Datacamp 笔记&代码 Supervised Learning with scikit-learn 第二章 Regression
更多原始数据文档和JupyterNotebook
Github: https://github.com/JinnyR/Datacamp_DataScienceTrack_Python
Datacamp track: Data Scientist with Python - Course 21 (2)
Exercise
Importing data for supervised learning
In this chapter, you will work with Gapminder data that we have consolidated into one CSV file available in the workspace as 'gapminder.csv'. Specifically, your goal will be to use this data to predict the life expectancy in a given country based on features such as the country’s GDP, fertility rate, and population. As in Chapter 1, the dataset has been preprocessed.
Since the target variable here is quantitative, this is a regression problem. To begin, you will fit a linear regression with just one feature: 'fertility', which is the average number of children a woman in a given country gives birth to. In later exercises, you will use all the features to build regression models.
Before that, however, you need to import the data and get it into the form needed by scikit-learn. This involves creating feature and target variable arrays. Furthermore, since you are going to use only one feature to begin with, you need to do some reshaping using NumPy’s .reshape() method. Don’t worry too much about this reshaping right now, but it is something you will have to do occasionally when working with scikit-learn so it is useful to practice.
Instruction
- Import
numpyandpandasas their standard aliases. - Read the file
'gapminder.csv'into a DataFramedfusing theread_csv()function. - Create array
Xfor the'fertility'feature and arrayyfor the'life'target variable. - Reshape the arrays by using the
.reshape()method and passing in-1and1.
# Modified/Added by Jinny
fn = 'https://s3.amazonaws.com/assets.datacamp.com/production/course_2433/datasets/gapminder-clean.csv'
from urllib.request import urlretrieve
urlretrieve(fn, 'gapminder.csv')
('gapminder.csv', )
# Import numpy and pandas
import numpy as np
import pandas as pd
# Read the CSV file into a DataFrame: df
df = pd.read_csv('gapminder.csv')
# Create arrays for features and target variable
y = df['life'].values
X = df['fertility'].values
# Print the dimensions of X and y before reshaping
print("Dimensions of y before reshaping: {}".format(y.shape))
print("Dimensions of X before reshaping: {}".format(X.shape))
# Reshape X and y
y = y.reshape(-1, 1)
X = X.reshape(-1, 1)
# Print the dimensions of X and y after reshaping
print("Dimensions of y after reshaping: {}".format(y.shape))
print("Dimensions of X after reshaping: {}".format(X.shape))
Dimensions of y before reshaping: (139,)
Dimensions of X before reshaping: (139,)
Dimensions of y after reshaping: (139, 1)
Dimensions of X after reshaping: (139, 1)
Exercise
Exploring the Gapminder data
As always, it is important to explore your data before building models. On the right, we have constructed a heatmap showing the correlation between the different features of the Gapminder dataset, which has been pre-loaded into a DataFrame as df and is available for exploration in the IPython Shell. Cells that are in green show positive correlation, while cells that are in red show negative correlation. Take a moment to explore this: Which features are positively correlated with life, and which ones are negatively correlated? Does this match your intuition?
Then, in the IPython Shell, explore the DataFrame using pandas methods such as .info(), .describe(), .head().
In case you are curious, the heatmap was generated using Seaborn’s heatmap function and the following line of code, where df.corr()computes the pairwise correlation between columns:
sns.heatmap(df.corr(), square=True, cmap='RdYlGn')
Once you have a feel for the data, consider the statements below and select the one that is not true. After this, Hugo will explain the mechanics of linear regression in the next video and you will be on your way building regression models!
Instruction
-
Possible Answers
- The DataFrame has
139samples (or rows) and9columns. lifeandfertilityare negatively correlated.- The mean of
lifeis69.602878 fertilityis of typeint64.GDPandlifeare positively correlated.
- The DataFrame has
# Modified/Added by Jinny
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
from urllib.request import urlretrieve
fn = 'https://s3.amazonaws.com/assets.datacamp.com/production/course_2433/datasets/gapminder-clean.csv'
urlretrieve(fn, 'gapminder.csv')
df = pd.read_csv('gapminder.csv')
sns.heatmap(df.corr(), square=True, cmap='RdYlGn')
plt.xticks(rotation=90)
plt.yticks(rotation=0)
plt.show()

df.info()
RangeIndex: 139 entries, 0 to 138
Data columns (total 9 columns):
population 139 non-null float64
fertility 139 non-null float64
HIV 139 non-null float64
CO2 139 non-null float64
BMI_male 139 non-null float64
GDP 139 non-null float64
BMI_female 139 non-null float64
life 139 non-null float64
child_mortality 139 non-null float64
dtypes: float64(9)
memory usage: 9.9 KB
df.describe()
| population | fertility | HIV | CO2 | BMI_male | GDP | BMI_female | life | child_mortality | |
|---|---|---|---|---|---|---|---|---|---|
| count | 1.390000e+02 | 139.000000 | 139.000000 | 139.000000 | 139.000000 | 139.000000 | 139.000000 | 139.000000 | 139.000000 |
| mean | 3.549977e+07 | 3.005108 | 1.915612 | 4.459874 | 24.623054 | 16638.784173 | 126.701914 | 69.602878 | 45.097122 |
| std | 1.095121e+08 | 1.615354 | 4.408974 | 6.268349 | 2.209368 | 19207.299083 | 4.471997 | 9.122189 | 45.724667 |
| min | 2.773150e+05 | 1.280000 | 0.060000 | 0.008618 | 20.397420 | 588.000000 | 117.375500 | 45.200000 | 2.700000 |
| 25% | 3.752776e+06 | 1.810000 | 0.100000 | 0.496190 | 22.448135 | 2899.000000 | 123.232200 | 62.200000 | 8.100000 |
| 50% | 9.705130e+06 | 2.410000 | 0.400000 | 2.223796 | 25.156990 | 9938.000000 | 126.519600 | 72.000000 | 24.000000 |
| 75% | 2.791973e+07 | 4.095000 | 1.300000 | 6.589156 | 26.497575 | 23278.500000 | 130.275900 | 76.850000 | 74.200000 |
| max | 1.197070e+09 | 7.590000 | 25.900000 | 48.702062 | 28.456980 | 126076.000000 | 135.492000 | 82.600000 | 192.000000 |
df.head()
| population | fertility | HIV | CO2 | BMI_male | GDP | BMI_female | life | child_mortality | |
|---|---|---|---|---|---|---|---|---|---|
| 0 | 34811059.0 | 2.73 | 0.1 | 3.328945 | 24.59620 | 12314.0 | 129.9049 | 75.3 | 29.5 |
| 1 | 19842251.0 | 6.43 | 2.0 | 1.474353 | 22.25083 | 7103.0 | 130.1247 | 58.3 | 192.0 |
| 2 | 40381860.0 | 2.24 | 0.5 | 4.785170 | 27.50170 | 14646.0 | 118.8915 | 75.5 | 15.4 |
| 3 | 2975029.0 | 1.40 | 0.1 | 1.804106 | 25.35542 | 7383.0 | 132.8108 | 72.5 | 20.0 |
| 4 | 21370348.0 | 1.96 | 0.1 | 18.016313 | 27.56373 | 41312.0 | 117.3755 | 81.5 | 5.2 |
Exercise
Fit & predict for regression
Now, you will fit a linear regression and predict life expectancy using just one feature. You saw Andy do this earlier using the 'RM' feature of the Boston housing dataset. In this exercise, you will use the 'fertility' feature of the Gapminder dataset. Since the goal is to predict life expectancy, the target variable here is 'life'. The array for the target variable has been pre-loaded as y and the array for 'fertility' has been pre-loaded as X_fertility.
A scatter plot with 'fertility' on the x-axis and 'life'on the y-axis has been generated. As you can see, there is a strongly negative correlation, so a linear regression should be able to capture this trend. Your job is to fit a linear regression and then predict the life expectancy, overxlaying these predicted values on the plot to generate a regression line. You will also compute and print the R2R2 score using sckit-learn’s .score()method.
Instruction
- Import
LinearRegressionfromsklearn.linear_model. - Create a
LinearRegressionregressor calledreg. - Set up the prediction space to range from the minimum to the maximum of
X_fertility. This has been done for you. - Fit the regressor to the data (
X_fertilityandy) and compute its predictions using the.predict()method and theprediction_spacearray. - Compute and print the R2R2 score using the
.score()method. - Overlay the plot with your linear regression line. This has been done for you, so hit ‘Submit Answer’ to see the result!
# modified/added by Jinny
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
plt.style.use('ggplot')
df = pd.read_csv('https://s3.amazonaws.com/assets.datacamp.com/production/course_2433/datasets/gapminder-clean.csv')
y = df['life'].values
X = df.drop('life', axis=1)
# Reshape to 1-D
y = y.reshape(-1, 1)
X_fertility = X['fertility'].values.reshape(-1, 1)
_ = plt.scatter(X['fertility'], y, color='blue')
_ = plt.ylabel('Life Expectancy')
_ = plt.xlabel('Fertility')
# -----------------------
# Import LinearRegression
from sklearn.linear_model import LinearRegression
# Create the regressor: reg
reg = LinearRegression()
# Create the prediction space
prediction_space = np.linspace(min(X_fertility), max(X_fertility)).reshape(-1,1)
# Fit the model to the data
reg.fit(X_fertility, y)
# Compute predictions over the prediction space: y_pred
y_pred = reg.predict(prediction_space)
# Print R^2
print(reg.score(X_fertility, y))
# Plot regression line
plt.plot(prediction_space, y_pred, color='black', linewidth=3)
plt.show()
0.6192442167740035

Exercise
Train/test split for regression
As you learned in Chapter 1, train and test sets are vital to ensure that your supervised learning model is able to generalize well to new data. This was true for classification models, and is equally true for linear regression models.
In this exercise, you will split the Gapminder dataset into training and testing sets, and then fit and predict a linear regression over all features. In addition to computing the R2R2score, you will also compute the Root Mean Squared Error (RMSE), which is another commonly used metric to evaluate regression models. The feature array X and target variable array y have been pre-loaded for you from the DataFrame df.
Instruction
- Import
LinearRegressionfromsklearn.linear_model,mean_squared_errorfromsklearn.metrics, andtrain_test_splitfromsklearn.model_selection. - Using
Xandy, create training and test sets such that 30% is used for testing and 70% for training. Use a random state of42. - Create a linear regression regressor called
reg_all, fit it to the training set, and evaluate it on the test set. - Compute and print the R2R2 score using the
.score()method on the test set. - Compute and print the RMSE. To do this, first compute the Mean Squared Error using the
mean_squared_error()function with the argumentsy_testandy_pred, and then take its square root usingnp.sqrt().
# Import necessary modules
from sklearn.linear_model import LinearRegression
from sklearn.metrics import mean_squared_error
from sklearn.model_selection import train_test_split
# Create training and test sets
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size = 0.3, random_state=42)
# Create the regressor: reg_all
reg_all = LinearRegression()
# Fit the regressor to the training data
reg_all.fit(X_train, y_train)
# Predict on the test data: y_pred
y_pred = reg_all.predict(X_test)
# Compute and print R^2 and RMSE
print("R^2: {}".format(reg_all.score(X_test, y_test)))
rmse = np.sqrt(mean_squared_error(y_test, y_pred))
print("Root Mean Squared Error: {}".format(rmse))
R^2: 0.8380468731430133
Root Mean Squared Error: 3.2476010800369477
Exercise
5-fold cross-validation
Cross-validation is a vital step in evaluating a model. It maximizes the amount of data that is used to train the model, as during the course of training, the model is not only trained, but also tested on all of the available data.
In this exercise, you will practice 5-fold cross validation on the Gapminder data. By default, scikit-learn’s cross_val_score() function uses R2R2 as the metric of choice for regression. Since you are performing 5-fold cross-validation, the function will return 5 scores. Your job is to compute these 5 scores and then take their average.
The DataFrame has been loaded as df and split into the feature/target variable arrays X and y. The modules pandas and numpy have been imported as pd and np, respectively.
Instruction
- Import
LinearRegressionfromsklearn.linear_modelandcross_val_scorefromsklearn.model_selection. - Create a linear regression regressor called
reg. - Use the
cross_val_score()function to perform 5-fold cross-validation onXandy. - Compute and print the average cross-validation score. You can use NumPy’s
mean()function to compute the average.
# Import the necessary modules
from sklearn.linear_model import LinearRegression
from sklearn.model_selection import cross_val_score
# Create a linear regression object: reg
reg = LinearRegression()
# Compute 5-fold cross-validation scores: cv_scores
cv_scores = cross_val_score(reg, X, y, cv=5)
# Print the 5-fold cross-validation scores
print(cv_scores)
print("Average 5-Fold CV Score: {}".format(np.mean(cv_scores)))
[0.81720569 0.82917058 0.90214134 0.80633989 0.94495637]
Average 5-Fold CV Score: 0.859962772279345
Exercise
K-Fold CV comparison
Cross validation is essential but do not forget that the more folds you use, the more computationally expensive cross-validation becomes. In this exercise, you will explore this for yourself. Your job is to perform 3-fold cross-validation and then 10-fold cross-validation on the Gapminder dataset.
In the IPython Shell, you can use %timeit to see how long each 3-fold CV takes compared to 10-fold CV by executing the following cv=3 and cv=10:
%timeit cross_val_score(reg, X, y, cv = ____)
pandas and numpy are available in the workspace as pdand np. The DataFrame has been loaded as df and the feature/target variable arrays X and y have been created.
Instruction
- Import
LinearRegressionfromsklearn.linear_modelandcross_val_scorefromsklearn.model_selection. - Create a linear regression regressor called
reg. - Perform 3-fold CV and then 10-fold CV. Compare the resulting mean scores.
# Import necessary modules
from sklearn.linear_model import LinearRegression
from sklearn.model_selection import cross_val_score
# Create a linear regression object: reg
reg = LinearRegression()
# Perform 3-fold CV
cvscores_3 = cross_val_score(reg, X, y, cv=3)
print(np.mean(cvscores_3))
# Perform 10-fold CV
cvscores_10 = cross_val_score(reg, X, y, cv=10)
print(np.mean(cvscores_10))
0.8718712782622262
0.8436128620131267
Exercise
Regularization I: Lasso
In the video, you saw how Lasso selected out the 'RM'feature as being the most important for predicting Boston house prices, while shrinking the coefficients of certain other features to 0. Its ability to perform feature selection in this way becomes even more useful when you are dealing with data involving thousands of features.
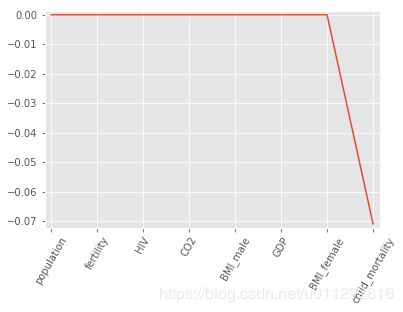
In this exercise, you will fit a lasso regression to the Gapminder data you have been working with and plot the coefficients. Just as with the Boston data, you will find that the coefficients of some features are shrunk to 0, with only the most important ones remaining.
The feature and target variable arrays have been pre-loaded as X and y.
Instruction
- Import
Lassofromsklearn.linear_model. - Instantiate a Lasso regressor with an alpha of
0.4and specifynormalize=True. - Fit the regressor to the data and compute the coefficients using the
coef_attribute. - Plot the coefficients on the y-axis and column names on the x-axis. This has been done for you, so hit ‘Submit Answer’ to view the plot!
# modified/added by Jinny
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
plt.style.use('ggplot')
df = pd.read_csv('https://s3.amazonaws.com/assets.datacamp.com/production/course_2433/datasets/gapminder-clean.csv')
y = df['life'].values
X = df.drop('life', axis=1).values
df_columns = df.drop('life', axis=1).columns
# -----------------------------------
# Import Lasso
from sklearn.linear_model import Lasso
# Instantiate a lasso regressor: lasso
lasso = Lasso(alpha=0.4, normalize=True)
# Fit the regressor to the data
lasso.fit(X, y)
# Compute and print the coefficients
lasso_coef = lasso.coef_
print(lasso_coef)
# Plot the coefficients
plt.plot(range(len(df_columns)), lasso_coef)
plt.xticks(range(len(df_columns)), df_columns.values, rotation=60)
plt.margins(0.02)
plt.show()
[-0. -0. -0. 0. 0. 0.
-0. -0.07087587]
Exercise
Regularization II: Ridge
Lasso is great for feature selection, but when building regression models, Ridge regression should be your first choice.
Recall that lasso performs regularization by adding to the loss function a penalty term of the absolute value of each coefficient multiplied by some alpha. This is also known as L1L1regularization because the regularization term is the L1L1 norm of the coefficients. This is not the only way to regularize, however.
If instead you took the sum of the squared values of the coefficients multiplied by some alpha - like in Ridge regression - you would be computing the L2L2 norm. In this exercise, you will practice fitting ridge regression models over a range of different alphas, and plot cross-validated R2R2 scores for each, using this function that we have defined for you, which plots the R2R2 score as well as standard error for each alpha:
def display_plot(cv_scores, cv_scores_std):
fig = plt.figure()
ax = fig.add_subplot(1,1,1)
ax.plot(alpha_space, cv_scores)
std_error = cv_scores_std / np.sqrt(10)
ax.fill_between(alpha_space, cv_scores + std_error, cv_scores - std_error, alpha=0.2)
ax.set_ylabel('CV Score +/- Std Error')
ax.set_xlabel('Alpha')
ax.axhline(np.max(cv_scores), linestyle='--', color='.5')
ax.set_xlim([alpha_space[0], alpha_space[-1]])
ax.set_xscale('log')
plt.show()
Don’t worry about the specifics of the above function works. The motivation behind this exercise is for you to see how the R2R2score varies with different alphas, and to understand the importance of selecting the right value for alpha. You’ll learn how to tune alpha in the next chapter.
Instruction
- Instantiate a Ridge regressor and specify
normalize=True. - Inside the
forloop:- Specify the alpha value for the regressor to use.
- Perform 10-fold cross-validation on the regressor with the specified alpha. The data is available in the arrays
Xandy. - Append the average and the standard deviation of the computed cross-validated scores. NumPy has been pre-imported for you as
np.
- Use the
display_plot()function to visualize the scores and standard deviations.
def display_plot(cv_scores, cv_scores_std):
fig = plt.figure()
ax = fig.add_subplot(1,1,1)
ax.plot(alpha_space, cv_scores)
std_error = cv_scores_std / np.sqrt(10)
ax.fill_between(alpha_space, cv_scores + std_error, cv_scores - std_error, alpha=0.2)
ax.set_ylabel('CV Score +/- Std Error')
ax.set_xlabel('Alpha')
ax.axhline(np.max(cv_scores), linestyle='--', color='.5')
ax.set_xlim([alpha_space[0], alpha_space[-1]])
ax.set_xscale('log')
plt.show()
# Import necessary modules
from sklearn.linear_model import Ridge
from sklearn.model_selection import cross_val_score
# Setup the array of alphas and lists to store scores
alpha_space = np.logspace(-4, 0, 50)
ridge_scores = []
ridge_scores_std = []
# Create a ridge regressor: ridge
ridge = Ridge(normalize=True)
# Compute scores over range of alphas
for alpha in alpha_space:
# Specify the alpha value to use: ridge.alpha
ridge.alpha = alpha
# Perform 10-fold CV: ridge_cv_scores
ridge_cv_scores = cross_val_score(ridge, X, y, cv=10)
# Append the mean of ridge_cv_scores to ridge_scores
ridge_scores.append(np.mean(ridge_cv_scores))
# Append the std of ridge_cv_scores to ridge_scores_std
ridge_scores_std.append(np.std(ridge_cv_scores))
# Display the plot
display_plot(ridge_scores, ridge_scores_std)
