深度卷积生成对抗网络DCGAN之实现动漫头像的生成(基于keras Tensorflow2.0实现)
起飞目录
- DCGAN简介
- 反卷积(上采样upsampling2D)
- 数据集
- 代码实战
- 数据导入和预处理
- 生成器G
- 判别器D
- 训练模块
- 完整代码
- 结果
DCGAN简介
原始GAN在图片生成方面具有一定的缺陷:存在训练不稳定,训练过程中梯度易消失等一系列问题。
而DCGAN(Deep Convolutional Generative Adeversarial Networks)深度卷积生成对抗网络,最主要是在原始GAN的基础上加入了卷积和反卷积(上采样)的操作,而CNN卷积神经网络在处理和提取图片特征的工作中具有明显的先天优势,所以DCGAN能很大程度的提升我们生成图片的质量。
反卷积(上采样upsampling2D)
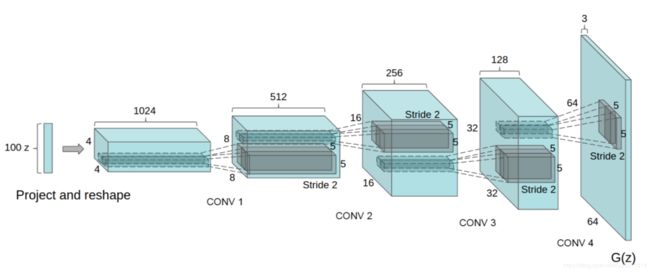
DCGAN在生成器G中加入上采样操作,对随机噪声先赋予深度后,进行不断的上采样,缩短深度,增大图片的宽度和高度,使得最后的输出与真实图片大小一致。
数据集
数据集来自Kaggle的tagged-anime-illustrations数据集
共包含70171个96×96的动漫头像
话不多说直接开冲

代码实战
代码整体框架和训练思路与GAN一致,变化的是生成器G和判别器D的模型构建部分。
数据导入和预处理
创建大小为(图片数量,64,64,3)的张量,将文件夹中的图片导入,依次将原始图片大小转为(64,64)以减小内存,然后进行[-1,1]上的数据归一化。
def load_image(filename):
imgs = os.listdir(filename)
x_train = np.empty((imgs.__len__(), 64, 64, 3), dtype='float32')
for i in range(len(imgs)):
img = Image.open(filename + imgs[i])
img = img.resize((64,64))
img_arr = np.asarray(img, dtype='float32')
x_train[i, :, :, :] = img_arr/127.5 - 1.
return x_train
生成器G
具体的模型结构可以看代码,这里就显示一下数据的变化吧
| 输入 | (batch,100,1) |
|---|---|
| 第一层reshape后输出 | (batch,8,8,256) |
| 第二层卷积输出 | (batch,16,16,128) |
| 第三层卷积输出 | (batch,32,32,64) |
| 第四层卷积输出 | (batch,64,64,3) |
这里说明一下:输出图片高度宽度可以自行根据网络结构进行调整
def build_generator(self):
model = Sequential()
model.add(Dense(256 * 8 * 8, activation='relu', input_dim=self.latent_dim)) # 输入维度为100
model.add(Reshape((8, 8, 256)))
model.add(UpSampling2D())
model.add(Conv2D(128, kernel_size=5, padding='same'))
model.add(BatchNormalization(momentum=0.8))
model.add(Activation("relu"))
model.add(UpSampling2D())
model.add(Conv2D(64, kernel_size=5, padding="same"))
model.add(BatchNormalization(momentum=0.8))
model.add(Activation("relu"))
model.add(UpSampling2D())
model.add(Conv2D(3, kernel_size=5, padding="same"))
model.add(Activation("tanh"))
model.summary() # 打印网络参数
noise = Input(shape=(self.latent_dim,))
img = model(noise)
return Model(noise, img)
判别器D
判别器输出层之前采用GlobalAveragePooling(全局池化),这里简单提一下。
GlobalAveragePooling2D:相比于平均池化(在特征图上以窗口的形式滑动,去窗口内的平均值为采样值),全局平均池化不再以窗口滑动的形式取平均值,而是直接针对特征图取平均值,即每个特征图输出一个值。
通过这种方式,每个特征图都与分类概率直接联系起来,替代了全连接层的功能,并且不产生额外的训练参数,减小了过拟合的可能,但是会导致网络收敛速度变慢。
| 输入 | (batch,100,1) |
|---|---|
| 第一层卷积输出 | (batch,64,64,3) |
| 第二层卷积输出 | (batch,32,32,64) |
| 第三层卷积输出 | (batch,16,16,128) |
| 第四层卷积输出 | (batch,8,8,256) |
| 全局平均池化后输出 | (batch,256) |
| 输出 | (batch,1) |
def build_discriminator(self):
model = Sequential()
dropout = 0.5
model.add(Conv2D(64, kernel_size=5, strides=2, input_shape=self.img_shape, padding="same"))
model.add(LeakyReLU(alpha=0.2))
model.add(Dropout(dropout))
model.add(Conv2D(128, kernel_size=5, strides=2, padding="same"))
model.add(BatchNormalization(momentum=0.8))
model.add(LeakyReLU(alpha=0.2))
model.add(Dropout(dropout))
model.add(Conv2D(256, kernel_size=5, strides=2, padding="same"))
model.add(BatchNormalization(momentum=0.8))
model.add(LeakyReLU(alpha=0.2))
model.add(Dropout(dropout))
model.add(GlobalAveragePooling2D())
model.add(Dense(1, activation='sigmoid'))
model.summary()
img = Input(shape=self.img_shape)
validity = model(img)
return Model(img, validity)
训练模块
训练过程是GAN的重要思想,DCGAN训练模式与GAN相同,下面我们着重细致的讲解一下GAN是如何训练的吧。
将数据归一化和创建好真假标签后,我们开始进行每次epoch的训练
1. 首先对判别器进行训练:
这时候输入值有2种:
一是随机噪声输入生成器产生的假图片和标签0(第一次epoch时,生成器中可训练参数只是初始化的参数值);
二是真正的图片和标签1。对这两种输入值分别经过二元交叉熵函数(binary crossentropy)计算损失值求出d_loss_real和d_loss_fake,最终判别器D的损失值为二者的平均值d_loss = 0.5 * d_loss_real + 0.5 * d_loss_fake
2. 然后训练生成器:
训练生成器的时候,停止对判别器的训练,设置self.discriminator.trainable=False,为生成器输入随机噪声,将生成器产生的图片打上真实值标签1送入在这次epoch中已经训练好的判别器中,继续通过二元交叉熵函数(binary crossentropy)做loss进行生成器的训练,这样的话生成器就会向着真实值靠近。
训练完每次epoch后生成器性能就会增强,然后回到我们的第一步继续训练判别器,再训练生成器,在这样不断地相互博弈和促进下,最终生成器会达到以假乱真的效果。
def train(self, epochs, batch_size=128, save_interval=50):
# 载入数据
filename = "E:/数据集/faces/"
X_train = load_image(filename)
# Adversarial ground truths
valid = np.ones((batch_size, 1))
fake = np.zeros((batch_size, 1))
for epoch in range(epochs):
# --------------------- #
# 训练判别模型
# --------------------- #
idx = np.random.randint(0, X_train.shape[0], batch_size)
imgs = X_train[idx]
noise = np.random.normal(0, 1, (batch_size, self.latent_dim))
gen_imgs = self.generator.predict(noise)
# 训练并计算loss
d_loss_real = self.discriminator.train_on_batch(imgs, valid)
d_loss_fake = self.discriminator.train_on_batch(gen_imgs, fake)
d_loss = 0.5 * np.add(d_loss_real, d_loss_fake)
# ---------------------
# 训练生成模型
# ---------------------
g_loss = self.combined.train_on_batch(noise, valid)
print ("%d [D loss: %f, acc.: %.2f%%] [G loss: %f]" % (epoch, d_loss[0], 100*d_loss[1], g_loss))
if epoch % save_interval == 0:
self.save_imgs(epoch)
完整代码
from __future__ import print_function, division
from tensorflow.keras.layers import Input, Dense, Reshape, Dropout
from tensorflow.keras.layers import BatchNormalization, Activation, GlobalAveragePooling2D
from tensorflow.keras.layers import LeakyReLU
from tensorflow.keras.layers import UpSampling2D, Conv2D
from tensorflow.keras.models import Sequential, Model
from tensorflow.keras.optimizers import Adam
from PIL import Image
import matplotlib.pyplot as plt
import os
import numpy as np
class DCGAN():
def __init__(self):
# 输入shape
self.img_rows = 64
self.img_cols = 64
self.channels = 3
self.img_shape = (self.img_rows, self.img_cols, self.channels)
self.latent_dim = 100
# adam优化器
optimizer = Adam(0.0002, 0.5)
# 判别模型
self.discriminator = self.build_discriminator()
self.discriminator.compile(loss=['binary_crossentropy'],
optimizer=optimizer,
metrics=['accuracy'])
# 生成模型
self.generator = self.build_generator()
# conbine是生成模型和判别模型的结合
# 判别模型的trainable为False
# 用于训练生成模型
z = Input(shape=(self.latent_dim,))
img = self.generator(z)
self.discriminator.trainable = False
valid = self.discriminator(img)
self.combined = Model(z, valid)
self.combined.compile(loss='binary_crossentropy', optimizer=optimizer)
def build_generator(self):
model = Sequential()
model.add(Dense(256 * 8 * 8, activation='relu', input_dim=self.latent_dim)) # 输入维度为100
model.add(Reshape((8, 8, 256)))
model.add(UpSampling2D())
model.add(Conv2D(128, kernel_size=5, padding='same'))
model.add(BatchNormalization(momentum=0.8))
model.add(Activation("relu"))
model.add(UpSampling2D())
model.add(Conv2D(64, kernel_size=5, padding="same"))
model.add(BatchNormalization(momentum=0.8))
model.add(Activation("relu"))
model.add(UpSampling2D())
model.add(Conv2D(3, kernel_size=5, padding="same"))
model.add(Activation("tanh"))
model.summary() # 打印网络参数
noise = Input(shape=(self.latent_dim,))
img = model(noise)
return Model(noise, img)
def build_discriminator(self):
model = Sequential()
dropout = 0.5
model.add(Conv2D(64, kernel_size=5, strides=2, input_shape=self.img_shape, padding="same"))
model.add(LeakyReLU(alpha=0.2))
model.add(Dropout(dropout))
model.add(Conv2D(128, kernel_size=5, strides=2, padding="same"))
model.add(BatchNormalization(momentum=0.8))
model.add(LeakyReLU(alpha=0.2))
model.add(Dropout(dropout))
model.add(Conv2D(256, kernel_size=5, strides=2, padding="same"))
model.add(BatchNormalization(momentum=0.8))
model.add(LeakyReLU(alpha=0.2))
model.add(Dropout(dropout))
model.add(GlobalAveragePooling2D())
model.add(Dense(1, activation='sigmoid'))
model.summary()
img = Input(shape=self.img_shape)
validity = model(img)
return Model(img, validity)
def train(self, epochs, batch_size=128, save_interval=50):
# 载入数据
filename = "E:/数据集/faces/"
X_train = load_image(filename)
# Adversarial ground truths
valid = np.ones((batch_size, 1))
fake = np.zeros((batch_size, 1))
for epoch in range(epochs):
# --------------------- #
# 训练判别模型
# --------------------- #
idx = np.random.randint(0, X_train.shape[0], batch_size)
imgs = X_train[idx]
noise = np.random.normal(0, 1, (batch_size, self.latent_dim))
gen_imgs = self.generator.predict(noise)
# 训练并计算loss
d_loss_real = self.discriminator.train_on_batch(imgs, valid)
d_loss_fake = self.discriminator.train_on_batch(gen_imgs, fake)
d_loss = 0.5 * np.add(d_loss_real, d_loss_fake)
# ---------------------
# 训练生成模型
# ---------------------
g_loss = self.combined.train_on_batch(noise, valid)
print ("%d [D loss: %f, acc.: %.2f%%] [G loss: %f]" % (epoch, d_loss[0], 100*d_loss[1], g_loss))
if epoch % save_interval == 0:
self.save_imgs(epoch)
def save_imgs(self, epoch):
r, c = 5, 5
noise = np.random.normal(0, 1, (r * c, self.latent_dim))
gen_imgs = self.generator.predict(noise)
gen_imgs = 0.5 * gen_imgs + 0.5
fig, axs = plt.subplots(r, c)
cnt = 0
for i in range(r):
for j in range(c):
axs[i,j].imshow(gen_imgs[cnt, :,:,:])
axs[i,j].axis('off')
cnt += 1
fig.savefig("dc_images/MeganFaces_%d.png" % epoch)
plt.close()
def load_image(filename):
imgs = os.listdir(filename)
x_train = np.empty((imgs.__len__(), 64, 64, 3), dtype='float32')
for i in range(len(imgs)):
img = Image.open(filename + imgs[i])
img = img.resize((64,64))
img_arr = np.asarray(img, dtype='float32')
x_train[i, :, :, :] = img_arr/127.5 - 1.
return x_train
if __name__ == '__main__':
if not os.path.exists("./dc_images"):
os.makedirs("./dc_images")
dcgan = DCGAN()
dcgan.train(epochs=20000, batch_size=256, save_interval=50)
结果
友情提醒:我的笔记本搭载显卡1660TI,但是用该数据集跑完20000个epoch的话也是需要3个小时的,如果没有进行图片缩放的话估计要8个小时。。。所以建议大家对图片缩放至(32,32)或者减小数据集维度;当然,这样也许会导致,你的“老婆”生成效果不太好= =

