Kafka动态修改副本数及遇到的坑
实际项目中我们可能在创建topic时没有设置好正确的replication-factor,导致kafka集群虽然是高可用的,但是该topic在有broker宕机时,可能发生无法使用的情况。topic一旦使用又不能轻易删除重建,因此动态增加副本因子就成为最终的选择。
原因分析:
假设我们有3个kafka broker分别broker0、broker1、broker2.
当我们创建的topic有3个分区partition时并且replication-factor为1,基本上一个broker上一个分区。当一个broker宕机了,该topic就无法使用了,因为三个分区只有两个能用,
当我们创建的topic有3个分区partition时并且replication-factor为2时,可能分区数据分布情况是
broker0, partiton0,partiton1,
broker1, partiton1,partiton2
broker2, partiton2,partiton0,
每个分区有一个副本。
当其中一个broker宕机了,kafka集群还能完整凑出该topic的三个分区,例如当broker0宕机了,可以通过broker1和broker2组合出topic的三个分区。
但是如果两个broker宕机,那kakfa集群就无法凑出该topic的三个分区,例如当broker0和broker1宕机后,只有broker2上partation2和partation0可用,此时partation1处于无法使用的状态。
解决办法:动态增加副本数
首先我们配置topic的副本,保存为json文件()
例如, 我们想把hongjiang-test-0422的副本设置为3,(我的kafka集群有3个broker,id分别为0,1,2), json文件名称为1.json
{"version":1,
"partitions":[
{"topic":"hongjiang-test-0422","partition":0,"replicas":[0,1,2]},
{"topic":"hongjiang-test-0422","partition":1,"replicas":[1,2,0]},
{"topic":"hongjiang-test-0422","partition":2,"replicas":[2,0,1]}
]}
接下来运行
./bin/kafka-reassign-partitions.sh --zookeeper ‘172.20.0.16:12181,172.20.0.15:12181,172.16.10.33:12181’ --reassignment-json-file 1.json --execute
返回结果为:
Current partition replica assignment
{"version":1,"partitions":[{"topic":"hongjiang-test-0422","partition":2,"replicas":[2,0,1],"log_dirs":["any","any","any"]},{"topic":"hongjiang-test-0422","partition":1,"replicas":[1,2,0],"log_dirs":["any","any","any"]},{"topic":"hongjiang-test-0422","partition":0,"replicas":[0,1,2],"log_dirs":["any","any","any"]}]}
Save this to use as the --reassignment-json-file option during rollback
Successfully started reassignment of partitions.
这样的话,就代表成功了
可以通过./bin/kafka-topics.sh --describe --zookeeper 172.20.0.16:12181 --topic hongjiang-test-0422 看到效果
Topic:hongjiang-test-0422 PartitionCount:3 ReplicationFactor:3 Configs:
Topic: hongjiang-test-0422 Partition: 0 Leader: 0 Replicas: 0,1,2 Isr: 0,1,2
Topic: hongjiang-test-0422 Partition: 1 Leader: 1 Replicas: 1,2,0 Isr: 1,2,0
Topic: hongjiang-test-0422 Partition: 2 Leader: 2 Replicas: 2,0,1 Isr: 2,0,1
坑点记录:
Leader Skewed背景知识:
在创建一个topic时,kafka尽量将partition均分在所有的brokers上,并且将replicas也均匀分在不同的broker上。
每个partitiion的所有replicas叫做"assigned replicas",“assigned replicas"中的第一个replicas叫"preferred replica”,刚创建的topic一般"preferred replica"是leader。leader replica负责所有的读写。
但随着时间推移,broker可能会停机,会导致leader迁移,导致集群的负载不均衡。我们期望对topic的leader进行重新负载均衡,让partition选择"preferred replica"做为leader。
还有一种情况也会导致Leader Skewed的倾斜
比如动态修改多副本的时候,是这样写的 replicas:后是0,1,2
{"version":1,
"partitions":[
{"topic":"hongjiang-test-0422","partition":0,"replicas":[0,1,2]},
{"topic":"hongjiang-test-0422","partition":1,"replicas":[0,1,2]},
{"topic":"hongjiang-test-0422","partition":2,"replicas":[0,1,2]}
]}
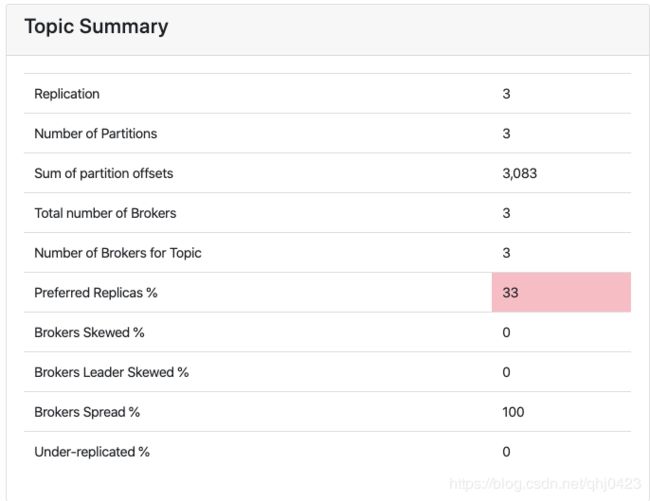
我们上面说了,“assigned replicas"中的第一个replicas叫"preferred replica”。所以此时:“hongjiang-test-0422” 这个topic所在的三个broker的leader replica都是“0”号,这样的话,就会导致读写次topic的负载不均衡。如下图:
Preferred Replicas % 为33%

正确的方式应该是最上面的:
{"version":1,
"partitions":[
{"topic":"hongjiang-test-0422","partition":0,"replicas":[0,1,2]},
{"topic":"hongjiang-test-0422","partition":1,"replicas":[1,2,0]},
{"topic":"hongjiang-test-0422","partition":2,"replicas":[2,0,1]}
]}