主要介绍scikit-learn中的交叉验证
sklearn.learning_curve 中的 learning curve 可以很直观的看出我们的 model 学习的进度, 对比发现有没有 overfitting 的问题. 然后我们可以对我们的 model 进行调整, 克服 overfitting 的问题.
Demo1.py
import numpy as np
import matplotlib.pyplot as plt
from sklearn.datasets import load_digits
from sklearn.cross_validation import train_test_split
from sklearn.svm import SVC
from sklearn.learning_curve import learning_curve
from sklearn.cross_validation import cross_val_score
# 加载数据集
digits = load_digits()
X = digits.data
y = digits.target
# 用SVM进行学习并记录loss
train_sizes, train_loss, test_loss = learning_curve(SVC(gamma = 0.001),
X, y, cv = 10, scoring = 'mean_squared_error',
train_sizes = [0.1, 0.25, 0.5, 0.75, 1])
# 训练误差均值
train_loss_mean = -np.mean(train_loss, axis = 1)
# 测试误差均值
test_loss_mean = -np.mean(test_loss, axis = 1)
# 绘制误差曲线
plt.plot(train_sizes, train_loss_mean, 'o-', color = 'r', label = 'Training')
plt.plot(train_sizes, test_loss_mean, 'o-', color = 'g', label = 'Cross-Validation')
plt.xlabel('Training data size')
plt.ylabel('Loss')
plt.legend(loc = 'best')
plt.show()
结果:
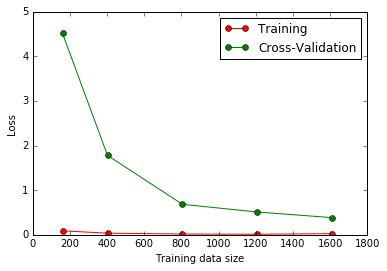
Paste_Image.png
sklearn.learning_curve.learning_curve
- 调用格式是:
learning_curve(estimator, X, y, train_sizes=array([ 0.1 , 0.325, 0.55 , 0.775, 1. ]), cv=None, scoring=None, exploit_incremental_learning=False, n_jobs=1, pre_dispatch=‘all‘, verbose=0) - 函数的作用为:
对于不同大小的训练集,确定交叉验证训练和测试的分数。一个交叉验证发生器将整个数据集分割k次,分割成训练集和测试集。不同大小的训练集的子集将会被用来训练评估器并且对于每一个大小的训练子集都会产生一个分数,然后测试集的分数也会计算。然后,对于每一个训练子集,运行k次之后的所有这些分数将会被平均。
estimator:所使用的分类器
X:array-like, shape (n_samples, n_features) 训练向量,n_samples是样本的数量,n_features是特征的数量
y:array-like, shape (n_samples) or (n_samples, n_features), optional目标相对于X分类或者回归
train_sizes:array-like, shape (n_ticks,), dtype float or int训练样本的相对的或绝对的数字,这些量的样本将会生成learning curve。如果dtype是float,他将会被视为最大数量训练集的一部分(这个由所选择的验证方法所决定)。否则,他将会被视为训练集的绝对尺寸。要注意的是,对于分类而言,样本的大小必须要充分大,达到对于每一个分类都至少包含一个样本的情况。
cv:int, cross-validation generator or an iterable, optional确定交叉验证的分离策略
--None,使用默认的3-fold cross-validation,
--integer,确定是几折交叉验证
--一个作为交叉验证生成器的对象
--一个被应用于训练/测试分离的迭代器
verbose : integer, optional控制冗余:越高,有越多的信息 - 返回值:
train_sizes_abs:array, shape = (n_unique_ticks,), dtype int用于生成learning curve的训练集的样本数。由于重复的输入将会被删除,所以ticks可能会少于n_ticks.
**train_scores **: array, shape (n_ticks, n_cv_folds)在训练集上的分数
test_scores : array, shape (n_ticks, n_cv_folds)在测试集上的分数