算法:二分法查找、数组和链表、选择排序
目录
二分法
python编写二分查找函数binary_search
二分法练习:
选择排序
数组和链表的优缺点
链表的优势、 链表的问题
常见的数组和链表操作的运行时间
需要在中间插入元素时,数组和链表哪个更好呢?
数组和链表哪个用得更多呢
数组和链表习题
选择排序
python代码实现将数组元素按从小到大的顺序排列
小结
二分法
一般而言,对于包含n个元素的列表,用二分查找最多需要log2n步,而简单查找最多需要n步。仅当列表是有序的时候,二分查找才管用。
对数运算是幂运算的逆运算。
大O表示法指出了最糟情况下的运行时间;除最糟情况下的运行时间外,还应考虑平均情况的运行时间。
python编写二分查找函数binary_search
接受一个有序数组和一个元素。如果指定的元素包含在数组中,这个函数将返回其位置。
def binary_search(list, item): # item就是需要猜的数
# low和high用于跟踪要在其中查找的列表部分
low = 0
high = len(list) - 1
while low <= high: # 只要范围没有缩小到只包含一个元素,就检查中间的元素
# ... check the middle element
mid = (low + high) // 2 # 如果(low + high)不是偶数,Python自动将mid向下取整
guess = list[mid] #找到了元素
if guess == item:
return mid
if guess > item: # 如果猜的数字大了,就修改high。
high = mid - 1
else: # 如果猜的数字小了,就相应地修改low。
low = mid + 1
# 没有指定的元素
return None
my_list = [1, 3, 5, 7, 9]
print(binary_search(my_list, 3)) # => 1
# 'None' means nil in Python. We use to indicate that the item wasn't found.
print(binary_search(my_list, -1)) # => None
| O(log n),对数时间, | 二分查找 |
| O(n),线性时间 | 简单查找 |
| O(n * log n) | 快速排序 |
| O(n^2) | 选择排序 |
| O(n!) |
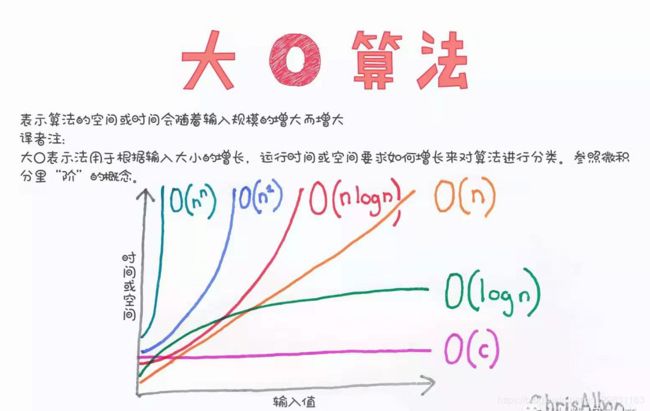
- 算法运行时间并不以秒为单位。它是从其增速的角度度量的。
- 算法的运行时间用大O表示法表示。用大O表示法讨论运行时间时,log指的都是log2。
- 谈论算法的速度时,我们说的是随着输入的增加,其运行时间将以什么样的速度增加。【操作数的增速】
- 二分查找的速度比简单查找快得多。
- O(log n)比O(n)快,当需要搜索的元素越多时,前者比后者快得越多。
二分法练习:
使用大O表示法给出下述各种情形的运行时间。
1.3 在电话簿中根据名字查找电话号码。
1.4 在电话簿中根据电话号码找人。(提示:你必须查找整个电话簿。)
1.5 阅读电话簿中每个人的电话号码。
1.6 阅读电话簿中姓名以A打头的人的电话号码。这个问题比较棘手,它涉及第4章的概念。答案可能让你感到惊讶!
答案:
1.3 O(log n)。
1.4 O(n)。
1.5 O(n)。
1.6 O(n)。你可能认为,我只对26个字母中的一个这样做,因此运行时间应为O(n / 26)。需要牢记的一条简单规则是,大O表示法不考虑乘以、除以、加上或减去的数字。下面这些都不是正确的大O运行时间:O(n + 26)、O(n - 26)、O(n * 26)、O(n / 26),它们都应表示为O(n)!为什么呢?如果你好奇,请研究大O表示法中的常量(常量就是一个数字,这里的26就是常量)。
选择排序
数组和链表的优缺点
需要将数据存储到内存时,你请求计算机提供存储空间,计算机给你一个存储地址。需要存储多项数据时,有两种基本方式——数组和链表。
使用数组意味着存储的数据在内存中都是相连的(紧靠在一起的)。
在数组中添加新元素也可能很麻烦。如果没有了空间,就得移到内存的其他地方,因此添加新元素的速度会很慢。一种解决之道是“预留座位”:即便当前只有3个待办事项,也请计算机提供10个位置,以防需要添加待办事项。这样,只要待办事项不超过10个,就无需转移。这是一个不错的权变措施,但你应该明白,它存在如下两个缺点。
- 你额外请求的位置可能根本用不上,这将浪费内存。
- 你没有使用,别人也用不了。待办事项超过10个后,你还得转移。
链表的优势
链表的每个元素都存储了下一个元素的地址,从而使一系列随机的内存地址串在一起。
在链表中添加元素很容易:只需将其放入内存,并将其地址存储到前一个元素中;使用链表时,根本就不需要移动元素。
因此,只要有足够的内存空间,就能为链表分配内存。链表的优势在插入元素方面。
链表的问题
在需要读取链表的最后一个元素时,你不能直接读取,因为你不知道它所处的地址,必须先访问元素#1,从中获取元素#2的地址,再访问元素#2并从中获取元素#3的地址,以此类推,直到访问最后一个元素。需要同时读取所有元素时,链表的效率很高:你读取第一个元素,根据其中的地址再读取第二个元素,以此类推。但如果你需要跳跃,链表的效率真的很低。
常见的数组和链表操作的运行时间
假设有一个数组,它包含五个元素,起始地址为00,那么元素#5的地址是多少呢? 04

需要随机地读取元素时,数组的效率很高,因为可迅速找到数组的任何元素。
数组的元素带编号,编号从0而不是1开始。元素的位置称为索引。因此,不说“元素20的位置为1”,而说“元素20位于索引1处”。
需要在中间插入元素时,数组和链表哪个更好呢?
【链表是更好的选择。】
- 使用链表时,插入元素很简单,只需修改它前面的那个元素指向的地址。
- 而使用数组时,则必须将后面的元素都向后移。如果没有足够的空间,可能还得将整个数组复制到其他地方!
如果你要删除元素呢?链表也是更好的选择,因为只需修改前一个元素指向的地址即可。而使用数组时,删除元素后,必须将后面的元素都向前移。
不同于插入,删除元素总能成功。如果内存中没有足够的空间,插入操作可能失败,但在任何情况下都能够将元素删除。

仅当能够立即访问要删除的元素时,删除操作的运行时间才为O(1)。通常我们都记录了链表的第一个元素和最后一个元素,因此删除这些元素时运行时间为O(1)。
数组和链表哪个用得更多呢
- 数组支持随机访问,读取速度更快。很多情况都要求能够随机访问,因此数组用得很多
有两种访问方式:随机访问和顺序访问。
- 顺序访问意味着从第一个元素开始逐个地读取元素。链表只能顺序访问:要读取链表的第十个元素,得先读取前九个元素,并沿链接找到第十个元素。
- 随机访问意味着可直接跳到第十个元素。
数组和链表习题

2.1 假设你要编写一个记账的应用程序。每天都将所有的支出记录下来,并在月底统计支出,算算当月花了多少钱。因此,你执行的插入操作很多,但读取操作很少。该使用数组还是链表呢?
2. 2 假设你要为饭店创建一个接受顾客点菜单的应用程序。这个应用程序存储一系列点菜单。服务员添加点菜单,而厨师取出点菜单并制作菜肴。这是一个点菜单队列:服务员在队尾添加点菜单,厨师取出队列开头的点菜单并制作菜肴。你使用数组还是链表来实现这个队列呢?(提示:链表擅长插入和删除,而数组擅长随机访问。在这个应用程序中,你要执行的是哪些操作呢?)
2.3 我们来做一个思考实验。假设Facebook记录一系列用户名,每当有用户试图登录Facebook时,都查找其用户名,如果找到就允许用户登录。由于经常有用户登录Facebook,因此需要执行大量的用户名查找操作。假设Facebook使用二分查找算法,而这种算法要求能够随机访问——立即获取中间的用户名。考虑到这一点,应使用数组还是链表来存储用户名呢?
2.4 经常有用户在Facebook注册。假设你已决定使用数组来存储用户名,在插入方面数组有何缺点呢?具体地说,在数组中添加新用户将出现什么情况?
2.1 在这里,你每天都在列表中添加支出项,但每月只读取支出一次。数组的读取速度快,而插入速度慢;链表的读取速度慢,而插入速度快。由于你执行的插入操作比读取操作多,因此使用链表更合适。另外,仅当你要随机访问元素时,链表的读取速度才慢。鉴于你要读取所有的元素,在这种情况下,链表的读取速度也不慢。因此,对这个问题来说,使用链表是不错的解决方案。
2.2 使用链表。经常要执行插入操作(服务员添加点菜单),而这正是链表擅长的。不需要执行(数组擅长的)查找和随机访问操作,因为厨师总是从队列中取出第一个点菜单。
2.3 有序数组。数组让你能够随机访问——立即获取数组中间的元素,而使用链表无法这样做。要获取链表中间的元素,你必须从第一个元素开始,沿链接逐渐找到这个元素。
2.4 数组的插入速度很慢。另外,要使用二分查找算法来查找用户名,数组必须是有序的。假设有一个名为Adit B的用户在Facebook注册,其用户名将插入到数组末尾,因此每次插入用户名后,你都必须对数组进行排序!
2.5 查找时,其速度比数组慢,但比链表快;而插入时,其速度比数组快,但与链表相当。因此,其查找速度比数组慢,但在各方面都不比链表慢。本书后面将介绍另一种混合数据结构——散列表。这个练习应该能让你对如何使用简单数据结构创建复杂的数据结构有大致了解。Facebook实际使用的是什么呢?很可能是十多个数据库,它们基于众多不同的数据结构:散列表、B树等。数组和链表是这些更复杂的数据结构的基石。
选择排序
假设你的计算机存储了很多乐曲。对于每个乐队,你都记录了其作品被播放的次数。你要将这个列表按播放次数从多到少的顺序排列,从而将你喜欢的乐队排序。该如何做呢?
一种办法是遍历这个列表,找出作品播放次数最多的乐队,并将该乐队添加到一个新列表中。再找出播放次数第二多的乐队。重复操作以得到一个有序列表。需要的总时间为O(n × n),即O(n^2).
第一次需要检查n个元素,但随后检查的元素数依次为n - 1, n – 2, ..., 2和1,随着排序的进行,每次需要检查的元素数在逐渐减少,最后一次需要检查的元素都只有一个。平均每次检查的元素数为1/2 × n,因此运行时间为O(n × 1/2 × n)。可运行时间怎么还是O(n2)呢?这与大O表示法中的常数相关。但大O表示法省略诸如1/2这样的常数‘。
选择排序是一种灵巧的算法,但其速度不是很快。快速排序是一种更快的排序算法,其运行时间为O(n log n),
python代码实现将数组元素按从小到大的顺序排列
先编写一个用于找出数组中最小元素的函数。
def findSmallest(arr):
smallest = arr[0] ←------存储最小的值
smallest_index = 0 ←------存储最小元素的索引
for i in range(1, len(arr)):
if arr[i] < smallest:
smallest = arr[i]
smallest_index = i
return smallest_index
再使用这个函数来编写选择排序算法。
def selectionSort(arr): ←------对数组进行排序
newArr = []
for i in range(len(arr)):
smallest = findSmallest(arr) ←------找出数组中最小的元素,并将其加入到新数组中
newArr.append(arr.pop(smallest))
return newArrprint
selectionSort([5, 3, 6, 2, 10])小结
- 需要存储多个元素时,可使用数组或链表。
- 数组的元素都在一起。 数组的读取速度很快。
- 链表的元素是分开的,其中每个元素都存储了下一个元素的地址。链表的插入和删除速度很快。
- 在同一个数组中,所有元素的类型都必须相同(都为int、double等)。