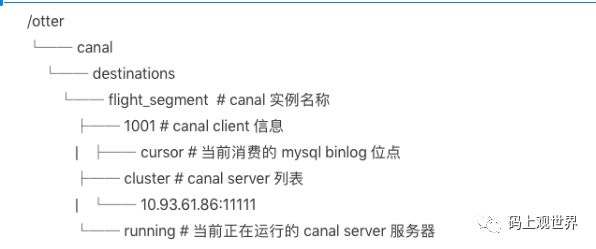
了解了canal的基本原理和部署方式之后,再来看看如何基于canal设计数据同步架构。
总体流程

canal server:通过binlog通讯协议拉取mysql 服务器的日志,完成解析并存储到消息系统kafka,canal client消费kafka数据写入s3包括合并和去重,结果数据以分区形式加载到hive表。涉及到的主要功能组件:
mysql :需要同步的mysql服务器,对于开启gtid的阿里云 rds,因为slave binlog数据格式是经过简化的,同步的mysql服务器需要选择mysql master,对于aws rdb数据库,暂没有此要求,可以使用mysql slave。
canal server:拉取并解析mysql binlog日志,并封装成易于下游模块使用的数据结构。canal server实例是部署的基本单元,对一个数据库实例可以根据要求的可用性级别部署一个或多个canal server,如果一个数据库实例对应有多个canal server实例,因为同一个mysql同步部署单元中只能有一个主canal实例处于Active状态,于是在多canal实例的情况下需要借助zookeeper选主。
kafka:canal server将解析后的binlog数据发送到配置的kafka topic,canal server支持将同一个mysql实例的所有binlog发送到同一个topic、多个分表发送到一个topic以及每个表到独立的topic等。
canal client:拉取kafka topic数据,根据topic数据大小进行数据的并行消费、合并、排序和去重等功能。canal client可以作为常驻进程托管到实时流系统比如spark streaming、flink等,也可以是作为批处理任务托管到离线调度系统。
s3: kafka消费后的数据暂存外部系统,可以是aws的s3或者hdfs、甚至是本地文件系统等,根据使用使用环境和可用性要求选取。
hive:mysql增量数据导入到hive分区表,表结构根据mysql表的schema 自动创建。
数据消费
canal 的EventStore基于本地内存存储实现,数据的存储、读取和ack采用类似Disruptor的RingBuffer的实现思路:
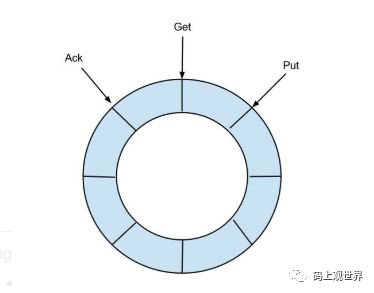
RingBuffer定义了3个cursor:
Put : Sink模块进行数据存储的最后一次写入位置
Get : 数据订阅获取的最后一次提取位置
Ack : 数据消费成功的最后一次消费位置
canal客户端在数据消费支持并行消费、批量消费和异步消费,增大消费处理能力。

上面示例代码演示了一个从canal server集群中循环拉取消息的过程:首先设置canal server的zk地址和destination(对应一个canal server)以及订阅的库表(可以通过filter可以对destination进一步过滤筛选)等信息,然后通过调用getWithoutAck方法批量读取,如果读取并且处理没有异常抛出,就可以通过ack确认进行下一批次读取。通过这种读取canal server数据并实时消费的方式在普通场景下是可行的,但在生产环境中更适合结合kafka,下文详述。
kafka
在简单的数据同步场景,可以按照上面实现自己的canal客户端直接读取canal server的数据,但是对于生产环境使用场景,因为binlog的存储时间有限(比如阿里云rds数据库默认保存18小时),为防止数据不可用以及对于需要重复消费等场景,有必要将数据存储到第三方消息系统,如kafka或者rocketmq。在canal中,可以直接配置canal消息转存到kafka和rocketmq这两个消息系统,并可以自定义配置投递到topic的规则。如果topic存在多个分区,还可以指定数据在分区之间的路由方式,以kafka为例:
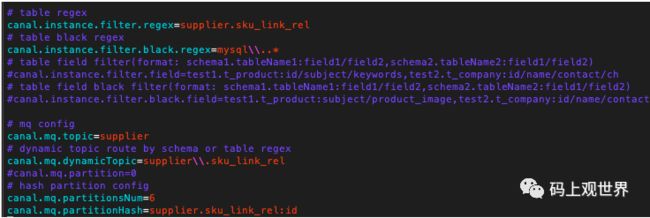
比如上图中,我们只关注supplier.sku_link_rel表的binlog,发送到topic为supplier.sku_link_rel中,并且设置根据表的主键id在6个分区中路由。同时忽略系统库mysql的消息,减少不必要的数据传输。对于分表的方式,还可以将多个分表的数据合并到同一个topic:
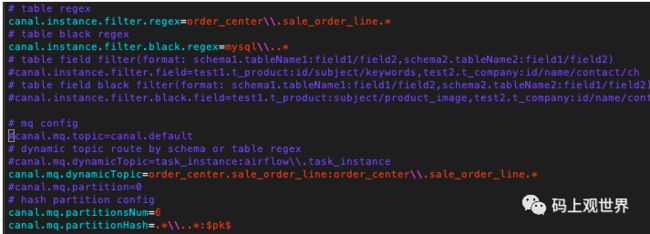
示例中,将名字以sale_order_line开头的表的数据合并到topic:order_center.sale_order_line,注意其中topic路由方式按照表的主键$pk。
以上介绍了架构的主体部分,接下来对其中涉及到的关键问题逐一叙述。