深度学习笔记:交叉熵(cross-entropy)损失函数解决二次型带来的学习速率下降问题
我们都希望我们的神经网络能够根据误差来加快学习的速度。但实际是什么样的呢?让我们先来看一个例子:
这个网络只有一个神经元,一个输入一个输出:
我们训练这个网络做一个简单的任务,输入1,输出0.当然这种简单的任务我们可以不用任何学习算法就可以
手动算出权重值。但我们这次试用梯度下降法尝试获得权重值和偏置值,损失函数使用二次型函数。接下来
让我们看看这个神经元是怎么学习的。
首先,我选择输入x = 1, w=0.6, b = 0.9, 激活函数为sigmoid(x), 学习速率=0.15 ,因此可以计算出神经元输出
为: sigmoid(1.5) = 0.82, 而我们希望的输出值时0.0。让我们看看随着迭代次数的增加,误差值的变化曲线如下图:
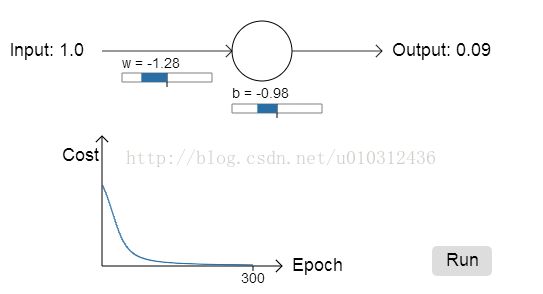
从上图可以看出,神经元很快的学习改变w和b的值来降低误差Cost的值。最终的输出0.09也很接近期待输出0.0。
接下来我们尝试改变初始的w,b的值都为0.2。其他条件不变,因此算出前向输出为: 0,.98 和期待值0相差很大。
在这种情况下误差变化曲线又会是怎么样的呢?

从上图可以看出网络的学习速度明显慢了非常多。在前150回迭代中权重值和偏置值都没怎么发生变化。后面变化非常快,
使误差接近0.这种行为和人类的学习过程规律相比是很奇怪的。我们可以看到当初始输入值使得输出和期待输出的结果
相差比较大时,学习的速度就慢了下来,学习的过程也变的比较困难。
为了了解其中的原因,我们认为这个神经系统的的学习速度由损失函数分别对权重和偏置项的偏导数决定的,
也就是说学习速度比较慢是因为这两个值比较小。
我们目的是要搞清楚为什么这两个偏导数的值比较小,由于使用的是二次型函数:
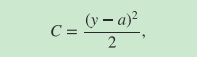
其中,a是神经元的实际输出,y是期待输出。 利用链式求导法则计算误差C对权重和偏置项的偏导数(也就是梯度)如下:

利用链式求导法则,证明过程如下:
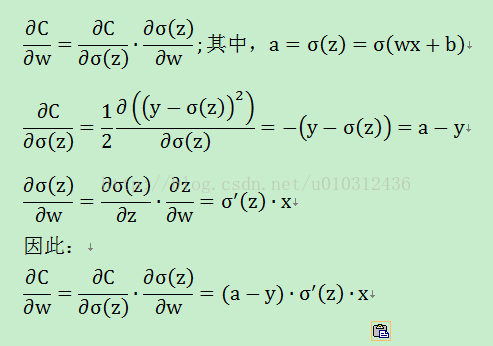
其中,z = wx + b, 我们假设 x = 1, y = 0. 为了理解该表达式的行为,从求出的梯度公式可以看出,梯度的大小和激活函数对
z的偏导数成正比,让我们看看等式右边的激活函数对z的偏导数项。激活函数的图像如下:
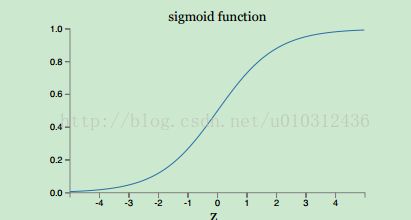
从激活函数的图形变换规律可以看到,当神经元的前向输出(激活函数的输入)接近1时,曲线变的非常平滑,所以激
活函数的偏导数非常小,导致梯度也变小,这就是学习速度变慢的原因。
接下来我们来看看交叉熵(cross-entropy)损失函数是如何定义的,它比二次型有哪些优势呢?
定义:
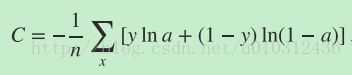
其中,n是训练的样本数量,y是期待的输出,a是实机输出。
从这个公式好像不能看出为什么这个损失函数可以提高神经网络的学习速度,在接下来的推导前我们来说说为什么这
个公式可以作为一个损失函数,损失函数的两大特征:
(1)输出非负数
(2)当输入和期待值非常接近时,输出接近0
那么这个公式是否满足这两个条件呢?我们来分析下:
(1)因为输出a是经过sigmoid激活函数处理后的输出,所以a的取值范围为(0,1),因此lna和ln(1-a)的值必为负数。因此输
出负负为正,是非负的。
(2)假设期望的输出y=0,当实际输出a=0时,从上面公式可以得到误差接近0,同理y=1,a=1时,误差也是接近0,因此当实
际输出a和期待输出y非常相近的时候误差函数的结果也接近0. 满足条件2,所以这个公式是可以作为神经网络的损失函数。
接下来就是要证明该损失函数如何能够避免学习速率下降的问题?
老套路还是先求权重的梯度:
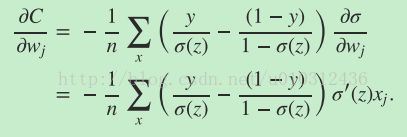
简化后:
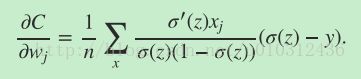
最终的梯度公式为:

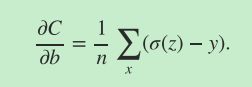
这是一个完美的表达式,这个梯度公式与激活函数对z的偏导数无关,只与激活函数作用于z后的输出与期望的输出y有关,
从这个梯度公式可以看出输出和期待的输出相差越大,梯度就越大,因此学习速率就会加快。
这就是为什么交叉嫡损失函数可以解决二次损失函数带来的学习速率慢的问题。
前面两个例子的误差速率的变化仿真结果如下:

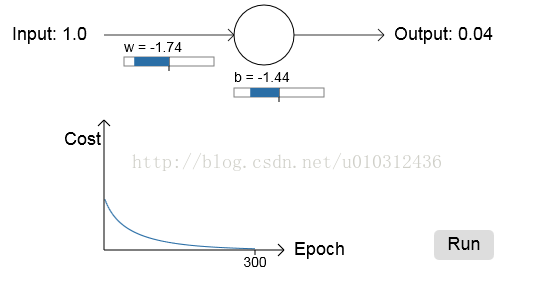
从上面两个结果对比以前用二次型作为损失函数的结果,发现误差变化速度确实变快了。
基本上是翻译了原文。
引文原文请参考:
http://neuralnetworksanddeeplearning.com/chap3.html