PySpark源码分析之Driver端基于Py4j的通信详解
文章目录
- 概述
- 服务端启动
- Python客户端
- 编程示例
概述
接上文 PySpark源码分析之AM端运行流程(Driver) 的最后部分可知,PySpark是通过Py4j来实现与Scala端JVM通信交互的(注:Py4j只用于Driver端Python调用JVM中方法;Executor端是直接通过socket通信的。),PySpark主要提供一层Python API的封装。其过程主要是JVM会开启一个Socket端口提供RPC服务,Python需要调用Spark API时,它会作为客户端将调用指令序列化成字节流发送到Socket服务端口,JVM接受字节流后解包成对应的指令,然后找到目标对象和代码进行执行,然后将执行结果序列化成字节流通过Socket返回给客户端,客户端收到字节流后再解码成Python对象,于是Python客户端就成功拿到了远程调用的结果(注:Py4j同时支持【Python -> JVM】和【JVM -> Python】,本文仅仅分析前者,后者在Spark Streaming中有适用场景,以后有时间再分析)。
官方文档:https://www.py4j.org/index.html
github:https://github.com/bartdag/py4j
Py4j内存模型:
Every time a Java object is sent to the Python side, a reference to the object is kept on the Java side (in the Gateway class). Once the object is garbage collected on the Python VM (reference count == 0), the reference is removed on the Java VM: if this was the last reference, the object will likely be garbage collected too. When a gateway is shut down, the remaining references are also removed on the Java VM.
Because Java objects on the Python side are involved in a circular reference (JavaObject and JavaMember reference each other), these objects are not immediately garbage collected once the last reference to the object is removed (but they are guaranteed to be eventually collected if the Python garbage collector runs before the Python program exits).
In doubt, users can always call the detach function on the Python gateway to explicitly delete a reference on the Java side. A call to gc.collect() also usually works.
每次将Java对象发送到Python端时,对该对象的引用都保存在Java端(在Gateway类中)。一旦对象在Python VM上被垃圾收集(引用计数== 0),该引用在Java的VM上也会被删除:如果这是最后一个引用,那么该对象也很可能被垃圾收集。当gateway关闭时,剩余的引用也会在Java VM上删除。
因为Python端的Java对象间循环引用(JavaObject和JavaMember相互引用),所以在删除最后一个对象引用后并不会立即进行垃圾回收(但能够保证在Python程序最终退出之前,进行Python的垃圾回收)。
毫无疑问,用户也可通过在Python端调用detach函数的来显式的删除Java端上的引用。也可调用gc.collect()实现。
参考:https://www.py4j.org/advanced_topics.html#py4j-memory-model
服务端启动
首先我们先看Py4j的原理图,如下图:
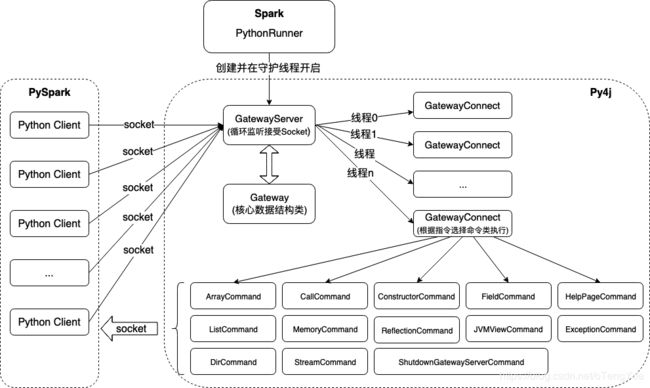
如上图,Spark的Driver运行PythonRunner启动Py4j服务端,当服务启动后GatewayServer开始循环监听端口接受socket连接,针对每个socket连接开启一个子线程,创建对应的GatewayConnect,并根据客户端传递的消息指令选择命令类进行执行,处理后的结果同样通过封装socket返回给Python客户端。
命令类包含:
- ArrayCommand:处理Array的相关操作。
- CallCommand:在已实例化类上反射调用函数。
- ConstructorCommand:通过反射实例化类。
- FieldCommand:通过反射设置或获取实例化类变量值。
- HelpPageCommand:为Java对象生成帮助文档。
- ListCommand:处理List的相关操作。
- MemoryCommand:用于垃圾回收过程中删除服务端对象。
- ReflectionCommand:用于反射package、class和静态成员。
- ShutdownGatewayServerCommand:接受处理关闭GatewayServer的指令。
- JVMViewCommand:管理JVMView的操作,包含:创建新的JVMView(提供了默认的defaultJVMView,但也支持创建新的)、添加imports和搜索拼接类完全限定名。
- ExceptionCommand:处理异常类的操作。
- DirCommand:用于获取类的相关属性,包含:public字段名、public方法名、public static属性(包含:字段名、方法名和类名)和JVMView中的import
- StreamCommand:同CallCommand,区别是CallCommand直接返回结果,StreamCommand以流的方式返回结果。
然后我们看核心类 Gateway (分析见注释,只截取部分关键代码):
/**
*
*
* A Gateway manages various states: entryPoint, references to objects returned
* to a Python program, etc.
*
*
*
* This class is not intended to be directly accessed by users.
*
*
* @author Barthelemy Dagenais
*
*/
public class Gateway {
/** Server创建的任意对象都会保存在bindings变量 */
private final Map bindings = new ConcurrentHashMap();
private final AtomicInteger objCounter = new AtomicInteger();
private final AtomicInteger argCounter = new AtomicInteger();
private final static String OBJECT_NAME_PREFIX = "o";
private final Object entryPoint;
/** 反射工具类 */
private final ReflectionEngine rEngine = new ReflectionEngine();
private Py4JPythonClient cbClient;
/** 默认JVM视图,主要保存import package */
private final JVMView defaultJVMView;
private final Logger logger = Logger.getLogger(Gateway.class.getName());
private boolean isStarted = false;
public Gateway(Object entryPoint) {
this(entryPoint, null);
}
public Gateway(Object entryPoint, Py4JPythonClient cbClient) {
this.entryPoint = entryPoint;
this.cbClient = cbClient;
this.defaultJVMView = new JVMView("default", Protocol.DEFAULT_JVM_OBJECT_ID);
}
public void deleteObject(String objectId) {
bindings.remove(objectId);
}
public JVMView getDefaultJVMView() {
return this.defaultJVMView;
}
protected String getNextObjectId() {
return OBJECT_NAME_PREFIX + objCounter.getAndIncrement();
}
...
/**
* 所有Server创建的对象返回给client前都会调用该方法,主要功能包含:
* 1、新创建的对象都通过putNewObject函数生成objectId,并把对象添加到bindings变量(Map类型),注:基础数据类型、BigDecimal和无返回的对象无需添加到bindings变量
* 2、根据创建的对象类型组织返回给Client的对象ReturnObject,注:一般最终调用Protocol.getOutputCommand(returnObject)拼接成返回的字符串
*/
@SuppressWarnings("rawtypes")
public ReturnObject getReturnObject(Object object) {
ReturnObject returnObject;
if (object != null) {
if (isPrimitiveObject(object)) {
returnObject = ReturnObject.getPrimitiveReturnObject(object);
} else if (object == ReflectionEngine.RETURN_VOID) {
returnObject = ReturnObject.getVoidReturnObject();
} else if (isDecimalObject(object)) {
returnObject = ReturnObject.getDecimalReturnObject(object);
} else if (isList(object)) {
String objectId = putNewObject(object);
returnObject = ReturnObject.getListReturnObject(objectId, ((List) object).size());
} else if (isMap(object)) {
String objectId = putNewObject(object);
returnObject = ReturnObject.getMapReturnObject(objectId, ((Map) object).size());
} else if (isArray(object)) {
String objectId = putNewObject(object);
returnObject = ReturnObject.getArrayReturnObject(objectId, Array.getLength(object));
} else if (isSet(object)) {
String objectId = putNewObject(object);
returnObject = ReturnObject.getSetReturnObject(objectId, ((Set) object).size());
} else if (isIterator(object)) {
String objectId = putNewObject(object);
returnObject = ReturnObject.getIteratorReturnObject(objectId);
} else {
String objectId = putNewObject(object);
returnObject = ReturnObject.getReferenceReturnObject(objectId);
}
} else {
returnObject = ReturnObject.getNullReturnObject();
}
return returnObject;
}
/**
*
* Invokes a constructor and returned the constructed object.
* 根据类的全限定名(例如:package1.package2.className)和构造参数反射实例化类
*
*
* @param fqn
* The fully qualified name of the class.
* @param args
* @return
*/
public ReturnObject invoke(String fqn, List 分析上面代码可知,Gateway Server创建的任意对象都会携带由服务端生成的唯一的对象id,服务端会将生成的所有对象装在一个Map结构里。当Python客户端需要操纵远程对象时,会将对象id和操纵指令以及参数一起传递到服务端,服务端根据对象id找到对应的对象,然后使用反射方法执行指令。
通过 PySpark源码分析之AM端运行流程(Driver) 我们知道,Spark启动Py4j服务端的类是 org.apache.spark.deploy.PythonRunner ,我们看服务端的源码启动流程如下图:
如上图,在PythonRunner中初始化gatewayServer后启动一个守护线程用于启动服务,在守护线程中先创建一个sSocket监听端口(传入的端口号为0,则系统会选择一个空闲端口进行监听),选择的端口会传递给Python进程来连接此gatewayServer,然后再新开启一个线程循环接受socket消息,此时服务端就启动完成了。当服务端监听到有socket连接来到时候,通过processSocket(socket)分发处理连接消息,流程如下:
从上图可以看出,processSocket()函数使用锁保证线程安全,分别对每个socket连接都创建GatewayConnection,在构造函数中重点关注从socket初始化了reader流和writer流,然后在GatewayConnection.startConnection()开辟一个线程处理消息,这样针对每个socket开辟一个线程的方式能够保证了processSocket()线程的并发性。在消息处理过程会根据消息指令选择不同的命令类处理消息,而commands(命令类Map)的构建同样是在创建GatewayConnection时候完成的,如下图:
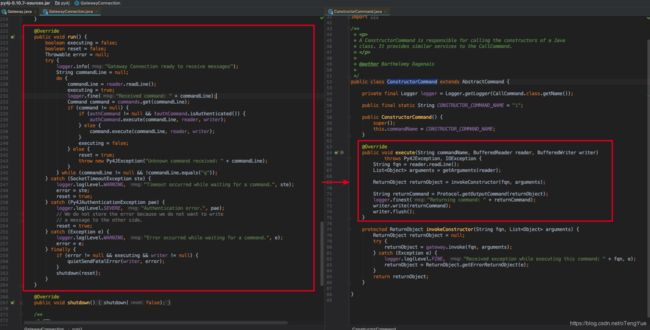
我们继续看线程中具体的消息处理过程:
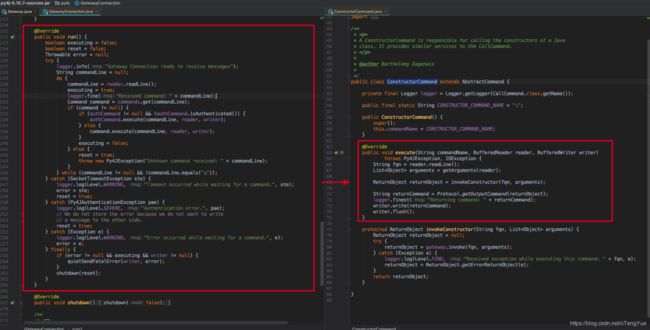
如上图,在线程中会按行读取指令,根据指令选择对应的命令类进行后续处理(上图右侧是调用ConstructorCommand实例化类的示例),结果返回是在命令类中通过write函数以socket方式返回给Python客户端。
Python客户端
PySpark中Py4j客户端的初始化是在SparkContext构造函数中完成的,初始化流程如下图:
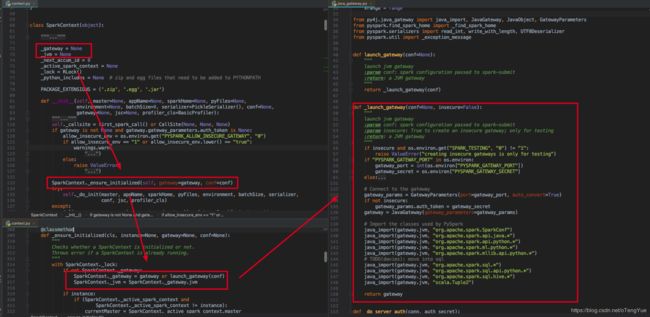
如上图可知,最终初始化关键代码在_launch_gateway()函数,获取gateway_port端口(运行在Yarn集群上是PythonRunner启动Py4j服务端后把写入到启动Python进程的环境变量中;如果直接本地启动PySpark则会调用命令拉起一个JVM启动Py4j服务端后获得端口),创建JavaGateway网关,然后调用java_import()函数把spark提供的api的package导入,最后赋值给SparkContext的_gateway变量(JavaGateway对象)和_jvm变量(JVMView对象),在PySpark中对JVM的调用实质都是通过_jvm变量来进行的,至此就完成了Py4j客户端的初始化。我们下面先看下如何使用_jvm创建SparkContext对象,如下:
def _do_init(self, master, appName, sparkHome, pyFiles, environment, batchSize, serializer,
conf, jsc, profiler_cls):
...
# Create the Java SparkContext through Py4J
self._jsc = jsc or self._initialize_context(self._conf._jconf)
# Reset the SparkConf to the one actually used by the SparkContext in JVM.
self._conf = SparkConf(_jconf=self._jsc.sc().conf())
...
def _initialize_context(self, jconf):
"""
Initialize SparkContext in function to allow subclass specific initialization
"""
return self._jvm.JavaSparkContext(jconf)
上面介绍完了PySpark中Py4j客户端的初始化,下面我们看下客户端调用流程(由于下图已很清晰,不再分析源码,大家可以参照查阅源码):
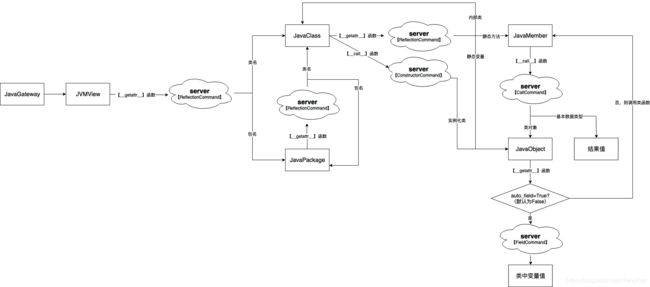
说明:
- 1、Python客户端的源码相对集中,以上流程分析 py4j/java_gateway.py 即可得出。
- 2、
JavaObject是JVM中实例化的对象在Python中的影子(其target_id变量是JVM实例化后对象对象的Key值)。 - 3、
JavaMember是对JavaObject中成员的封装,目前JavaMember只支持函数,不支持变量值(字段)。调用类变量值需创建JavaGateway时候设置gateway = JavaGateway(auto_field=True)(启用后JavaObject.__getattr__()函数会优先调用字段,可能会隐藏同名的类方法),PySpark默认未启用,因此PySpark不支持反射调用类变量。 - 4、Python通过调用
__getattr__和__call__来实现对Java对象创建、属性访问和方法调用。
编程示例
1、简单示例(一般可用于本地代码调试使用):
1.1、通过entryPoint方式调用
Java服务端
package org.apache.spark.examples;
import py4j.GatewayServer;
public class Py4jTest {
public String name = "张三";
public int addition(int first, int second) {
return first + second;
}
public static void main(String[] args) {
Py4jTest app = new Py4jTest();
// 如果服务端未设置监听端口,默认是25333
GatewayServer server = new GatewayServer(app);
server.start();
}
}
Python客户端
from py4j.java_gateway import java_import, JavaGateway
# 函数调用
gateway = JavaGateway()
result = gateway.entry_point.addition(1,2)
print(result) # 输出:3
# 如果需反射获取类字段值,需设置auto_field=True
gateway = JavaGateway(auto_field=True)
name = gateway.entry_point.name
print(name) # 输出:张三
1.2、通过完全限定名类方式调用
Java服务端
package org.apache.spark.examples;
import py4j.GatewayServer;
public class Py4jTest {
public String name = "张三";
public int addition(int first, int second) {
return first + second;
}
public static void main(String[] args) {
// 如果服务端未设置监听端口,默认是25333;如果通过反射类方式,则无需设置entryPoint
GatewayServer server = new GatewayServer();
server.start();
}
}
Python客户端
from py4j.java_gateway import java_import, JavaGateway
# 如果服务端未设置监听端口,默认是25333
gateway = JavaGateway()
# 1、通过完全限定名反射类
py4jTest = gateway.jvm.org.apache.spark.examples.Py4jTest()
result = py4jTest.addition(1,2)
print(result) # 输出:3
# 2、通过java_import导入package后反射类
java_import(gateway.jvm, "org.apache.spark.examples.*")
py4jTest = gateway.jvm.Py4jTest()
result = py4jTest.addition(1,2)
print(result) # 输出:3
2、PySpark示例
from py4j.java_gateway import java_import, JavaGateway
from pyspark.context import SparkContext
sc = SparkContext('local[*]', 'test')
local_dir = sc._jvm.org.apache.spark.util.Utils.getLocalDir(sc._jsc.sc().conf())
print(local_dir)
java_import(sc._jvm, "java.util.*")
random = sc._jvm.Random()
random_num = random.nextInt(100)
print(random_num)
3、PySpark调用自定义jar
Java代码(编译生成包spark-examples_2.11-2.4.3.jar)
package org.apache.spark.examples;
public class Py4jServerTest {
public int addition(int first, int second) {
return first + second;
}
}
PySpark代码(py4j_client_test.py)
# -*- encoding: utf-8 -*-
from pyspark.context import SparkContext
sc = SparkContext(appName="Py4jTest")
py4jTest = sc._jvm.org.apache.spark.examples.Py4jTest()
result = py4jTest.addition(1,2)
print(result) # 输出:3
提交命令
spark-submit --master yarn --deploy-mode cluster --conf spark.pyspark.python=python3 --driver-class-path spark-examples_2.11-2.4.3.jar --jars spark-examples_2.11-2.4.3.jar py4j_client_test.py
注:由于Py4j只在Driver端有效,Executor端无法使用(例如:在算子中的函数无效)。