拉勾网数据爬取
拉勾网数据爬取
爬取内容
北京数据挖掘方向的岗位数据
方案
正常的
https://www.lagou.com/jobs/list_数据挖掘?px=new&city=上海#order
上面的URL是查询上海数据挖掘岗位的信息并按照最新发布排序

通过抓包分析请求的真正URL是这个
https://www.lagou.com/jobs/positionAjax.json?px=new&city=上海&needAddtionalResult=false&isSchoolJob=0

提交的数据如下

返回的数据的格式如下

太麻烦了使用移动端ua (很赞)
移动端的api往往比pc端的简单
使用360极速浏览器的魔变
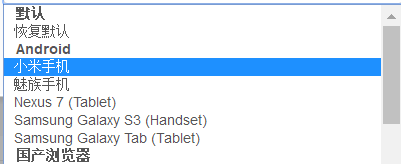
输入网址查看移动端的拉勾网界面,设置查询条件如下

然后用F12抓包分析真正的URL

发送数据的表单
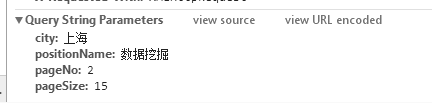
获得数据格式

成果展示

脚本
"""
title:抓取拉勾网的数据
time:2018-01-22
author:No.96
"""
import requests
import time
import random
import csv
# 移动端头部信息
useragents = [
"Mozilla/5.0 (iPhone; CPU iPhone OS 9_2 like Mac OS X) AppleWebKit/601.1 (KHTML, like Gecko) CriOS/47.0.2526.70 Mobile/13C71 Safari/601.1.46",
"Mozilla/5.0 (Linux; U; Android 4.4.4; Nexus 5 Build/KTU84P) AppleWebkit/534.30 (KHTML, like Gecko) Version/4.0 Mobile Safari/534.30",
"Mozilla/5.0 (compatible; MSIE 9.0; Windows Phone OS 7.5; Trident/5.0; IEMobile/9.0)"
]
cookies = {
}
# city城市
# positionName 职位关键字
# pageNo 页码
# pageSize 叶大小
def lagou(city, positionName, pageNo, pageSize):
cookies = {
"Cookie": "user_trace_token=20180122190616-4411246f-ff64-11e7-b4a1-525400f775ce; LGUID=20180122190616-44112bfa-ff64-11e7-b4a1-525400f775ce; X_HTTP_TOKEN=2d753a5ac2b3e6e2423fcb4022407518; gate_login_token=197ff91d128acf987e1608ff3bf9333c3c2c1b88eabfedfb; index_location_city=%E6%9D%AD%E5%B7%9E; PRE_UTM=m_cf_cpt_baidu_pc; PRE_HOST=bzclk.baidu.com; PRE_SITE=http%3A%2F%2Fbzclk.baidu.com%2Fadrc.php%3Ft%3D06KL00c00f7Ghk60yUKm0FNkUsKKdyNp00000PW4pNb00000LbFd7H.THL0oUh11x60UWdBmy-bIy9EUyNxTAT0T1Y3nh7bmvcLmH0snj0LryRk0ZRqPjNKwH0LwbN7fH7Awbw7PjKafRDsfbc3PDPKf1I7n1b0mHdL5iuVmv-b5Hnsn1nznjR1njfhTZFEuA-b5HDv0ARqpZwYTZnlQzqLILT8UA7MULR8mvqVQ1qdIAdxTvqdThP-5ydxmvuxmLKYgvF9pywdgLKW0APzm1YzP10LPf%26tpl%3Dtpl_10085_15730_11224%26l%3D1500117464%26attach%3Dlocation%253D%2526linkName%253D%2525E6%2525A0%252587%2525E9%2525A2%252598%2526linkText%253D%2525E3%252580%252590%2525E6%25258B%252589%2525E5%25258B%2525BE%2525E7%2525BD%252591%2525E3%252580%252591%2525E5%2525AE%252598%2525E7%2525BD%252591-%2525E4%2525B8%252593%2525E6%2525B3%2525A8%2525E4%2525BA%252592%2525E8%252581%252594%2525E7%2525BD%252591%2525E8%252581%25258C%2525E4%2525B8%25259A%2525E6%25259C%2525BA%2526xp%253Did%28%252522m6c247d9c%252522%29%25252FDIV%25255B1%25255D%25252FDIV%25255B1%25255D%25252FDIV%25255B1%25255D%25252FDIV%25255B1%25255D%25252FH2%25255B1%25255D%25252FA%25255B1%25255D%2526linkType%253D%2526checksum%253D220%26ie%3Dutf-8%26f%3D3%26tn%3Dbaiduhome_pg%26wd%3D%25E6%258B%2589%25E9%2592%25A9%25E7%25BD%2591%26oq%3D%2525E6%25258B%252589%2525E5%25258B%2525BE%2525E7%2525BD%252591%2525E7%252588%2525AC%2525E8%252599%2525AB%26rqlang%3Dcn%26prefixsug%3D%2525E6%25258B%252589%2525E9%252592%2525A9%2525E7%2525BD%252591%26rsp%3D1%26inputT%3D277; PRE_LAND=https%3A%2F%2Fwww.lagou.com%2F%3Futm_source%3Dm_cf_cpt_baidu_pc; fromsite=bzclk.baidu.com; utm_source=""; JSESSIONID=ABAAABAAAFDABFG399ECCCCEDB8F54778C63A5054EDD7B0; _putrc=D71643F76AF6F41F; login=true; unick=%E6%9D%A8%E5%87%8C%E9%94%8B; _ga=GA1.2.253347541.1516619174; _gid=GA1.2.2037776006.1516619174; _ga=GA1.3.253347541.1516619174; Hm_lvt_4233e74dff0ae5bd0a3d81c6ccf756e6=1516619174,1516619191,1516623170,1516623176; Hm_lpvt_4233e74dff0ae5bd0a3d81c6ccf756e6=1516623224; LGSID=20180122201252-91c897a5-ff6d-11e7-a5bc-5254005c3644; LGRID=20180122201345-b1ca9540-ff6d-11e7-a5bc-5254005c3644"
}
req_url = "https://m.lagou.com/search.json?"
params = {
"city": city,
"positionName": positionName,
"pageNo": pageNo,
"pageSize": pageSize
}
# 请求头部
headers = {
'Host': 'm.lagou.com',
'Origin': 'https://m.lagou.com/search.html',
'User-Agent': random.choice(useragents)
}
res = requests.get(url=req_url, headers=headers,
params=params, cookies=cookies) # f发送请求
res_json = res.json() # 获取json数据
result = res_json['content']['data']['page']['result']
return result # 返回json数据
# 解析返回的json
def analyze(city, result,writer):
filename = city + '.csv'
for item in result:
job = {
"city": item['city'],
"companyFullName": item['companyFullName'],
"companyName": item['companyName'],
"positionName": item['positionName'],
"salary": item['salary']
}
writer.writerow(job)
if __name__ == "__main__":
city = "上海"
positionName = "数据挖掘"
pageSize = 15
filename = city+'.csv'
with open(filename,'a') as f:
fieldnames = ['city', 'companyFullName','companyName','positionName','salary']
writer = csv.DictWriter(f, fieldnames=fieldnames)
writer.writeheader()
for i in range(10):
result = lagou(city, positionName, i, pageSize)
time.sleep(2)
analyze(city,result,writer)
源码
如果喜欢在给个star
源码地址