1 混淆矩阵(Confusion Matrix)
对于二分类问题,预测模型会对每一个样本预测一个得分s或者一个概率p。 然后,可以选取一个阈值t,让得分s>t的样本预测为正,而得分s 显然,混淆矩阵包含四部分的信息: True positive(TP),称为真阳率,表明实际是正样本预测成正样本的样本数 False positive(FP),称为假阳率,表明实际是负样本预测成正样本的样本数 False negative(FN),称为假阴率,表明实际是正样本预测成负样本的样本数 True negative(TN),称为真阴率,表明实际是负样本预测成负样本的样本数 对照着混淆矩阵,很容易就能把关系、概念理清楚,但是久而久之,也很容易忘记概念。不妨我们按照位置前后分为两部分记忆,前面的部分是True/False表示真假,即代表着预测的正确性,后面的部分是positive/negative表示正负样本,即代表着预测的结果,所以,混淆矩阵即可表示为正确性-预测结果的集合。现在我们再来看上述四个部分的概念(均代表样本数,下述省略): TN,预测是负样本,预测对了 FP,预测是正样本,预测错了 FN,预测是负样本,预测错了 TP,预测是正样本,预测对了 几乎我所知道的所有评价指标,都是建立在混淆矩阵基础上的,包括准确率、精准率、召回率、F1-score,当然也包括AUC。 AccuracyRate(准确率): (TP+TN)/(TP+TN+FN+FP) ErrorRate(误分率): (FN+FP)/(TP+TN+FN+FP) Recall(召回率,查全率,击中概率): TP/(TP+FN), 在所有GroundTruth为正样本中有多少被识别为正样本了; Precision(查准率):TP/(TP+FP),在所有识别成正样本中有多少是真正的正样本; TPR(TruePositive Rate): TP/(TP+FN),实际就是Recall FAR(FalseAcceptance Rate)或FPR(False Positive Rate):FP/(FP+TN), 错误接收率,误报率,在所有GroundTruth为负样本中有多少被识别为正样本了; FRR(FalseRejection Rate): FN/(TP+FN),错误拒绝率,拒真率,在所有GroundTruth为正样本中有多少被识别为负样本了,它等于1-Recall 调和平均值F1_score:2PrecisionRecall/(Recall+ Precision) 一般来说,决策边界为theta.T*x_b=0,即计算出p>0.5时分类为1,如果我们手动改变这个threshold,就可以平移这个决策边界,改变精准率和召回率 可以用precisions-recalls曲线与坐标轴围成的面积衡量模型的好坏 ![https://upload-images.jianshu.io/upload_images/5420272-a58ca7b5ef330aa6.png?imageMogr2/auto-orient/strip%7CimageView2/2/w/457] 使用scikit-learn绘制Precision-Recall曲线 对于某个二分类分类器来说,输出结果标签(0还是1)往往取决于输出的概率以及预定的概率阈值,比如常见的阈值就是0.5,大于0.5的认为是正样本,小于0.5的认为是负样本。如果增大这个阈值,预测错误(针对正样本而言,即指预测是正样本但是预测错误,下同)的概率就会降低但是随之而来的就是预测正确的概率也降低;如果减小这个阈值,那么预测正确的概率会升高但是同时预测错误的概率也会升高。实际上,这种阈值的选取也一定程度上反映了分类器的分类能力。我们当然希望无论选取多大的阈值,分类都能尽可能地正确,也就是希望该分类器的分类能力越强越好,一定程度上可以理解成一种鲁棒能力吧。 为了形象地衡量这种分类能力,ROC曲线横空出世!如下图所示,即为一条ROC曲线(该曲线的原始数据第三部分会介绍)。现在关心的是: 横轴:False Positive Rate(假阳率,FPR) 纵轴:True Positive Rate(真阳率,TPR) 假阳率,简单通俗来理解就是预测为正样本但是预测错了的可能性,显然,我们不希望该指标太高。 真阳率,则是代表预测为正样本但是预测对了的可能性,当然,我们希望真阳率越高越好。 显然,ROC曲线的横纵坐标都在[0,1]之间,自然ROC曲线的面积不大于1。现在我们来分析几个特殊情况,从而更好地掌握ROC曲线的性质: (0,0):假阳率和真阳率都为0,即分类器全部预测成负样本 (0,1):假阳率为0,真阳率为1,全部完美预测正确,happy (1,0):假阳率为1,真阳率为0,全部完美预测错误,悲剧 (1,1):假阳率和真阳率都为1,即分类器全部预测成正样本 TPR=FPR,斜对角线,预测为正样本的结果一半是对的,一半是错的,代表随机分类器的预测效果。 于是,我们可以得到基本的结论:ROC曲线在斜对角线以下,则表示该分类器效果差于随机分类器,反之,效果好于随机分类器,当然,我们希望ROC曲线尽量位于斜对角线以上,也就是向左上角(0,1)凸。 ROC曲线一定程度上可以反映分类器的分类效果,但是不够直观,我们希望有这么一个指标,如果这个指标越大越好,越小越差,于是,就有了AUC。AUC实际上就是ROC曲线下的面积。AUC直观地反映了ROC曲线表达的分类能力。 AUC = 1,代表完美分类器 0.5 < AUC < 1,优于随机分类器 0 < AUC < 0.5,差于随机分类器 AUC最大的应用应该就是点击率预估(CTR)的离线评估。CTR的离线评估在公司的技术流程中占有很重要的地位,一般来说,ABTest和转全观察的资源成本比较大,所以,一个合适的离线评价可以节省很多时间、人力、资源成本。那么,为什么AUC可以用来评价CTR呢?我们首先要清楚两个事情: (1)CTR是把分类器输出的概率当做是点击率的预估值,如业界常用的LR模型,利用sigmoid函数将特征输入与概率输出联系起来,这个输出的概率就是点击率的预估值。内容的召回往往是根据CTR的排序而决定的。 (2)AUC量化了ROC曲线表达的分类能力。这种分类能力是与概率、阈值紧密相关的,分类能力越好(AUC越大),那么输出概率越合理,排序的结果越合理。 我们不仅希望分类器给出是否点击的分类信息,更需要分类器给出准确的概率值,作为排序的依据。所以,这里的AUC就直观地反映了CTR的准确性(也就是CTR的排序能力). 步骤如下: (1)得到结果数据,数据结构为:(输出概率,标签真值) (2)对结果数据按输出概率进行分组,得到(输出概率,该输出概率下真实正样本数,该输出概率下真实负样本数)。这样做的好处是方便后面的分组统计、阈值划分统计等 (3)对结果数据按输出概率进行从大到小排序 (4)从大到小,把每一个输出概率作为分类阈值,统计该分类阈值下的TPR和FPR (5)微元法计算ROC曲线面积、绘制ROC曲线 代码如下所示: 数据:提供的数据为每一个样本的(预测概率,真实标签)tuple 数据链接:https://pan.baidu.com/s/1c1FUzVM,密码1ax8 计算结果:AUC=0.747925810016,与Spark MLLib中的roc_AUC计算值基本吻合 当然,选择的概率精度越低,AUC计算的偏差就越大。 Reference: 模型评价(一) AUC大法 Python3入门机器学习 - 混淆矩阵、精准率、召回率
---
正样本
负样本
预测为正
TP(真阳例)
FP(假阳例)
预测为负
FN(假阴例)
TN(真阴例)
1.1 混淆矩阵的评价指标
#准备数据
import numpy as np
from sklearn import datasets
digits = datasets.load_digits()
X = digits['data']
y = digits['target'].copy()
#手动让digits数据集9的数据偏斜
y[digits['target']==9] = 1
y[digits['target']!=9] = 0
from sklearn.linear_model import LogisticRegression
from sklearn.model_selection import train_test_split
X_train,X_test,y_train,y_test = train_test_split(X,y,random_state=666)
log_reg = LogisticRegression()
log_reg.fit(X_train,y_train)
log_reg.score(X_test,y_test)
y_log_predict = log_reg.predict(X_test)
def TN(y_true,y_predict):
return np.sum((y_true==0)&(y_predict==0))
TN(y_test,y_log_predict)
def FP(y_true,y_predict):
return np.sum((y_true==0)&(y_predict==1))
FP(y_test,y_log_predict)
def FN(y_true,y_predict):
return np.sum((y_true==1)&(y_predict==0))
FN(y_test,y_log_predict)
def TP(y_true,y_predict):
return np.sum((y_true==1)&(y_predict==1))
TP(y_test,y_log_predict)
#构建混淆矩阵
def confusion_matrix(y_true,y_predict):
return np.array([
[TN(y_true,y_predict),FP(y_true,y_predict)],
[FN(y_true,y_predict),TP(y_true,y_predict)]
])
confusion_matrix(y_test,y_log_predict)
#精准率
def precision_score(y_true,y_predict):
tp = TP(y_true,y_predict)
fp = FP(y_true,y_predict)
try:
return tp/(tp+fp)
except:
return 0.0
precision_score(y_test,y_log_predict)
#召回率
def recall_score(y_true,y_predict):
tp = TP(y_true,y_predict)
fn = FN(y_true,y_predict)
try:
return tp/(tp+fn)
except:
return 0.0
recall_score(y_test,y_log_predict)
#scikitlearn中的精准率和召回率
#构建混淆矩阵
from sklearn.metrics import confusion_matrix
confusion_matrix(y_test,y_log_predict)
#精准率
from sklearn.metrics import precision_score
precision_score(y_test,y_log_predict)
#f1-score
f1_score(y_test,y_log_predict)
1.2 Precision-Recall的平衡

#该函数可以得到log_reg的预测分数,未带入sigmoid
decsion_scores = log_reg.decision_function(X_test)
#将threshold由默认的0调为5
y_predict2 = decsion_scores>=5.0
precision_score(y_test,y_predict2)
# 0.96
recall_score(y_test,y_predict2)
# 0.5333333333333333
y_predict2 = decsion_scores>=-5.0
precision_score(y_test,y_predict2)
# 0.7272727272727273
recall_score(y_test,y_predict2)
# 0.8888888888888888
1.3 精准率和召回率曲线
from sklearn.metrics import precision_score
from sklearn.metrics import recall_score
thresholds = np.arange(np.min(decsion_scores),np.max(decsion_scores))
precisions = []
recalls = []
for threshold in thresholds:
y_predict = decsion_scores>=threshold
precisions.append(precision_score(y_test,y_predict))
recalls.append(recall_score(y_test,y_predict))
import matplotlib.pyplot as plt
plt.plot(thresholds,precisions)
plt.plot(thresholds,recalls)
plt.show()

plt.plot(precisions,recalls)
plt.show()
from sklearn.metrics import precision_recall_curve
precisions,recalls,thresholds = precision_recall_curve(y_test,decsion_scores)
#由于precisions和recalls中比thresholds多了一个元素,因此要绘制曲线,先去掉这个元素
plt.plot(thresholds,precisions[:-1])
plt.plot(thresholds,recalls[:-1])
plt.show()

2 ROC曲线
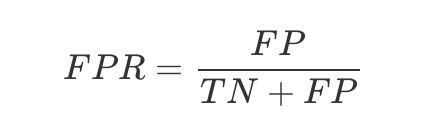
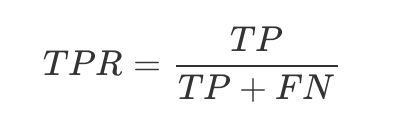
3 AUC(Area under the ROC curve)曲线
3.1 AUC的用处
3.2 AUC求解
import pylab as pl
from math import log,exp,sqrt
import itertools
import operator
def read_file(file_path, accuracy=2):
db = [] #(score,nonclk,clk)
pos, neg = 0, 0 #正负样本数量
#读取数据
with open(file_path,'r') as fs:
for line in fs:
temp = eval(line)
#精度可控
#score = '%.1f' % float(temp[0])
score = float(temp[0])
trueLabel = int(temp[1])
sample = [score, 0, 1] if trueLabel == 1 else [score, 1, 0]
score,nonclk,clk = sample
pos += clk #正样本
neg += nonclk #负样本
db.append(sample)
return db, pos, neg
def get_roc(db, pos, neg):
#按照输出概率,从大到小排序
db = sorted(db, key=lambda x:x[0], reverse=True)
file=open('data.txt','w')
file.write(str(db))
file.close()
#计算ROC坐标点
xy_arr = []
tp, fp = 0., 0.
for i in range(len(db)):
tp += db[i][2]
fp += db[i][1]
xy_arr.append([fp/neg,tp/pos])
return xy_arr
def get_AUC(xy_arr):
#计算曲线下面积
auc = 0.
prev_x = 0
for x,y in xy_arr:
if x != prev_x:
auc += (x - prev_x) * y
prev_x = x
return auc
def draw_ROC(xy_arr):
x = [_v[0] for _v in xy_arr]
y = [_v[1] for _v in xy_arr]
pl.title("ROC curve of %s (AUC = %.4f)" % ('clk',auc))
pl.xlabel("False Positive Rate")
pl.ylabel("True Positive Rate")
pl.plot(x, y)# use pylab to plot x and y
pl.show()# show the plot on the screen