深度学习笔记(五)---损失函数与优化器
以下笔记来源:
[1] . 《pytorch深度学习实战》
[2] .pytorch 损失函数总结 (https://blog.csdn.net/jacke121/article/details/82812218)
[3] .PyTorch学习之十种优化函数(https://blog.csdn.net/shanglianlm/article/details/85019633)
如有侵权,请联系删除!
pytorch框架中损失函数与优化器介绍:
目录
1. 损失函数:
1.1 nn.L1Loss
1.2 nn.SmoothL1Loss
1.3 nn.MSELoss
1.4 nn.BCELoss
1.5 nn.CrossEntropyLoss
1.6 nn.NLLLoss
1.7 nn.NLLLoss2d
2.优化器Optim
2.1 使用
2.2 基类 Optimizer
2.3 方法
3. 优化算法
3.1 随机梯度下降算法 SGD算法
3-2 平均随机梯度下降算法 ASGD算法
3-3 Adagrad算法
3-4 自适应学习率调整 Adadelta算法
3-5 RMSprop算法
3-6 自适应矩估计 Adam算法
3-7 Adamax算法(Adamd的无穷范数变种)
3-8 SparseAdam算法
3-9 L-BFGS算法
3-10 弹性反向传播算法 Rprop算法
1. 损失函数:
损失函数,又叫目标函数,是编译一个神经网络模型必须的两个参数之一。另一个必不可少的参数是优化器。
损失函数是指用于计算标签值和预测值之间差异的函数,在机器学习过程中,有多种损失函数可供选择,典型的有距离向量,绝对值向量等。
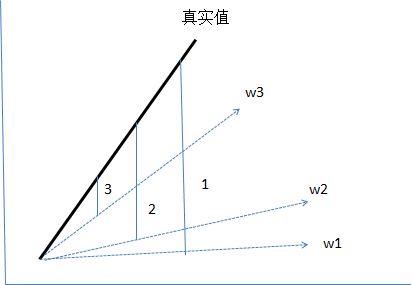
上图是一个用来模拟线性方程自动学习的示意图。粗线是真实的线性方程,虚线是迭代过程的示意,w1 是第一次迭代的权重,w2 是第二次迭代的权重,w3 是第三次迭代的权重。随着迭代次数的增加,我们的目标是使得 wn 无限接近真实值。
那么怎么让 w 无限接近真实值呢?其实这就是损失函数和优化器的作用了。图中 1/2/3 这三个标签分别是 3 次迭代过程中预测 Y 值和真实 Y 值之间的差值(这里差值就是损失函数的意思了,当然了,实际应用中存在多种差值计算的公式),这里的差值示意图上是用绝对差来表示的,那么在多维空间时还有平方差,均方差等多种不同的距离计算公式,也就是损失函数了,这么一说是不是容易理解了呢?
这里示意的是一维度方程的情况,那么发挥一下想象力,扩展到多维度,是不是就是深度学习的本质了?
下面介绍几种常见的损失函数的计算方法,pytorch 中定义了很多类型的预定义损失函数,需要用到的时候再学习其公式也不迟。
我们先定义两个二维数组,然后用不同的损失函数计算其损失值。
import torch
from torch.autograd import Variable
import torch.nn as nn
import torch.nn.functional as F
sample = Variable(torch.ones(2,2))
a=torch.Tensor(2,2)
a[0,0]=0
a[0,1]=1
a[1,0]=2
a[1,1]=3
target = Variable (a)sample 的值为:[[1,1],[1,1]]。
target 的值为:[[0,1],[2,3]]。
1.1 nn.L1Loss
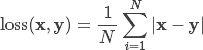
L1Loss 计算方法很简单,取预测值和真实值的绝对误差的平均数即可。
criterion = nn.L1Loss()
loss = criterion(sample, target)
print(loss)最后结果是:1。
它的计算逻辑是这样的:
- 先计算绝对差总和:|0-1|+|1-1|+|2-1|+|3-1|=4;
- 然后再平均:4/4=1。
1.2 nn.SmoothL1Loss
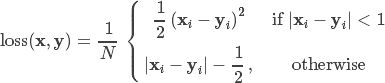
SmoothL1Loss 也叫作 Huber Loss,误差在 (-1,1) 上是平方损失,其他情况是 L1 损失。
criterion = nn.SmoothL1Loss()
loss = criterion(sample, target)
print(loss)最后结果是:0.625。
1.3 nn.MSELoss
平方损失函数。其计算公式是预测值和真实值之间的平方和的平均数。
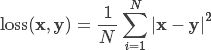
criterion = nn.MSELoss()
loss = criterion(sample, target)
print(loss)最后结果是:1.5。
1.4 nn.BCELoss
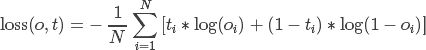
二分类用的交叉熵,其计算公式较复杂,这里主要是有个概念即可,一般情况下不会用到。
criterion = nn.BCELoss()
loss = criterion(sample, target)
print(loss)最后结果是:-13.8155。
1.5 nn.CrossEntropyLoss
交叉熵损失函数
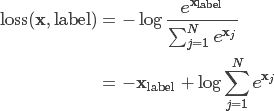
该公式用的也较多,比如在图像分类神经网络模型中就常常用到该公式。
criterion = nn.CrossEntropyLoss()
loss = criterion(sample, target)
print(loss)最后结果是:报错,看来不能直接这么用!
看文档我们知道 nn.CrossEntropyLoss 损失函数是用于图像识别验证的,对输入参数有各式要求,这里有这个概念就可以了,在图像识别一文中会有正确的使用方法。
1.6 nn.NLLLoss
负对数似然损失函数(Negative Log Likelihood)
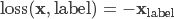
在前面接上一个 LogSoftMax 层就等价于交叉熵损失了。注意这里的 xlabel 和上个交叉熵损失里的不一样,这里是经过 log 运算后的数值。这个损失函数一般也是用在图像识别模型上。
criterion = F.nll_loss()
loss = criterion(sample, target)
print(loss)
loss=F.nll_loss(sample,target)最后结果会报错!
Nn.NLLLoss 和 nn.CrossEntropyLoss 的功能是非常相似的!通常都是用在多分类模型中,实际应用中我们一般用 NLLLoss 比较多。
1.7 nn.NLLLoss2d
和上面类似,但是多了几个维度,一般用在图片上。
input, (N, C, H, W)
target, (N, H, W)比如用全卷积网络做分类时,最后图片的每个点都会预测一个类别标签。
criterion = nn.NLLLoss2d()
loss = criterion(sample, target)
print(loss)同样结果报错!
2.优化器Optim
所有的优化函数都位于torch.optim包下,常用的优化器有:SGD,Adam,Adadelta,Adagrad,Adamax等,下面就各优化器分析。
2.1 使用
optimizer = optim.SGD(model.parameters(), lr = 0.01, momentum=0.9)
optimizer = optim.Adam([var1, var2], lr = 0.0001)- lr:学习率,大于0的浮点数
- momentum:动量参数,大于0的浮点数
- parameters:Variable参数,要优化的对象
2.2 基类 Optimizer
torch.optim.Optimizer(params, defaults)- params (iterable) —— Variable 或者 dict的iterable。指定了什么参数应当被优化。
- defaults —— (dict):包含了优化选项默认值的字典(一个参数组没有指定的参数选项将会使用默认值)。
2.3 方法:
- load_state_dict(state_dict):加载optimizer状态。
- state_dict():以dict返回optimizer的状态。包含两项:state - 一个保存了当前优化状态的dict,param_groups - 一个包含了全部参数组的dict。
- add_param_group(param_group):给 optimizer 管理的参数组中增加一组参数,可为该组参数定制 lr,momentum, weight_decay 等,在 finetune 中常用。
- step(closure) :进行单次优化 (参数更新)。
- zero_grad() :清空所有被优化过的Variable的梯度。
3. 优化算法
3.1 随机梯度下降算法 SGD算法
SGD就是每一次迭代计算mini-batch的梯度,然后对参数进行更新,是最常见的优化方法了。即:
torch.optim.SGD(params, lr=, momentum=0, dampening=0, weight_decay=0, nesterov=False)- params (iterable) :待优化参数的iterable或者是定义了参数组的dict
- lr (float) :学习率
- momentum (float, 可选) :动量因子(默认:0)
- weight_decay (float, 可选) :权重衰减(L2惩罚)(默认:0)
- dampening (float, 可选) :动量的抑制因子(默认:0)
- nesterov (bool, 可选) :使用Nesterov动量(默认:False)
可实现 SGD 优化算法,带动量 SGD 优化算法,带 NAG(Nesterov accelerated gradient)动量 SGD 优化算法,并且均可拥有 weight_decay 项。
- 对于训练数据集,我们首先将其分成n个batch,每个batch包含m个样本。我们每次更新都利用一个batch的数据,而非整个数据集。这样做使得训练数据太大时,利用整个数据集更新往往时间上不现实。batch的方法可以减少机器的压力,并且可以快速收敛。
- 当训练集有冗余时,batch方法收敛更快。
优缺点:
SGD完全依赖于当前batch的梯度,所以η可理解为允许当前batch的梯度多大程度影响参数更新。对所有的参数更新使用同样的learning rate,选择合适的learning rate比较困难,容易收敛到局部最优。
3-2 平均随机梯度下降算法 ASGD算法
ASGD 就是用空间换时间的一种 SGD。
torch.optim.ASGD(params, lr=0.01, lambd=0.0001, alpha=0.75, t0=1000000.0, weight_decay=0)
- params (iterable) :待优化参数的iterable或者是定义了参数组的dict
- lr (float, 可选) : 学习率(默认:1e-2)
- lambd (float, 可选) :衰减项(默认:1e-4)
- alpha (float, 可选) :eta更新的指数(默认:0.75)
- t0 (float, 可选) :指明在哪一次开始平均化(默认:1e6)
- weight_decay (float, 可选) :权重衰减(L2惩罚)(默认: 0)
3-3 Adagrad算法
AdaGrad算法就是将每一个参数的每一次迭代的梯度取平方累加后在开方,用全局学习率除以这个数,作为学习率的动态更新。
其中,r为梯度累积变量,r的初始值为0。ε为全局学习率,需要自己设置。δ为小常数,为了数值稳定大约设置为10^-7 。
torch.optim.Adagrad(params, lr=0.01, lr_decay=0, weight_decay=0)
- params (iterable) :待优化参数的iterable或者是定义了参数组的dict
- lr (float, 可选) :学习率(默认: 1e-2)
- lr_decay (float, 可选) :学习率衰减(默认: 0)
- weight_decay (float, 可选) : 权重衰减(L2惩罚)(默认: 0)
优缺点:
Adagrad 是一种自适应优化方法,是自适应的为各个参数分配不同的学习率。这个学习率的变化,会受到梯度的大小和迭代次数的影响。梯度越大,学习率越小;梯度越小,学习率越大。缺点是训练后期,学习率过小,因为 Adagrad 累加之前所有的梯度平方作为分母。随着算法不断迭代,r会越来越大,整体的学习率会越来越小。所以,一般来说AdaGrad算法一开始是激励收敛,到了后面就慢慢变成惩罚收敛,速度越来越慢。在深度学习算法中,深度过深会造成训练提早结束。
3-4 自适应学习率调整 Adadelta算法
Adadelta是对Adagrad的扩展,主要针对三个问题:
- 学习率后期非常小的问题;
- 手工设置初始学习率;
- 更新xt时,两边单位不统一
针对以上的三个问题,Adadelta提出新的Adag解决方法。Adagrad会累加之前所有的梯度平方,而Adadelta只累加固定大小的项,并且也不直接存储这些项,仅仅是近似计算对应的平均值。
torch.optim.Adadelta(params, lr=1.0, rho=0.9, eps=1e-06, weight_decay=0)
- params (iterable) :待优化参数的iterable或者是定义了参数组的dict
- rho (float, 可选) : 用于计算平方梯度的运行平均值的系数(默认:0.9)
- eps (float, 可选): 为了增加数值计算的稳定性而加到分母里的项(默认:1e-6)
- lr (float, 可选): 在delta被应用到参数更新之前对它缩放的系数(默认:1.0)
- weight_decay (float, 可选) :权重衰减(L2惩罚)(默认: 0)
优缺点:
Adadelta已经不依赖于全局学习率。训练初中期,加速效果不错,很快,训练后期,反复在局部最小值附近抖动。
3-5 RMSprop算法
RMSprop 和 Adadelta 一样,也是对 Adagrad 的一种改进。 RMSprop 采用均方根作为分
母,可缓解 Adagrad 学习率下降较快的问题, 并且引入均方根,可以减少摆动。
torch.optim.RMSprop(params, lr=0.01, alpha=0.99, eps=1e-08, weight_decay=0, momentum=0, centered=False)
- params (iterable) :待优化参数的iterable或者是定义了参数组的dict
- lr (float, 可选) :学习率(默认:1e-2)
- momentum (float, 可选) : 动量因子(默认:0)
- alpha (float, 可选) : 平滑常数(默认:0.99)
- eps (float, 可选) : 为了增加数值计算的稳定性而加到分母里的项(默认:1e-8)
- centered (bool, 可选):如果为True,计算中心化的RMSProp,并且用它的方差预测值对梯度进行归一化
- weight_decay (float, 可选):权重衰减(L2惩罚)(默认: 0)
3-6 自适应矩估计 Adam算法
torch.optim.Adam(params, lr=0.001, betas=(0.9, 0.999), eps=1e-08, weight_decay=0)
- params (iterable) – 待优化参数的iterable或者是定义了参数组的dict
- lr (float, 可选) – 学习率(默认:1e-3)
- betas (Tuple[float, float], 可选) – 用于计算梯度以及梯度平方的运行平均值的系数(默认:0.9,0.999)
- eps (float, 可选) – 为了增加数值计算的稳定性而加到分母里的项(默认:1e-8)
- weight_decay (float, 可选) – 权重衰减(L2惩罚)(默认: 0)
优缺点:
Adam的优点主要在于经过偏置校正后,每一次迭代学习率都有个确定范围,使得参数比较平稳。
Adam结合了Adagrad善于处理稀疏梯度和RMSprop善于处理非平稳目标的优点。
3-7 Adamax算法(Adamd的无穷范数变种)
Adamax 是对 Adam 增加了一个学习率上限的概念,所以也称之为 Adamax。
torch.optim.Adamax(params, lr=0.002, betas=(0.9, 0.999), eps=1e-08, weight_decay=0)
- params (iterable) – 待优化参数的iterable或者是定义了参数组的dict
- lr (float, 可选) – 学习率(默认:2e-3)
- betas (Tuple[float, float], 可选) – 用于计算梯度以及梯度平方的运行平均值的系数
- eps (float, 可选) – 为了增加数值计算的稳定性而加到分母里的项(默认:1e-8)
- weight_decay (float, 可选) – 权重衰减(L2惩罚)(默认: 0)
优缺点:
- Adamax是Adam的一种变体,此方法对学习率的上限提供了一个更简单的范围。
- Adamax学习率的边界范围更简单。
3-8 SparseAdam算法
针对稀疏张量的一种“阉割版”Adam 优化方法。
torch.optim.SparseAdam(params, lr=0.001, betas=(0.9, 0.999), eps=1e-08)
- params (iterable) – 待优化参数的iterable或者是定义了参数组的dict
- lr (float, 可选) – 学习率(默认:2e-3)
- betas (Tuple[float, float], 可选) – 用于计算梯度以及梯度平方的运行平均值的系数
- eps (float, 可选) – 为了增加数值计算的稳定性而加到分母里的项(默认:1e-8)
3-9 L-BFGS算法
L-BFGS 属于拟牛顿算法。 L-BFGS 是对 BFGS 的改进,特点就是节省内存。
torch.optim.LBFGS(params, lr=1, max_iter=20, max_eval=None,
tolerance_grad=1e-05, tolerance_change=1e-09,
history_size=100, line_search_fn=None)
- lr (float) – 学习率(默认:1)
- max_iter (int) – 每一步优化的最大迭代次数(默认:20))
- max_eval (int) – 每一步优化的最大函数评价次数(默认:max * 1.25)
- tolerance_grad (float) – 一阶最优的终止容忍度(默认:1e-5)
- tolerance_change (float) – 在函数值/参数变化量上的终止容忍度(默认:1e-9)
- history_size (int) – 更新历史的大小(默认:100)
3-10 弹性反向传播算法 Rprop算法
该优化方法适用于 full-batch,不适用于 mini-batch。不推荐。
torch.optim.Rprop(params, lr=0.01, etas=(0.5, 1.2), step_sizes=(1e-06, 50))
- params (iterable) – 待优化参数的iterable或者是定义了参数组的dict
- lr (float, 可选) – 学习率(默认:1e-2)
- etas (Tuple[float, float], 可选) – 一对(etaminus,etaplis), 它们分别是乘法的增加和减小的因子(默认:0.5,1.2)
- step_sizes (Tuple[float, float], 可选) – 允许的一对最小和最大的步长(默认:1e-6,50)
优缺点:
该优化方法适用于 full-batch,不适用于 mini-batch。