简单提升pandas技巧:如何降低内存占用率
前言
pandas是一个Python软件库,可用于数据分析和操作。本文记录实现一些降低内存占用的简单方法。
当使用pandas操作小规模数据(低于100MB)时,性能一般不是问题。而当面对更大规模的数据(100MB到GB)时,性能问题会导致运行时间变得更长,甚至有可能因为内存问题导致运行失败。比如前段时间我用pandas读取数千张表,使用python自带读取方法明显比pandas快很多。
尽管Spark这样的工具可以处理大型数据集(100GB到TB),但是完全利用他们的性能,往往需要硬件的支持,相比pandas数据的处理,pandas更加灵活,所以对于中规模的数据我们尽量使用pandas。
代码实验
- 导入数据
import pandas as pd
gl = pd.read_csv('game_logs.csv')我们可以使用 DataFrame.info() 方法为我们提供关于 dataframe 的高层面信息,包括它的大小、数据类型的信息和内存使用情况。
默认情况下,pandas 会近似 dataframe 的内存用量以节省时间。因为我们也关心准确度,所以我们将 memory_usage 参数设置为 ‘deep’,以便得到准确的数字。
gl.info(memory_usage='deep')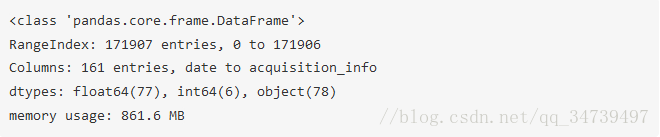
我们可以看到,我们有 171,907 行和 161 列。pandas 会自动为我们检测数据类型,发现其中有 83 列数据是数值,78 列是 object。object 是指有字符串或包含混合数据类型的情况。
为了更好地理解如何减少内存用量,让我们看看 pandas 是如何将数据存储在内存中的。
- dataframe 的内部表示
在 pandas 内部,同样数据类型的列会组织成同一个值块(blocks of values)。这里给出了一个示例,说明了 pandas 对我们的 dataframe 的前 12 列的存储方式。
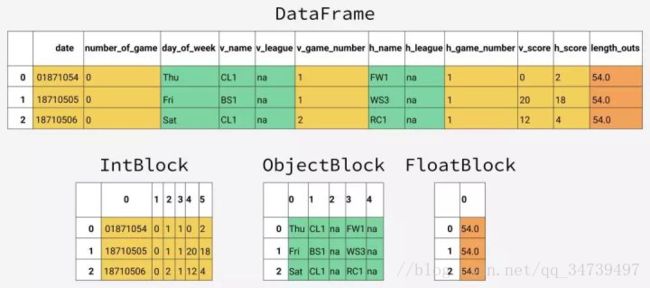
你可以看到这些块并没有保留原有的列名称。这是因为这些块为存储 dataframe 中的实际值进行了优化。pandas 的 BlockManager 类则负责保留行列索引与实际块之间的映射关系。它可以作为一个 API 使用,提供了对底层数据的访问。不管我们何时选择、编辑或删除这些值,dataframe 类和 BlockManager 类的接口都会将我们的请求翻译成函数和方法的调用。
在 pandas.core.internals 模块中,每一种类型都有一个专门的类。pandas 使用 ObjectBlock 类来表示包含字符串列的块,用 FloatBlock 类表示包含浮点数列的块。对于表示整型数和浮点数这些数值的块,pandas 会将这些列组合起来,存储成 NumPy ndarray。NumPy ndarray 是围绕 C 语言的数组构建的,其中的值存储在内存的连续块中。这种存储方案使得对值的访问速度非常快。
因为每种数据类型都是分开存储的,所以我们将检查不同数据类型的内存使用情况。首先,我们先来看看各个数据类型的平均内存用量。
for dtype in ['float','int','object']:
selected_dtype = gl.select_dtypes(include=[dtype])
mean_usage_b = selected_dtype.memory_usage(deep=True).mean()
mean_usage_mb = mean_usage_b / 1024 ** 2
print("Average memory usage for {} columns: {:03.2f} MB".format(dtype,mean_usage_mb))
可以看出,78 个 object 列所使用的内存量最大。我们后面再具体谈这个问题。首先我们看看能否改进数值列的内存用量。
- 理解子类型(subtype)
正如我们前面简单提到的那样,pandas 内部将数值表示为 NumPy ndarrays,并将它们存储在内存的连续块中。这种存储模式占用的空间更少,而且也让我们可以快速访问这些值。因为 pandas 表示同一类型的每个值时都使用同样的字节数,而 NumPy ndarray 可以存储值的数量,所以 pandas 可以快速准确地返回一个数值列所消耗的字节数。
pandas 中的许多类型都有多个子类型,这些子类型可以使用更少的字节来表示每个值。比如说 float 类型就包含 float16、float32 和 float64 子类型。类型名称中的数字就代表该类型表示值的位(bit)数。比如说,我们刚刚列出的子类型就分别使用了 2、4、8、16 个字节。下面的表格给出了 pandas 中最常用类型的子类型:
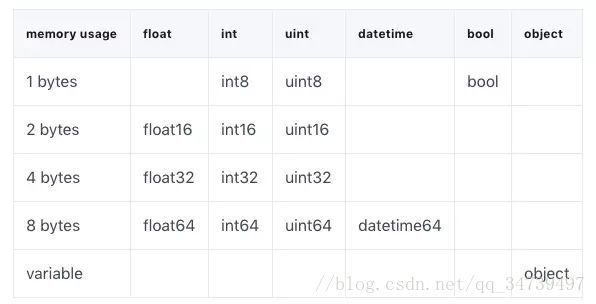
一个 int8 类型的值使用 1 个字节的存储空间,可以表示 256(2^8)个二进制数。这意味着我们可以使用这个子类型来表示从 -128 到 127(包括 0)的所有整数值。
我们可以使用 numpy.iinfo 类来验证每个整型数子类型的最大值和最小值。举个例子:
import numpy as np
int_types = ["uint8", "int8", "int16"]
for it in int_types:
print(np.iinfo(it))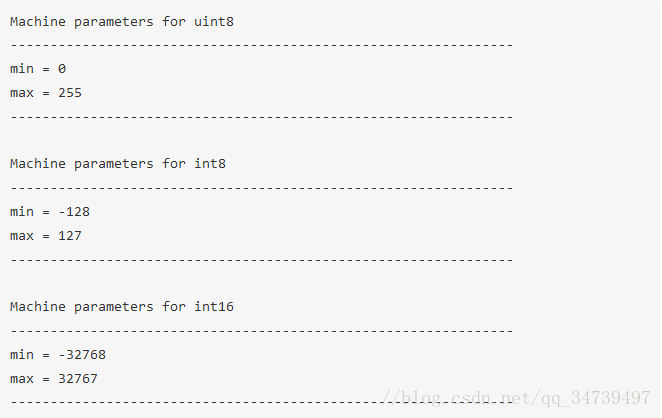
这里我们可以看到 uint(无符号整型)和 int(有符号整型)之间的差异。这两种类型都有一样的存储能力,但其中一个只保存 0 和正数。无符号整型让我们可以更有效地处理只有正数值的列。
使用子类型优化数值列
我们可以使用函数 pd.to_numeric() 来对我们的数值类型进行 downcast(向下转型)操作。我们会使用 DataFrame.select_dtypes 来选择整型列,然后我们会对其数据类型进行优化,并比较内存用量。


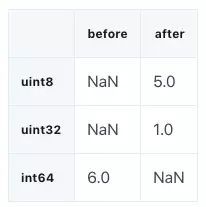
我们可以看到内存用量从 7.9 MB 下降到了 1.5 MB,降低了 80% 以上。但这对我们原有 dataframe 的影响并不大,因为其中的整型列非常少。
让我们对其中的浮点型列进行一样的操作。
gl_float = gl.select_dtypes(include=['float'])
converted_float = gl_float.apply(pd.to_numeric,downcast='float')
print(mem_usage(gl_float))
print(mem_usage(converted_float))
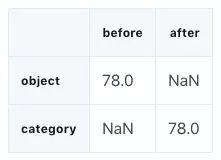
compare_floats = pd.concat([gl_float.dtypes,converted_float.dtypes],axis=1)
compare_floats.columns = ['before','after']
compare_floats.apply(pd.Series.value_counts)
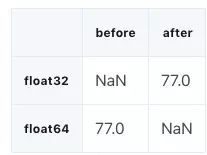
我们可以看到浮点型列的数据类型从 float64 变成了 float32,让内存用量降低了 50%。
让我们为原始 dataframe 创建一个副本,并用这些优化后的列替换原来的列,然后看看我们现在的整体内存用量。
optimized_gl = gl.copy()
optimized_gl[converted_int.columns] = converted_int
optimized_gl[converted_float.columns] = converted_float
print(mem_usage(gl))
print(mem_usage(optimized_gl))
尽管我们极大地减少了数值列的内存用量,但整体的内存用量仅减少了 7%。我们的大部分收获都将来自对 object 类型的优化。
在我们开始行动之前,先看看 pandas 中字符串的存储方式与数值类型的存储方式的比较。
- 数值存储与字符串存储的比较
object 类型表示使用 Python 字符串对象的值,部分原因是 NumPy 不支持缺失(missing)字符串类型。因为 Python 是一种高级的解释性语言,它对内存中存储的值没有细粒度的控制能力。
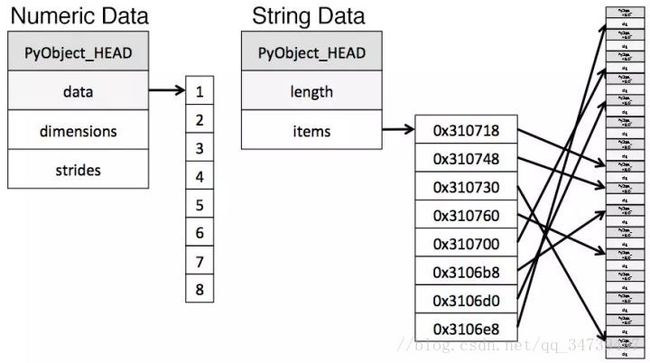
这一限制导致字符串的存储方式很碎片化,从而会消耗更多内存,而且访问速度也更慢。object 列中的每个元素实际上都是一个指针,包含了实际值在内存中的位置的「地址」。
下面这幅图给出了以 NumPy 数据类型存储数值数据和使用 Python 内置类型存储字符串数据的方式。
from sys import getsizeof
s1 = 'working out'
s2 = 'memory usage for'
s3 = 'strings in python is fun!'
s4 = 'strings in python is fun!'
for s in [s1, s2, s3, s4]:
print(getsizeof(s))
obj_series = pd.Series(['working out',
'memory usage for',
'strings in python is fun!',
'strings in python is fun!'])
obj_series.apply(getsizeof)
- 使用 Categoricals 优化 object 类型
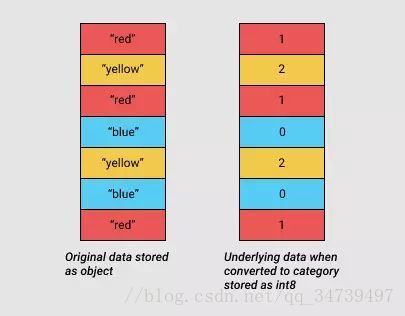
pandas 在 0.15 版引入了 Categorials。category 类型在底层使用了整型值来表示一个列中的值,而不是使用原始值。pandas 使用一个单独的映射词典将这些整型值映射到原始值。只要当一个列包含有限的值的集合时,这种方法就很有用。当我们将一列转换成 category dtype 时,pandas 就使用最节省空间的 int 子类型来表示该列中的所有不同值。
.
为了了解为什么我们可以使用这种类型来减少内存用量,让我们看看我们的 object 类型中每种类型的不同值的数量。
gl_obj = gl.select_dtypes(include=['object']).copy()
gl_obj.describe()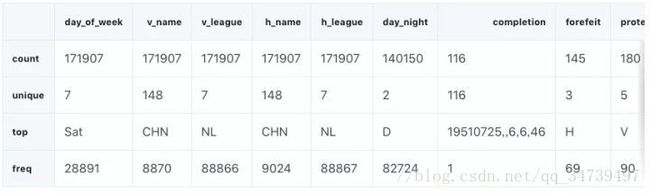
大概看看就能发现,对于我们整个数据集的 172,000 场比赛,其中不同(unique)值的数量可以说非常少。
为了了解当我们将其转换成 categorical 类型时究竟发生了什么,我们拿出一个 object 列来看看。我们将使用数据集的第二列 day_of_week.
看看上表,可以看到其仅包含 7 个不同的值。我们将使用 .astype() 方法将其转换成 categorical 类型。
dow_cat.head().cat.codes

在这个案例中,所有的 object 列都被转换成了 category 类型,但并非所有数据集都是如此,所以你应该使用上面的流程进行检查。
object 列的内存用量从 752MB 减少到了 52MB,减少了 93%。让我们将其与我们 dataframe 的其它部分结合起来,看看从最初 861MB 的基础上实现了多少进步。
optimized_gl[converted_obj.columns] = converted_obj
mem_usage(optimized_gl)![]()
Wow,进展真是不错!我们还可以执行另一项优化——如果你记得前面给出的数据类型表,你知道还有一个 datetime 类型。这个数据集的第一列就可以使用这个类型。
date = optimized_gl.date
print(mem_usage(date))
date.head()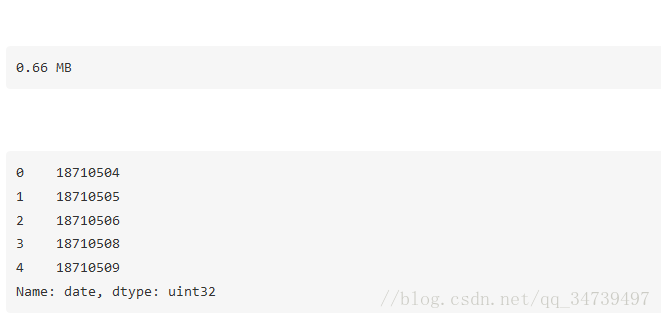
你可能记得这一列开始是一个整型,现在已经优化成了 unint32 类型。因此,将其转换成 datetime 类型实际上会让内存用量翻倍,因为 datetime 类型是 64 位的。将其转换成 datetime 类型是有价值的,因为这让我们可以更好地进行时间序列分析。
pandas.to_datetime() 函数可以帮我们完成这种转换,使用其 format 参数将我们的日期数据存储成 YYYY-MM-DD 形式。
optimized_gl['date'] = pd.to_datetime(date,format='%Y%m%d')
print(mem_usage(optimized_gl))
optimized_gl.date.head()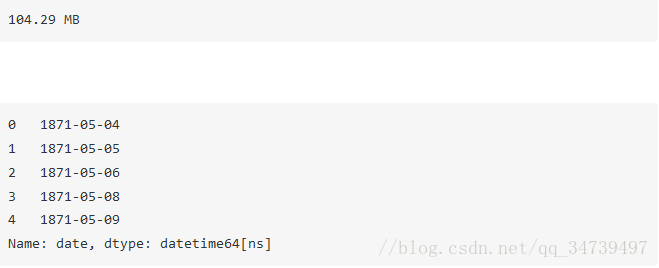
- 在读入数据的同时选择类型
现在,我们已经探索了减少现有 dataframe 的内存占用的方法。通过首先读入 dataframe,然后在这个过程中迭代以减少内存占用,我们了解了每种优化方法可以带来的内存减省量。但是正如我们前面提到的一样,我们往往没有足够的内存来表示数据集中的所有值。如果我们一开始甚至无法创建 dataframe,我们又可以怎样应用节省内存的技术呢?
幸运的是,我们可以在读入数据的同时指定最优的列类型。pandas.read_csv() 函数有几个不同的参数让我们可以做到这一点。dtype 参数接受具有(字符串)列名称作为键值(key)以及 NumPy 类型 object 作为值的词典。
首先,我们可将每一列的最终类型存储在一个词典中,其中键值表示列名称,首先移除日期列,因为日期列需要不同的处理方式。
dtypes = optimized_gl.drop('date',axis=1).dtypes
dtypes_col = dtypes.index
dtypes_type = [i.name for i in dtypes.values]
column_types = dict(zip(dtypes_col, dtypes_type))
# rather than print all 161 items, we'll
# sample 10 key/value pairs from the dict
# and print it nicely using prettyprint
preview = first2pairs = {key:value for key,value in list(column_types.items())[:10]}
import pprint
pp = pp = pprint.PrettyPrinter(indent=4)
pp.pprint(preview)
现在我们可以使用这个词典了,另外还有几个参数可用于按正确的类型读入日期,而且仅需几行代码:
read_and_optimized = pd.read_csv('game_logs.csv',dtype=column_types,parse_dates=['date'],infer_datetime_format=True)
print(mem_usage(read_and_optimized))
read_and_optimized.head()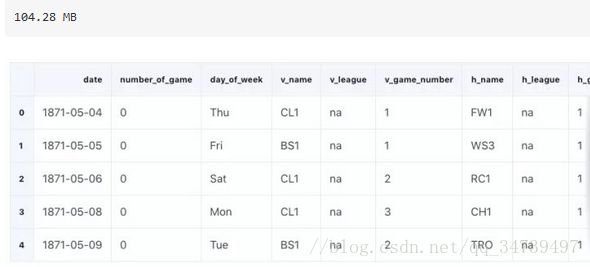
通过优化这些列,我们成功将 pandas 的内存占用从 861.6MB 减少到了 104.28MB——减少了惊人的 88%!
总结
我们已经了解了 pandas 使用不同数据类型的方法,然后我们使用这种知识将一个 pandas dataframe 的内存用量减少了近 90%,而且也仅使用了一些简单的技术:
将数值列向下转换成更高效的类型
将字符串列转换成 categorical 类型
其实第二种方法与R语言中的因子有异曲同工之妙!
转自:https://zhuanlan.zhihu.com/p/34420427?utm_source=qq&utm_medium=social