写给Rikka自己的Handler源码说明书
1.Handler概述
Handler是Android的一套消息传递机制。
为什么要使用Handler呢?只有一点原因:在界面可视之后,子线程不能更新UI,所以子线程需要一种手段来通知UI线程数据已更新,这个手段就是Handler。
1.1 Handler的组成
它有四个非常重要的对象来完成这套机制:
Handler
负责消息的发送和处理MessageQueue
消息队列,负责存放消息Message
消息载体Looper
负责消息的轮询
上面的四个东西都是处于同一个线程,在一个线程里面实现了Handler机制。
这里画一个图来看看他们之间的关系:
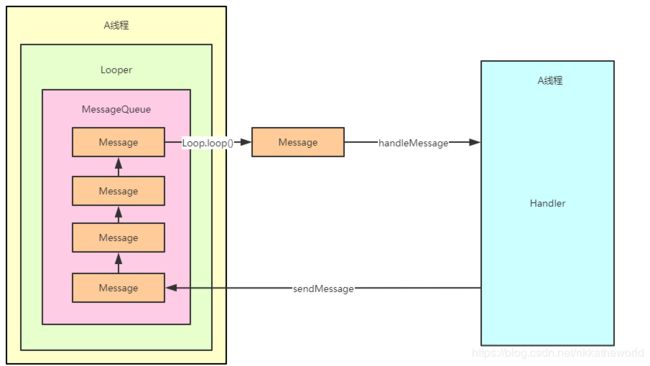
这是一个非常简单理解的版本,下面来解读一下
- 任何一个线程只有一个Looper,任意一个Looper里面只有一个MessageQueue
- MessageQueue维护的是一个 Message链表,里面的Message有明确的指向
- 一个线程可以持有有多个Handler
2. Handler机制源码
2.1 Handler构造函数
先来看下Handler的构造函数:
// Handler.java
private static final boolean FIND_POTENTIAL_LEAKS = false;
final Looper mLooper;
final MessageQueue mQueue;
final Callback mCallback;
final boolean mAsynchronous;
IMessenger mMessenger;
public interface Callback {
public boolean handleMessage(Message msg);
}
public Handler(Callback callback, boolean async) {
if (FIND_POTENTIAL_LEAKS) {
final Class<? extends Handler> klass = getClass();
if ((klass.isAnonymousClass() || klass.isMemberClass() || klass.isLocalClass()) &&
(klass.getModifiers() & Modifier.STATIC) == 0) {
Log.w(TAG, "The following Handler class should be static or leaks might occur: " +
klass.getCanonicalName());
}
}
mLooper = Looper.myLooper();
if (mLooper == null) {
throw new RuntimeException(
"Can't create handler inside thread that has not called Looper.prepare()");
}
mQueue = mLooper.mQueue;
mCallback = callback;
mAsynchronous = async;
}
public Handler(Looper looper, Callback callback, boolean async) {
mLooper = looper;
mQueue = looper.mQueue;
mCallback = callback;
mAsynchronous = async;
}
Handler主要实现上面两种构造方法。分别对 mLooper、mQueue、mCallback、mAsynchronous进行了传参。
- mCallback:
Callback类型,是一个实现了handleMessage()的对象,由构造时外部代入,可以说是回调函数,或者说Handler机制的出口。 - mLooper:
Looper类型,每个Handler都会持有绑定一个Looper - mQueue :
MessageQueue类型,作为Handler中消息队列的存在,它是Looper的消息变量,所以会从 mLooper中取出。 - mAsynchronous :是否异步
上面两个构造函数的区别是,前者没有在传参时带入Looper,所以当前的 Looper为 Looper.myLooper()。为了搞懂这个方法、对象是什么意义?我们需要先知道Looper。
2.2 Looper从哪里冒出来的
首先每个线程只有一个Looper,在Handler机制的场景下,我们要得到就是 主线程(即UI线程)的那个Looper。
那么主线程的Looper是怎么来的,在 应用程序进程的启动的学习中(如果没学过请参考 《Android进阶解密-应用程序进程启动过程》),在应用程序进程被创建时,会创建UI线程ActivityThread,并调用它的 main():
// ActivityThread.java
public static void main(String[] args) {
...
Looper.prepareMainLooper(); // 1
ActivityThread thread = new ActivityThread();
thread.attach(false);
...
Looper.loop(); // 1
...
}
注释1:创建一个 主线程Looper。
注释2:开启这个Looper。
先暂且不看第二个方法,去看看第一个方法里面做了什么:
// Looper.java
public static void prepareMainLooper() {
prepare(false); // 1
synchronized (Looper.class) {
if (sMainLooper != null) {
throw new IllegalStateException("The main Looper has already been prepared.");
}
sMainLooper = myLooper(); // 2
}
}
注释1:调用了 prepare(flase)
注释2:同样的,也调用了 myLooper(),并把返回结果赋值给了 sMainLooper,听名字就知道它是 主线程的Looper。
来看看prepare方法做什么:
// Looper.java
static final ThreadLocal<Looper> sThreadLocal = new ThreadLocal<Looper>();
private static void prepare(boolean quitAllowed) {
if (sThreadLocal.get() != null) {
throw new RuntimeException("Only one Looper may be created per thread");
}
sThreadLocal.set(new Looper(quitAllowed));
}
private Looper(boolean quitAllowed) {
mQueue = new MessageQueue(quitAllowed);
mThread = Thread.currentThread();
}
到这个方法里,我们看到了 UI线程的Looper,就是在这个地方(prepare())创建的。
它通过构造函数,持有了当前UI线程的引用mThread,并且构建了一个新的 MessageQueuemQueue,且为非异步。
并把这个 UI线程Looper 通过 ThreadLocal.set()设置到了 sThreadLocal中:
// ThreadLocal.java
public void set(T value) {
Thread t = Thread.currentThread();
ThreadLocalMap map = getMap(t);
if (map != null)
map.set(this, value);
else
createMap(t, value);
}
这里出现了一个叫做 ThreadLocalMap的东西,而set方法就是把 (threadLocal, UiLooper)作为键值对存进去的,也就是说 ThreadLocalMap是一个存放 ThreadLocal - Looper的集合,我们可以看看 ThreadLocalMap这个类,它是ThreadLocal的内部类:
// ThreadLocal.java
static class ThreadLocalMap {
static class Entry extends WeakReference<ThreadLocal<?>> {
Object value;
// 1
Entry(ThreadLocal<?> k, Object v) {
super(k);
value = v;
}
}
// 2
private Entry[] table;
private void set(ThreadLocal<?> key, Object value) {
Entry[] tab = table;
int len = tab.length;
// 3
int i = key.threadLocalHashCode & (len-1);
// 4
for (Entry e = tab[i];
e != null;
e = tab[i = nextIndex(i, len)]) {
ThreadLocal<?> k = e.get();
if (k == key) { // 5
e.value = value;
return;
}
if (k == null) {
replaceStaleEntry(key, value, i);
return;
}
}
tab[i] = new Entry(key, value); // 6
int sz = ++size;
if (!cleanSomeSlots(i, sz) && sz >= threshold)
rehash();
}
来解析一个 ThreadLocalMap:
注释1:一个 Entry包含一个弱引用的 ThreadLocal作为key,一个Object作为value,这个Object我们前面带进来的就是Looper。
注释2:表明 ThreadLocalMap的数据结构是一个 Entry数组
注释3:ThreadLocalMap的set方法借鉴了HashMap得做法,元素的存储位置是 key的hash值mod哈希桶的长度
注释4、注释6:通过注释3,拿到存储位置 i,如果i位置存在有效元素,也就是说发生了哈希冲突,这个时候 i取 nextIndex(i, len),即i 的下一个下标,然后拿新的i去判断这个位置有没有元素,直到找到为空的元素,然后放入这个Looper。
注释5:如果i下标存在元素,但是 它的key和拿来存放数据的 key是一样的,则覆盖value。
到这里我们就知道ThreadLocalMap是做什么的了:
ThreadLocalMap总结:
TheradLocalMap存放 ThreadLocal - Looper的键值对,其中ThreadLocal是弱引用,它采用hash的方式存取,效率比较高,如果出现了hash冲突,则采用线性探测的方法解决。它维护了当前ThreadLocal所持有的Looper。
回到 ThreadLocal.set()中,UI线程的Looper和Looper的成员变量 sThreadLocal被作为 k-v已经被存放到这个 ThreadLocalMap中了。然后又回到 prepareMainLooper()的注释2中: sMainLooper = myLooper(),这里的重点是 myLooper()方法,我们来看看这个方法做了什么:
// Looper.java
public static @Nullable Looper myLooper() {
return sThreadLocal.get();
}
myLooper() 是返回 ThreadLocal.get():
// ThreadLocal.java
public T get() {
Thread t = Thread.currentThread(); // 1
ThreadLocalMap map = getMap(t); // 2
if (map != null) {
ThreadLocalMap.Entry e = map.getEntry(this); // 3
if (e != null) {
@SuppressWarnings("unchecked")
T result = (T)e.value;
return result;
}
}
return setInitialValue();
}
注释1、2:获取到当前线程的 ThreadLocalMap。
注释3:得到 ThreadLocalMap中当前 ThreadLocal所绑定的Looper。
所以 ThreadLocal.get()获取的是当前线程的Looper
而在当前场景中,我们拿到的是主线程的Looper。
这里也就得出了Handler构造函数中Looper从哪里来的结论:
每个线程只有一个Looper,如果不在Handler构造函数中带入Looper,那么Looper就是:Handler所在线程的Looper。
我们知道Looper是怎么出生的,但是我们还不知道它是做什么的,在这节的开头,我们通过 prepareMainLooper()创建了UI线程的Looper后,我们又通过 Looper.loop()开启了Looper的轮询,这个方法非常重要,我们需要深入它。
2.3 Loop.loop()
来看下 loop()代码:
// Looper.java
public static void loop() {
final Looper me = myLooper(); // 1
...
final MessageQueue queue = me.mQueue; // 2
...
for (;;) { // 3
Message msg = queue.next(); // 4
if (msg == null) { // 5
// No message indicates that the message queue is quitting.
return;
}
...
final long slowDispatchThresholdMs = me.mSlowDispatchThresholdMs;
...
try {
msg.target.dispatchMessage(msg); // 6
} finally {
...
}
...
msg.recycleUnchecked();
}
}
上面滤去了不重要的代码。
注释1:拿到当前线程的Looper(即ui线程的Looper)
注释2:从Looper中拿出 MessageQueue
注释3:开启死循环
注释4:从 MessageQueue.next()中获取一个 Message出来
注释5:如果取出的Message为null,则跳出死循环
注释6:根据 Message的target来通过 dispatchMessage(msg)来发送这个消息。
也就是说 Looper.loop()开启了一个死循环,来处理其 MessageQueue里面的每一个Message。
直到 Message为null了才跳出循环,而英文注释表示 当只有在 MessageQueue退出的时候 Message才为空,而MessageQueue的生命和线程一样,也就是说:线程终止了,这个循环才会结束。
所以也从而验证了,这个类为什么叫Looper(循环者,不是某冠军上单)。
这里有两个问题,也是面试的时候面试官喜欢问的:
(1)为什么开了死循环,App却感受不了卡顿,也没有ANR?
逆推回去,既然App没有卡顿,也就是说 MessageQueue有源源不断的message供主线程处理,这是因为像 AMS、WMS这些SystemServer进程在程序运行时会一直提供功能的支持,通过Binder机制,向主进程的主线程中发送消息,所以 Looper的死循环一直是工作状态,所以并不会导致卡顿。
(2)那这样一直开着死循环,不会很占CPU资源吗?
这里就要继续看代码了,我们看看上述循环中 MessageQueue.next()做了什么.
2.4 MessageQueue.next()
因为 next()代码有点长,所以把其中死循环的部分分成三个部分进行讲解:
Part1 无消息处理时挂起
// MessageQueue.java
private native void nativePollOnce(long ptr, int timeoutMillis);
Message next() {
...
int pendingIdleHandlerCount = -1;
int nextPollTimeoutMillis = 0;
for (;;) { // 1
if (nextPollTimeoutMillis != 0) {
Binder.flushPendingCommands();
}
nativePollOnce(ptr, nextPollTimeoutMillis); // 2
....
}
}
注释1中:可以看到的, next()也开了个死循环,WTF?什么鬼,loop()已经是死循环,这里还来套一个死循环了???
注释2:调用 nativePollOnce(ptr, nextPollTimeoutMillis),这个方法非常滴重要,它是一个 native方法,我这里就不再深入到 JNI层去看C的代码了,我这边用大白话来解释这个代码的作用:
在主线程打开Looper循环前,会打开Android系统底层的一个I/O管道(Linux epoll),如果你身边有个后台人员,你可以问他关于 epoll的知识,epoll做的事情就是监视文件描述符的I/O事件,它是 事件驱动模型,换言之,它就是一个NIO。在没有事件时主线程挂起,有事件时主线程唤醒处理。
关于C++层的源码可以参考下这一篇:Android 中 MessageQueue 的 nativePollOnce。
函数中传入了 nextPollTimeoutMillis,有点像 Thread.sleep(mills)。这个nextPollTimeoutMillis会在延时任务中起到作用。
这里也就回答了上节末尾的问题,为什么开死循环不会特别占用CPU的资源,是因为在没有消息的时候主线程已经挂起,有消息时才会唤醒。
Part2 返回一个消息
// MessageQueue.java
...
synchronized (this) {
final long now = SystemClock.uptimeMillis();
Message prevMsg = null;
Message msg = mMessages; // 1
...
if (msg != null) {
if (now < msg.when) { // 2
nextPollTimeoutMillis = (int) Math.min(msg.when - now, Integer.MAX_VALUE);
} else {
mBlocked = false;
if (prevMsg != null) {
prevMsg.next = msg.next;
} else {
mMessages = msg.next; // 3
}
msg.next = null;
msg.markInUse();
return msg;
}
} else {
nextPollTimeoutMillis = -1;
}
....
这段代码比较好理解,不过我们要先知道 MessageQueue里面维护的是一个 Message链表
注释1:拿到当前的MessagemMessage。
注释2:判断 msg是否是延时任务,如果是的话则不处理,并更新 nextPollTimeoutMillis 的时间
注释3:如果 msg不是延时任务,则把 mMessage指向当前 msg在链表中的下一个。然后return当前的msg。
Part3 IdleHandler
...
synchronized (this) {
....
if (pendingIdleHandlerCount < 0
&& (mMessages == null || now < mMessages.when)) {
pendingIdleHandlerCount = mIdleHandlers.size(); // 1
}
if (pendingIdleHandlerCount <= 0) { // 2
mBlocked = true;
continue;
}
if (mPendingIdleHandlers == null) {
mPendingIdleHandlers = new IdleHandler[Math.max(pendingIdleHandlerCount, 4)]; // 3
}
mPendingIdleHandlers = mIdleHandlers.toArray(mPendingIdleHandlers);
}
// 4
for (int i = 0; i < pendingIdleHandlerCount; i++) {
final IdleHandler idler = mPendingIdleHandlers[i];
mPendingIdleHandlers[i] = null;
boolean keep = false;
try {
keep = idler.queueIdle(); // 5
} catch (Throwable t) {
Log.wtf(TAG, "IdleHandler threw exception", t);
}
if (!keep) {
synchronized (this) {
mIdleHandlers.remove(idler);
}
}
}
pendingIdleHandlerCount = 0; // 6
nextPollTimeoutMillis = 0; // 7
}
}
这段代码涉及到了 IdleHandler,它是MessagQueue的内部类,我们先来看看他是做啥的:
// MessagQueue.java
private final ArrayList<IdleHandler> mIdleHandlers = new ArrayList<IdleHandler>();
public static interface IdleHandler {
boolean queueIdle();
}
public void addIdleHandler(@NonNull IdleHandler handler) {
if (handler == null) {
throw new NullPointerException("Can't add a null IdleHandler");
}
synchronized (this) {
mIdleHandlers.add(handler);
}
}
可以发现它是一个接口,通过 addIdleHandler()可以添加实现了 queueIdle()方法的对象进来,保存在 mIdleHandlers的List中。
我们回到part3的代码中来解析一下:
注释1:如果pendingIdleHandlerCount < 0 并且当前没有Message或者是延时任务,则把 mIdleHandlers的大小赋值给pendingIdleHandlerCount 。
注释2:如果赋值过后的pendingIdleHandlerCount <= 0,则说明当前线程没有可以执行的任务,那么continue,在下一个循环中将当前线程挂起。
注释3:如果mPendingIdleHandlers为null,则new一个IdleHandler出来赋值给它,并将其转换成一个 数组。
注释4:遍历 mPendingIdleHandlers
注释5:取出其中的每个 IdleHandler并执行它的 queueIdle()方法。
注释6、注释7:清空 pendingIdleHandlerCount 和 nextPollTimeoutMillis 。因为如果是延时任务,早就已经continue了。另外一个事情就是,如果第一次打开死循环,Message链表是空的,这时候主线程可以做些别的事情(就是 IdleHandler),做完之后,之后的循环就不会再去做这样的操作了(除非我们自己加IdleHandler进来)。
到这里 MessageQueue.next()就解析完了,这里做一个总结,它大概做了三件事情:
- 开启死循环
- 如果当前没有Message可以处理,则调用
nativePollOnce()挂起主线程,不占用CPU资源。 等到有消息可以处理时唤醒主线程。 - 如果存在非延时的消息,则把该消息返回到Looper中。
- 如果是循环的第一次,可能会没有消息,这个时候可以 处理
IdleHandler的消息,做一些别的事情,这相当于提升了性能,不让主线程一上来就因为没有Message而挂起,然后下个循环又马上被唤醒。
2.5 Message是如何被加入到MessageQueue中的?
在上一节中,我把MessaqeQueue和Messaqe的关系笼统的概括为: MessageQueue中维护了一个Message链表。
仅仅这样理解是不够的,我们需要搞清楚,一个Message是怎么放到 MessageQueue中的。入口方法就是我们常用的 Handler.sendMessage()或者 Handler.sendMessageDelayed()还是 Handler.postDelay(),他们最终都会调用 sendMessageAtTime():
// Handler.java
public boolean sendMessageAtTime(Message msg, long uptimeMillis) {
MessageQueue queue = mQueue;
if (queue == null) {
RuntimeException e = new RuntimeException(
this + " sendMessageAtTime() called with no mQueue");
Log.w("Looper", e.getMessage(), e);
return false;
}
return enqueueMessage(queue, msg, uptimeMillis);
}
这个方法会调用 enqueueMessage(),然后传入当前 Handler的 MessageQueue() mQueue,我们在开篇讲过,mQueue是构造函数中就被创建,它是传入的 Looper的MessageQueue。
// Handler.java
private boolean enqueueMessage(MessageQueue queue, Message msg, long uptimeMillis) {
msg.target = this; // 1
if (mAsynchronous) {
msg.setAsynchronous(true);
}
return queue.enqueueMessage(msg, uptimeMillis); // 2
}
注释1:把msg.target = this,就是说这个消息发送给当前Handler的。
注释2:调用 MessageQueue.enqueueMessage(),传入消息体和延时时间。这个动作就是把消息加入到 MQ中了。
来看一下加入过程:
// MessageQueue.java
boolean enqueueMessage(Message msg, long when) {
...
synchronized (this) {
...
msg.markInUse();
msg.when = when;
Message p = mMessages; :
boolean needWake;
if (p == null || when == 0 || when < p.when) { //1
msg.next = p;
mMessages = msg;
needWake = mBlocked;
} else {
needWake = mBlocked && p.target == null && msg.isAsynchronous();
Message prev;
for (;;) { // 2
prev = p;
p = p.next;
if (p == null || when < p.when) {
break;
}
if (needWake && p.isAsynchronous()) {
needWake = false;
}
}
msg.next = p;
prev.next = msg;
}
if (needWake) {
nativeWake(mPtr);
}
}
return true;
}
注释1:如果当前的Message是非延时任务,或者说比列表最后一个Message的执行时间要快,那么它就插队,插到前面去。
注释2:否则的话,就往列表后边找,找到 末尾或者第一个Message执行时间比当前的要晚的,然后插进去。
这段代码很简单,要么当前任务 插到前面,要么插到后面最早执行的位置。
到这里,一个Message的入队就讲完了。
2.6 关于消息分发 msg.target.dispatchMessage(msg)
回到Looper中,在死循环里,它会调用 msg.target.dispatchMessage(msg), 我们知道,msg.target是发送消息的Handler,那么这里调用了 目标Handler的dispatchMessage()把Message发送出去,来看看这个方法:
// Handler.java
public void dispatchMessage(Message msg) {
if (msg.callback != null) {
handleCallback(msg); // 1
} else {
if (mCallback != null) { // 2
if (mCallback.handleMessage(msg)) { // 3
return;
}
}
handleMessage(msg); // 4
}
}
private static void handleCallback(Message message) {
message.callback.run();
}
注释1:如果msg.callback不为空,则直接调用这个Callback的 run(),这个情况是我们在Message中传入了一个Callback的方法,它在处理时,会直接调用这个Callback方法。
注释2、注释3:如果在创建 Handler(构造函数中)时带入了 一个 Callback,则直接调用这个 Callback,这个构造函数我们在开篇看过。
注释4:如果都不是上述情况,则调用 handleMessage()。
// Handler.java
/**
* Subclasses must implement this to receive messages.
*/
public void handleMessage(Message msg) {
}
handleMessage() 是一个空方法,英文文档的解释为: 子类必须实现这个方法
这就是为什么我们在自己使用的时候,一定要重写 handleMessage(),然后对发送过来的消息做处理。
当这个消息被调用时,也说明了 Message被分发成功了。
到这里,handler的源码也讲解的差不多了。
3. 在子线程中更新UI
这里画一个图便于理解:

这里手写一个简单例子,在子线程通过Handler去更新UI线程:
public class MainActivity extends AppCompatActivity {
private TextView textView;
private static final int COUNT = 0x00001;
private Handler handler = new Handler() { // 1
@Override
public void handleMessage(Message msg) {
if (msg.what == COUNT) {
textView.setText(String.valueOf(msg.obj));
}
super.handleMessage(msg);
}
};
@Override
protected void onCreate(Bundle savedInstanceState) {
super.onCreate(savedInstanceState);
setContentView(R.layout.activity_main);
textView = findViewById(R.id.btn);
new Thread() { // 2
@Override
public void run() {
try {
for (int i = 0; i < 100; i++) {
Thread.sleep(500);
Message msg = new Message();
msg.what = COUNT;
msg.obj = "计数:" + i;
handler.sendMessage(msg); // 3
}
} catch (Exception e) {
e.printStackTrace();
}
}
}.start();
}
}
注释1中:我们在主线程创建了一个Handler,那么其Looper自然就是UI线程的Looper
注释2:开启一个子线程
注释3:在子线程中,持有一个主线程的Handler,然后给这个Handler发送消息。
上面代码非常容易理解,但是可能会出现内存泄漏,所以这里只是做一个子线程更新UI的认知。
4. 主线程更新子线程、子线程更新其他子线程
开篇我说过,Handler的出现是子线程不能更新UI,所以Handler起到了这个作用。
这一章是来自于我实习面试的时候,面试官在Handler这点上问我:那主线程怎么更新子线程?或者子线程怎么更新其他的子线程?
我当时由于没有细读Handler的源码,所以我粗略的回答:只要持有对方线程的Handler,就可以更新了。
其实我回答也没错,但是这谈不上及格的答案,面试官也不会喜欢,下面我将用代码来演示一遍:
4.1 主线程更新子线程
public class MainActivity extends AppCompatActivity {
private static final String TAG = "MainActivity";
private MyThread thread;
class MyThread extends Thread {
private Looper looper;
@Override
public void run() {
Looper.prepare(); // 1
Log.d(TAG, "子线程为->" + Thread.currentThread() + "");
looper = Looper.myLooper(); // 2
Looper.loop(); // 3
}
}
private Handler mHandler;
@Override
protected void onCreate(Bundle savedInstanceState) {
super.onCreate(savedInstanceState);
setContentView(R.layout.activity_main);
Log.d(TAG, "主线程为->" + Thread.currentThread() + "");
thread = new MyThread();
thread.start();
try {
sleep(2000); // 4
} catch (InterruptedException e) {
e.printStackTrace();
}
mHandler = new Handler(thread.looper) { // 5
@Override
public void handleMessage(Message msg) {
Log.d(TAG, "当前线程为->" + Thread.currentThread() + "");
}
};
mHandler.sendEmptyMessage(0);
}
}
主线程要更新子线程,所以主线程要持有子线程的Handler,所以需要用子线程来构造一个Handlder
注释1:为子线程创建一个Looper
注释2:获取子线程Looper
注释3:打开子线程Looper的轮询
注释4:主线程睡一下,避免 子线程还没有完全起来的时候就在主线程获取子线程的Looper了
注释5:通过子线程的Looper创建属于子线程的Handler,然后在主线程中使用Handler发送消息。
打印如下:

说明消息已经从主线程传递到子线程当中去了。
4.2 子线程更新其他子线程
方法同上。下面写两个线程 MyThread1和 MyThread2,然后让2线程给1线程发消息:
public class MainActivity extends AppCompatActivity {
private static final String TAG = "MainActivity";
private MyThread1 thread1;
private MyThread2 thread2;
private Handler thread1Handler;
class MyThread1 extends Thread {
@Override
public void run() {
Log.d(TAG, "子线程1为->" + Thread.currentThread() + "");
Looper.prepare();
thread1Handler = new Handler() {
@Override
public void handleMessage(Message msg) {
super.handleMessage(msg);
Log.d(TAG, "这个消息是从->" + msg.obj + "线程发过来的,在" + Thread.currentThread() + "线程中获取的");
}
};
Looper.loop();
}
}
class MyThread2 extends Thread {
@Override
public void run() {
Log.d(TAG, "子线程2为->" + Thread.currentThread() + "");
Message msg = thread1Handler.obtainMessage();
msg.obj = Thread.currentThread();
thread1Handler.sendMessage(msg);
}
}
@Override
protected void onCreate(Bundle savedInstanceState) {
super.onCreate(savedInstanceState);
setContentView(R.layout.activity_main);
thread1 = new MyThread1();
thread2 = new MyThread2();
thread1.start();
try {
Thread.sleep(500); // 让Thread1完全起来
} catch (InterruptedException e) {
e.printStackTrace();
}
thread2.start();
}
打印结果如下:

所以一开始的问题:如果在主线程中更新子线程,在子线程中更新另外的子线程的解答:
(1)要持有目标线程的Handler
(2)因为非UI线程是不会自己开启轮询的,所以要手动在子线程中启动 Looper.prepare()和 Looper.loop()
another question: HandlerThread
在上面的手动写法中,我们还要写 Thread.sleep保证子线程启动起来,并且我们还要手动在子线程中手写 Looper.prepare()、Looper.loop(),这无疑有一些麻烦,Android提供了一个便于在子线程开启Handler、Looper的类,就是 HandlerThread
5. HandlerThread
HandlerThread顾名思义,就是使用 Handler的线程。它的源码非常简单,来看看:
先来看看其构造函数:
// HandlerThread.java
public class HandlerThread extends Thread {
int mPriority;
int mTid = -1;
Looper mLooper;
private @Nullable Handler mHandler;
public HandlerThread(String name) {
super(name);
mPriority = Process.THREAD_PRIORITY_DEFAULT;
}
public HandlerThread(String name, int priority) {
super(name);
mPriority = priority;
}
}
HandlerThread是继承Thread的,在构造函数中,传入线程名称和优先级。
接下来看看其 run方法:
// HandlerThread.java
protected void onLooperPrepared() {
}
@Override
public void run() {
mTid = Process.myTid();
Looper.prepare();
synchronized (this) {
mLooper = Looper.myLooper();
notifyAll();
}
Process.setThreadPriority(mPriority);
onLooperPrepared();
Looper.loop();
mTid = -1;
}
run方法中,写了 Looper.prepare(),然后锁住对象去获取Looper,通过 Process.setThreadPriority()来设置线程优先级。
然后调用 onLooperPrepared(),这是个空方法,表示我们在自己使用HandlerThread时,可以通过重写这个方法来在Looper准备完成后做一些想做的事情。
如何使用HandlerThread来发送消息呢?HandlerThread实现了下面的方法:
@NonNull
public Handler getThreadHandler() {
if (mHandler == null) {
mHandler = new Handler(getLooper());
}
return mHandler;
}
public Looper getLooper() {
if (!isAlive()) {
return null;
}
synchronized (this) {
while (isAlive() && mLooper == null) {
try {
wait();
} catch (InterruptedException e) {
}
}
}
return mLooper;
}
通过 getThreadHandler()我们可以得到当前线程的Handler,并且它会在 getLooper()中保证Looper是起来的。
所以这也避免了我们手写 wait()、sleep()的麻烦。
这里总结一下HandlerThread:
HandlerThread是实现了Thread的线程,它start后会进行 Looper.prepare()、Looper.loop(),并且在我们想要使用其Handler时,能保证Handler不为空。它适合的场景是:主线程需要更新子线程的数据、子线程更新另一个子线程的数据。被更新的子线程可以使用HandlerThread。
6. 关于Message的获取
写这一章节也是基于面试时比较喜欢问的,Message的获取有两种方法:
- 通过 new 方法获取
- 通过 Message.obtain()
上述第二种方法就是 Handler中的 obtainMessage()里调用的方法,两种方法是有区别的,哪一种更好?
我们来看看 Message.obtain():
// Message.java
private static Message sPool;
private static int sPoolSize = 0;
public static Message obtain() {
synchronized (sPoolSync) {
if (sPool != null) {
Message m = sPool;
sPool = m.next;
m.next = null;
m.flags = 0; // clear in-use flag
sPoolSize--;
return m;
}
}
return new Message();
}
可以看到 obtain()中会去 sPool中获取一个Message,如果sPool为空,则返回一个new的Message,否则把sPool赋值给m,并将m返回,然后 sPool取其next。
在结合一下下面的方法:
// Message.java
void recycleUnchecked() {
flags = FLAG_IN_USE;
what = 0;
arg1 = 0;
arg2 = 0;
obj = null;
replyTo = null;
sendingUid = -1;
when = 0;
target = null;
callback = null;
data = null;
synchronized (sPoolSync) {
if (sPoolSize < MAX_POOL_SIZE) {
next = sPool;
sPool = this;
sPoolSize++;
}
}
}
这个方法是在一个消息被使用后,对其进行回收:将所有数据置空,然后将其做为sPool,原来的sPool放到新的后面。
在 Looper.loop()的死循环中,每个循环的最后都会用这个方法。
所以可以轻易的得出结论: 使用 obtainMessage()要比new一个Message好,但是它要和 recycleUnchecked()一起使用。
因为 obtainMessage()维护了一个Message池(Message链表),如果池里没有就会创建一个Message,如果有就将其取出来。在用完之后,调用recycleUnchecked()将使用后的消息数据置空,然后将这个Message放回池里,下次还可以用它,达到了重复利用的效果,节省了空间。但是如果recycleUnchecked(),就不会有Message置空,池子永远都是空的,所以不配合这个方法一起使用,其实就和new出来的一样了。
7. 消息屏障
在读Looper的源码时,有一个词一直出现,就是 barrier,意思是屏障。
Handler中除了可以 sendMessage/postDelay消息体之外,还有一个方法: MessageQueue的 postSyncBarrier():
// MessageQueue.java
private int postSyncBarrier(long when) {
synchronized (this) {
final int token = mNextBarrierToken++;
final Message msg = Message.obtain();
msg.markInUse();
msg.when = when;
msg.arg1 = token;
... // 插入到队列的方法同 enqueueMesage()
}
}
它的方法和 enqueueMesage()差不多,但是我们发现它的传参,没有Message,它构造的Message,只有when,它没有传入tartget,也就是说 消息屏障是发送一个target为null的消息,在 MessageQueue的next()的死循环中中,一上来就是这么一个处理:
// MessageQueue
...
synchronized (this) {
final long now = SystemClock.uptimeMillis();
Message prevMsg = null;
Message msg = mMessages;
if (msg != null && msg.target == null) { // 1
do {
prevMsg = msg;
msg = msg.next;
} while (msg != null && !msg.isAsynchronous()); // 2
}
...
注释1:判断当前的消息是否是屏障消息
注释2:通过 do-while语句拿到MQ中第一个异步的消息并取出来
Handler中,两种消息,第一种是普通消息,第二种是异步消息。
而上面讲到的屏障消息则是为了让异步消息的优先级提高。
讲到这里,Handler关键的源码都已守得云开见月明了,足够应付自己开发+面试了~
之后Handler还有别的内容就另开一篇把,这里的货够干了。