docker+scrapy+scrapy_splash爬取大麦网
文章目录
- 背景
- 开始
- 起初
- 思考
- 动手
- 下载并配置docker
- 拉取镜像并启动
- 爬取网页
- 爬取结果
- 总结
背景
今天拿到个代码需要改改,他是用scrapy爬取大麦网,然后我改了将近一个小时还是得不到内容,第一是太久没用scrapy写爬虫,其次也是因为当时思路太死板,忘了一些重要的细节问题,所以导致一直改不好代码。然后点了个外卖,继续想这个问题。
开始
起初
一开始我还是自己重新搭了一个scrapy的基本框架出来,还是那两句代码
scrapy startproject 项目名生成一个项目
scrapy genspider 爬虫名 网址生成爬虫,需要自己编写解析函数
然后开始写解析函数以及配置setting中相关的设置
但是运行会发现没有结果返回,查看运行日志发现成功请求到网页,但是得不到相关的信息。用print打印css选择的内容发现返回的内容是[],也就是没有得到内容。
思考
第一反应是不应该啊,明明网页都是正常请求到的,怎么会得不到信息呢?
想了一会,然后仔细看了一下请求得到的网页内容,发现关于门票那些内容并没有,恍然大悟。这不就是动态网页吗?然后去看了一下,果然就发现了js渲染的内容


一般这种情况我都是直接requests访问这个网页,然后解析出数据就好,但是今天我和scrapy杠上了,难道scrapy就不能爬取动态网页了吗?然后我尝试了用selenium去请求网页,这样就可以得到网页内容,但是返回的信息和scrapy框架本身的css、xpath选择器兼容性太差,那还不如直接请求用beautifulsoup或者lxml解析。然后去百度了一番,发现了scrapy_splash这个库,于是开始动手尝试。
动手
安装scrapy_splash并不难,pip install scrapy_splash就行,但是需要下载docker,因为scrapy_splash必须在docker中使用。
下载并配置docker
去官网下载docker,然后安装。这没什么难度,安装好之后需要重启一次电脑。然后就是配置镜像源,不然的话拉取镜像会失败的。去阿里云弄一个镜像加速器,然后配置到docker的setting中
关于配置镜像加速器的博客

然后apply,重启docker
拉取镜像并启动
拉取镜像
docker pull scrapinghub/splash
启动
docker run -p 8050:8050 scrapinghub/splash
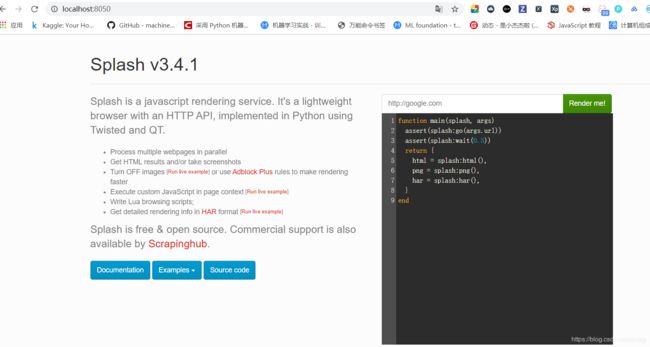
输入地址去render一下,如果得到了完整的页面就说明渲染成功,那我们就可以使用scrapy爬取了

已经得到了我们想要的内容,所以直接爬取就好
爬取网页
spider.py
import scrapy
from damai.items import DamaiItem
from scrapy_splash import SplashRequest
class SpiderSpider(scrapy.Spider):
name = 'spider'
start_urls = ['https://www.damai.cn/']
def start_requests(self):
splah_args = {
"lua_source": """
function main(splash, args)
assert(splash:go(args.url))
assert(splash:wait(3))
return {
html = splash:html(),
png = splash:png(),
har = splash:har(),
}
end
"""
}
start_url = 'https://www.damai.cn/'
headers = {
'User-Agent': 'Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/52.0.2743.82 Safari/537.36'
}
yield SplashRequest(url=start_url, callback=self.parse, args={'wait': 1.0},headers=headers)
def parse(self, response):
#print(response.text)
item = DamaiItem()
info=response.css('.iteminfo')
#print(info)
for i in info:
item['title']=i.css('.title::text').extract_first()
item['address']=i.css('.venue::text').extract_first()
item['showtime']=i.css('.showtime::text').extract_first()
item['price']=i.css('.price::text').extract_first()
yield item
另外的配置我就贴图啦,代码量很少

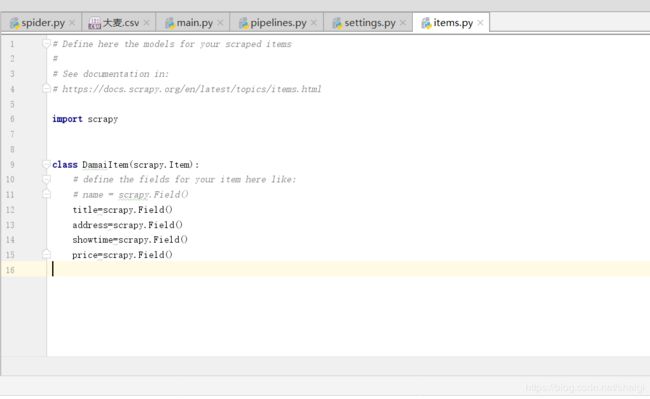
至于setting就自己去配置啦,这个也简单
爬取结果

总算是都爬下来了,睡觉去了。
总结
太久不敲代码真的会生疏,明明一个动态网页的问题居然第一时间没反应过来,花了几个小时做这个简单的不为了别的,起码对于不懂得或者遗忘的东西应该立马回顾一下,老说温故而知新,这不以后动态网页用scrapy爬取的套路我也会了嘛。也希望那个同学也能看到这个博客吧,昨天没帮到忙挺不好意思的。